本文作者:i春秋签约作家——阿甫哥哥
系列文章专辑:https://bbs.ichunqiu.com/forum.php?mod=collection&action=view&ctid=137
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款针对网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别针对网络空间中的设备及网站, 通过 24 小时不间断的探测、识别,标识出互联网设备及网站所使用的服务及组件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获取access_token
#-*- coding: UTF-8 -*-import requests
import jsonuser = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')def Login():data_info = {'username' : user,'password' : passwd}data_encoded = json.dumps(data_info) respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)try:r_decoded = json.loads(respond.text) access_token = r_decoded['access_token']except KeyError:return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'return access_token
if __name__ == '__main__':print Login() 然后,API手册是这么写的,根据这个,咱们先写一个HOST的单页面采集的….
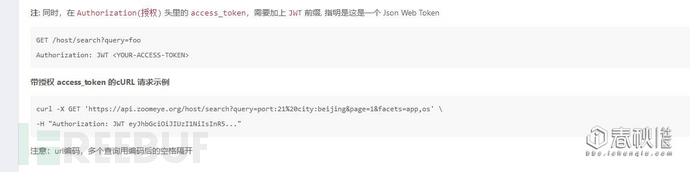
#-*- coding: UTF-8 -*-import requests
import jsonuser = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')def Login():data_info = {'username' : user,'password' : passwd}data_encoded = json.dumps(data_info) respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)try:r_decoded = json.loads(respond.text) access_token = r_decoded['access_token']except KeyError:return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'return access_token
def search():headers = {'Authorization': 'JWT ' + Login()}r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',headers = headers)response = json.loads(r.text)print response
if __name__ == '__main__':search() 返回的信息量极大啊,但它也是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着你们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-import requests
import jsondef Login():data_info = {'username' : user,'password' : passwd}data_encoded = json.dumps(data_info) respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)try:r_decoded = json.loads(respond.text) access_token = r_decoded['access_token']except KeyError:return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'return access_token
def search():headers = {'Authorization': 'JWT ' + Login()}for i in range(1,int(PAGECOUNT)):r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),headers = headers)response = json.loads(r.text)for x in response['matches']:print x['ip']
if __name__ == '__main__':user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')search() 这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-import requests
import jsondef Login(user,passwd):data_info = {'username' : user,'password' : passwd}data_encoded = json.dumps(data_info) respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)try:r_decoded = json.loads(respond.text) access_token = r_decoded['access_token']except KeyError:return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):headers = {'Authorization': 'JWT ' + Login(user,passwd)}for i in range(1,int(PAGECOUNT)):r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),headers = headers)response = json.loads(r.text)try:if queryType == "host":for x in response['matches']:print x['ip']if queryType == "web":for x in response['matches']:print x['ip'][0]except KeyError:print "[ERROR] No hosts found"def main():print " _____ _____ ____ " print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __" print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"print " |___/ "user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')Login(user,passwd)search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':main() 0×03 ShoDanAPI脚本编写
Shodan是互联网上最可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然目前人们都认为谷歌是最强劲的搜索引擎,但Shodan才是互联网上最可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接进入互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻找着所有和互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大约5亿个服务器上日夜不停地搜集信息。
Shodan所搜集到的信息是极其惊人的。凡是链接到互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥和控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有和互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全防御措施,其可以随意进入。
浅安dalao写过,介绍的也很详细…..
地址传送门:基于ShodanApi接口的调用python版
先说基于API查询。。。官方文档:http://shodan.readthedocs.io/en/latest/tutorial.html
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他跟Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import jsondef getip():API_KEY = *************url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}req = requests.get(url=url,headers=headers)content = json.loads(req.text)for i in content['matches']:print i['ip_str']
if __name__ == '__main__':getip() 接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我懒得写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:print 'Search Method:Input the %s and then the keyword' % sys.argv[0]sys.exit()
try:api = shodan.Shodan(API_KEY)query = ' '.join(sys.argv[1:])print "You Search is:" + queryresult = api.count(query, facets=FACETS) # 使用count比search快for facet in result['facets']:print FACET_TITLES[facet]for key in result['facets'][facet]:countrie = '%s : %s' % (key['value'], key['count'])print countriewith open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:f.write(countrie +"\n")f.close()print " "print "save is coutures.txt" print "Search is Complete."
except Exception, e:print 'Error: %s' % e 0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'html = requests.get(url=url,headers=headers,timeout=5)soup = bs(html.content, 'lxml', from_encoding='utf-8')bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})for i in bqs:r = requests.get(i['href'], headers=headers, timeout=5)print r.url
if __name__ == '__main__':getfromBaidu('阿甫哥哥') 然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}for k in range(0,(pageout-1)*10,10):url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)html = requests.get(url=url,headers=headers,timeout=5)soup = bs(html.content, 'lxml', from_encoding='utf-8')bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})for i in bqs:r = requests.get(i['href'], headers=headers, timeout=5)print r.url
if __name__ == '__main__':getfromBaidu('阿甫哥哥',10) 
0×05 【彩蛋篇】论坛自动签到脚本
之前其实贴出来了,只是怕有些人没看到….在分享一次….
签到可以获取大量魔法币….他的多种获取方法,请戳:
https://bbs.ichunqiu.com/thread-36007-1-1.html
实现方法只需要将COOKIE修改为你的即可
实现功能是每天24点自动签到…挂在服务器上即可….
#-*- coding: UTF-8 -*-
import requests
import datetime
import time
import re
def sign():url = 'https://bbs.ichunqiu.com/plugin.php?id=dsu_paulsign:sign'cookie = {'__jsluid':'3e29e6c**********8966d9e0a481220',' UM_distinctid':'1605f635c78159************016-5d4e211f-1fa400-1605f635c7ac0',' pgv_pvi':'4680553472',******...........}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}r = requests.get(url=url,cookies=cookie,headers=headers)rows = re.findall(r'<input type=\"hidden\" name=\"formhash\" value=\"(.*?)\" />', r.content)if len(rows)!=0:formhash = rows[0]print '[-]Formhash is: ' + formhashelse:print '[-]None formhash!'if '您今天已经签到过了或者签到时间还未开始' in r.text:print '[-]Already signed!!'else:sign_url = 'https://bbs.ichunqiu.com/plugin.php?id=dsu_paulsign:sign&operation=qiandao&infloat=1&inajax=1'sign_payload = {'formhash':formhash,'qdxq':'fd','qdmode':'2','todaysay':'','fastreply':0,}sign_req = requests.post(url=sign_url,data=sign_payload,headers=headers,cookies=cookie)if '签到成功' in sign_req.text:print '[-]Sign success!!'else:print '[-]Something error...'time.sleep(60)
def main(h=0, m=0):while True:while True:now = datetime.datetime.now()if now.hour==h and now.minute==m:breaktime.sleep(20)sign()
if __name__ == '__main__':main() >>>>>> 黑客入门必备技能 带你入坑和逗比表哥们一起聊聊黑客的事儿,他们说高精尖的技术比农药都好玩~