郑州中企业网站建设/找相似图片 识别
scikit-learn中超参数搜索之网格搜索(GridSearchCV)
为了能够让我们的模型取得更好的性能,往往有很多超参数需要调。sklearn中主要提供了两种搜索超参数的方法,一种是网格搜索GridSearchCV,另一种是随机搜索RandomizedSearchCV,这两种搜索方式的区别主要是网格搜索会穷举遍历所有参数组合,自然速度上会慢些。而随机搜索则是从分布中随机采样,并不遍历所有参数组合。这篇博客主要介绍 网格搜索GridSearchCV。
GridSearchCV的官方文档连接为:GridSearchCV API文档,我们先来看看一些主要的参数:
| 参数 | 描述 |
|---|---|
| estimator | 要搜索超参数的分类器 |
| param_grid | 用于搜索的参数组合,字典类型。这里有个注意点,就是字典的key必须和estimator里的参数名字保持一致,比如estimate用的svm,要调svm的参数gamma,那么param_grid里的key就必须用gamma;如果用了管道(pipeline),管道里的estimator对应的key为’svc’,那么param_grid里的可以就应该为:svc__gamma,用__来分隔,具体例子见下面。 |
| n_jobs | 搜索的时候并发度,比如n_jobs=1表示只用到一个cpu核心,n_jobs=2用到两个cpu核心,n_jobs=-1表示用到机器上的所有核心(这个和机器相关),默认为1,即只使用一个CPU核心 |
| cv | 交叉验证折数,比如cv=5,则搜索的时候每个参数组合的模型性能是由五折交叉验证算出来的均值 |
| refit | 这个参数很重要,一般要设置为true,因为这样当搜索出最佳参数后,会自动用这个最佳参数拟合出一个模型 |
| scoring | 搜索时模型性能的评价准则,默认为None,None则使用estimator的默认评价准备。也可以自己设置,比如scoring=‘roc_auc’ |
| verbose | 日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。 |
GridSearchCV常用的方法主要有两个:
- best_score_:搜索期间最好的模型性能
- best_params_:得到的最佳参数
下面主要来看下怎么用,我们就拿sklearn中的digits数据集来举例,假设分类器就用svm,svm中如果我们核函数用的高斯核函数,那么有两个参数可以调参,分别是高斯核函数中的gamma和svm中的惩罚系数C。
关于这两个参数的作用,这里稍微提一下,当gamma比较小时,限制就比较严格,单个样本对超平面的影响比较小,不容易被选为支持向量,因此cannot capture the complexity or “shape” of the data,而当gamma较大时,单个样本对超平面的影响比较大,更容易被选为支持向量,支持向量多的话能够拟合出比较复杂的数据分布。C为惩罚系数,如果过大,会导致过拟合,如果过小会欠拟合。
下面直接上代码:
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
X, y = load_digits(return_X_y = True)
parameters = {'gamma': [0.001, 0.01, 0.1, 1], 'C':[0.001, 0.01, 0.1, 1,10]}
#n_jobs =-1使用全部CPU并行多线程搜索
gs = GridSearchCV(SVC(), parameters, refit = True, cv = 5, verbose = 1, n_jobs = -1)
gs.fit(X,y) #Run fit with all sets of parameters.
print('最优参数: ',gs.best_params_)
print('最佳性能: ', gs.best_score_)
下面是结果:

能够看出整个搜索共用时8.7秒,如果只是用一个线程来看看需要用多久:
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
X, y = load_digits(return_X_y = True)
parameters = {'gamma': [0.001, 0.01, 0.1, 1], 'C':[0.001, 0.01, 0.1, 1,10]}
gs = GridSearchCV(SVC(), parameters, refit = True, cv = 5, verbose = 1, n_jobs = 1)
gs.fit(X,y) #Run fit with all sets of parameters.
print('最优参数: ',gs.best_params_)
print('最佳性能: ', gs.best_score_)

对比太过明显,因为枚举全部组合本就是个费时操作,所以大家还是多线程并行搜索吧,记住,只需把参数n_jobs设置为-1即可。
到目前为止,似乎我们已经掌握了如何使用GridSearchCV如何搜索最优参数了。但是还有个更高级的方式想分享下。我们先来看看我们使用的digits数据集的信息(https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits)
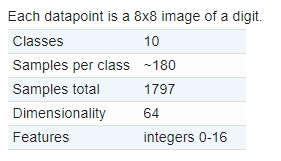
每个特征的范围为0-16,我们自然想对特征值先标准化一下,然后在训练模型,所以可以不假思索的写出如下代码:
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScalerX, y = load_digits(return_X_y = True)
parameters = {'gamma': [0.001, 0.01, 0.1, 1], 'C':[0.001, 0.01, 0.1, 1,10]}
gs = GridSearchCV(SVC(), parameters, refit = True, cv = 5, verbose = 1, n_jobs = -1)
ss = StandardScaler()
ss_X = ss.fit_transform(X)
gs.fit(ss_X,y) #Run fit with all sets of parameters.
print('最优参数: ',gs.best_params_)
print('最佳性能: ', gs.best_score_)
但是,很遗憾,上面的代码是错的,为什么?我们对比下下面两种操作,第一种先划分再在训练集上使用fit_transform,然后在对测试集用transform是正确的。但第二种方法先对所有样本标准化再划分则是错误的。举个例子说明这个问题:假设我们的样本中有异常值,而这些异常值被划分到了测试集中,那么第一种方法,异常值对均值和方差没有任何影响。而第二种方法要先计算所有样本的均值和方差,则异常值产生了影响。第二种方法会造成类似过拟合的现象,在测试集上准确率也显得很高,但是如果换做其他测试样本,那么泛化性能将差的多。
#correct method
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.25, random_state = 1)
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)#wrong method
ss = StandardScaler()
X = ss.fit_transform(X)
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.25, random_state = 1)
那么我们改如何把preprocessing方法和交叉验证一起使用呢,sklearn中的Pipeline要出场了,没错就是流水线,我们完全可以把特征标准化和训练模型看成一个流水。因此代码变为:
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import PipelineX, y = load_digits(return_X_y = True)
#因为gamma和C是SVC中的参数,在pipeline中SVC对应的key为svc,所以参数的key应该为svc__gamma和svc__C,用__来分阁
parameters = {'svc__gamma': [0.001, 0.01, 0.1, 1], 'svc__C':[0.001, 0.01, 0.1, 1,10]}
clf = Pipeline([('ss',StandardScaler()), ('svc', SVC())])
gs = GridSearchCV(clf, parameters, refit = True, cv = 5, verbose = 1, n_jobs = -1)
gs.fit(X,y) #Run fit with all sets of parameters.
print('最优参数: ',gs.best_params_)
print('最佳性能: ', gs.best_score_)
这个代码的执行过程如下:
- Step 1: The data are split into TRAINING data and TEST data according to the cv parameter that you specified in the GridSearchCV.
- Step 2: the scaler is fitted on the TRAINING data
- Step 3: the scaler transforms TRAINING data
- Step 4: the models are fitted/trained using the transformed TRAINING data
- Step 5: the scaler is used to transform the TEST data
- Step 6: the trained models predict using the transformed TEST data
这样就避免了上面的先对所有样本标准化然后再划分训练集和测试集的错误之处。
[1] https://stats.stackexchange.com/questions/267012/difference-between-preprocessing-train-and-test-set-before-and-after-splitting
[2] https://stackoverflow.com/questions/51459406/apply-standardscaler-in-pipeline-in-scikit-learn-sklearn
[3] https://zhuanlan.zhihu.com/p/42297868
[4] 范淼等《python机器学习及实践》