我想给别人做网站/独立站优化
目录
1.交叉融合和多次召回
2.聚类
3.胶囊网络
4.序列召回
5.Encoder
6.Attention机制
7.按类别召回
8.Multi-Tag
9.双塔模型MOE和MMOE
10.多模态特征
目前已经实现过的多兴趣模型主要有:
一、交叉融合和多次召回
在我们以往实现的视频推荐过程中,最常用的推荐策略有协同过滤、embedding、youtubeDNN-Net、FM等,但归根结底,可以分为item2item的召回和user2item的召回,都是根据用户当前观看视频的特征信息或者用户本身的特征信息来进行召回。这样做的好处在于可以对用户当前的兴趣做及时的反馈,但是用户的兴趣是多样的,这种召回结果局限在一个类别范围下,且这种召回策略扩展性较差、容易越推越窄,使得候选池中的视频头部效应越来越明显。
为了解决这一问题,我们开始尝试实现针对用户长短期观影历史的多兴趣召回策略。首先想到的最直接的想法就是对用户观影历史中的每一个item都做召回,然后再进行交叉融合。
具体的上线策略上,笔者在FM实时召回中用了trigger交叉融合的方法,youtubeNet用了每次截断末位视频后在faiss中取最近邻搜索结果再交叉排序的方法,两种策略均有明显的正向效果。
二、聚类
用户的观影序列往往涉及多个类别多个主题,对观影历史中的视频进行聚类,就能大致得到用户的多个兴趣,再根据每一个兴趣分别召回视频。
聚类的方法有很多,笔者只实验了k-means和层次聚类两种算法,聚类的依据是视频的隐向量,隐向量的是通过item2vec、youtubeDNN等模型训练得到的,具体的算法原理和实现代码如下:
从线上效果上来看,层次聚类的方法对点击率有明显的正向效果,而k-means没有提升效果。原因可能是因为k-means限制了用户的兴趣数量为确定值,而层次聚类是根据阈值来截断的,并没有对兴趣的数目做限制,这样的聚类方法与实际更符合,更能适应不同用户的需求。
爱奇艺的PinnerSage 聚类多兴趣召回,本质上就是Pinsage模型+层次聚类,笔者对PinnerSage模型做了复现,线上效果也是正向的。
三、胶囊网络
胶囊网络最初是为了解决计算机视觉的相关课题,但用在推荐领域,刚好与多兴趣召回的应用场景匹配。这里主要涉及了MIND和ComiRec两个模型。
1.胶囊网络原理:
胶囊网络的核心思想就是“输出是输入的某种聚类的结果”, 从上向下看,Capsule就是每个底层特征 v 分别做分类,然后将分类结果累加整合,而分类问题就是内积后做softmax:

其中,squash函数是为了实现特征压缩,使得胶囊的模长能够代表这个特征的概率:

Capsule网络相比于深度神经网络更具有可解释性,(深度神经网络有效的原因在于,通过层层叠加完成了对输入的层层抽象,实际上模拟了人的层次分类的做法)
相关概念定义:
(1)一个胶囊是一组神经元(「输入」),即神经元「向量」(activity vector),表示特定类型的实体(例如对象或对象部分)的实例化参数(例如可能性、方向等)。
(2)「使用胶囊的长度(模)来表示实体(例如上述的眼睛、鼻子等)存在的概率」,并使用其方向(orientation)来表示除了长度以外的其他实例化参数,例如位置、角度、大小等。
(3)胶囊的「向量输出」的长度(模长)不能超过1,可以通过应用一个「非线性函数」使其在方向不变的基础上,缩小其大小
2.动态路由原理:
为了求Vj,需要求softmax,而求softmax又需要知道Vj,这里就需要迭代的思想来求解。一开始先让Vj全部等于Ui的均值,然后反复迭代。这个迭代的算法即是“动态路由”:

Vj是以输入Ui的某种聚类中心出现的, 而从不同角度看输入,得到的聚类结果显然是不一样的。那么为了实现“多角度看特征”,于是可以在每个胶囊传入下一个胶囊之前,都要先乘上一个矩阵做变换,即:

U_ji相当于单个胶囊的个人预测,v_j是所有胶囊共同作用的结果,所以向量积的大小代表了该胶囊对最终结果的一致程度,也就是耦合程度,如果向量积为负,耦合程度应该变小,如果向量积为正,耦合程度应该变大,这个更新公式正好实现,也就是原论文伪代码最后一行对应的公式。
但由于全连接层只能处理定长输入,而输入数目却是不固定的,所以需要想CNN那样的共现网络,所有底层胶囊的连接的变换矩阵是共用的,即Wji=Wj。从下向上看,就是所有输入向量经过同一个矩阵映射后,完成聚类输出,重复这个过程几次,就输出几个向量,即为几个胶囊。而从上向下看,可以将每个变换矩阵堪称是上层胶囊的识别器,上层胶囊通过这个矩阵来识别出底层胶囊是否有这个特征。
最后,通过构建一个loss函数,来实现反向传播,训练网络参数。
间隔损失:Margin Loss:
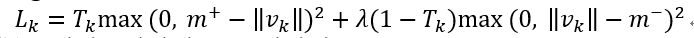
Tk表示k类是否存在,存在为1,不存在为0
m+ 为0.9,惩罚假阳性,k类存在但是预测不存在会导致损失函数很大
m− 为0.1,惩罚假阴性,k类不存在但是预测存在,会导致损失函数很大
重构损失:
由两部分组成,第一部分是间隔损失,第二部分是用原图片的28×28个像素减去重构的28×28个像素然后取平方和然后乘0.005,间隔损失占主要地位。
整体网络结构分为四部分:输入层、卷积层、主胶囊层、数字胶囊层:
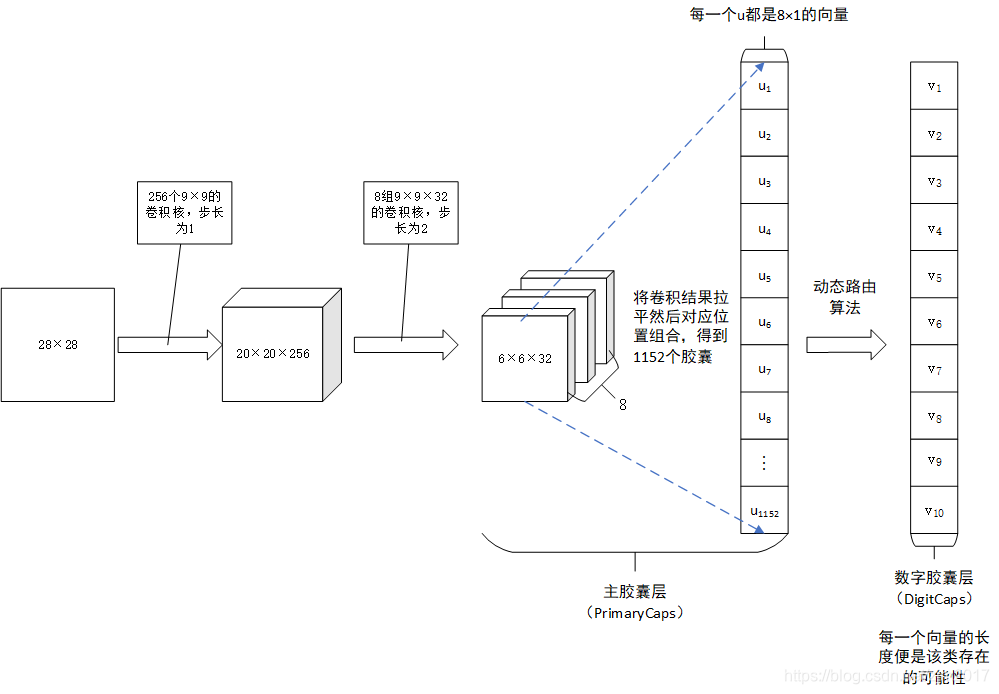
动态路由算法的整个过程:
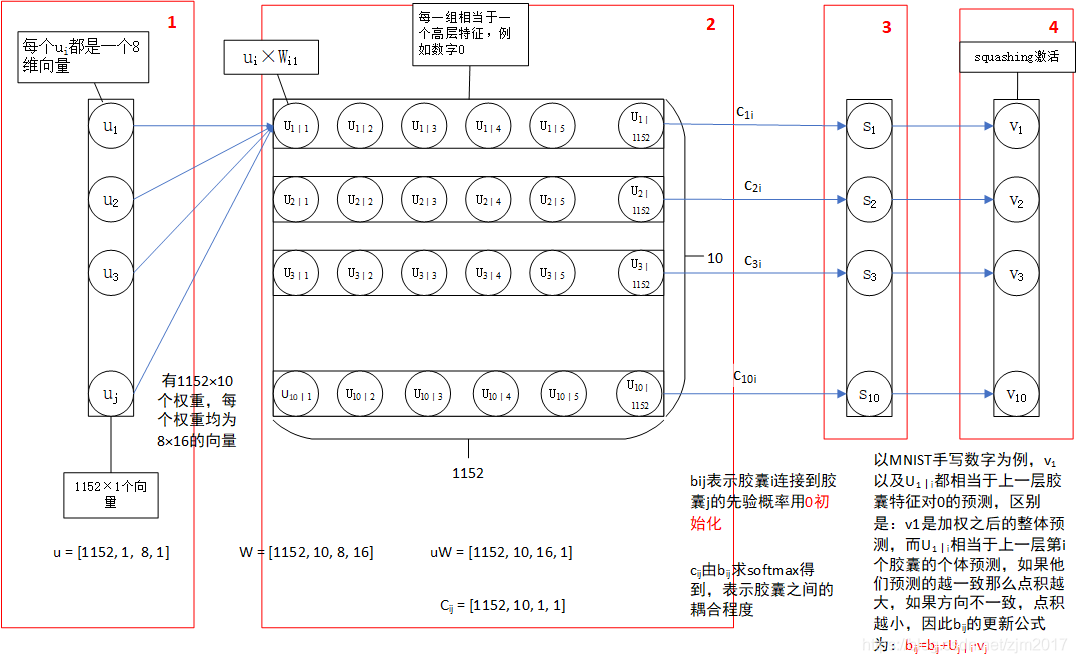
红框1:主胶囊层的结果,得到1152个胶囊(向量神经元)
红框2:一个全连接结构,一共10行,每行相当于1152个胶囊对该类别的贡献,对应于原论文公式2
红框3:c_ij是b_ij通过softmax得到,加权时候每行相加就得到s_i
红框4:向量压缩结果,通过squashing函数将模长压缩到0-1之间,对应原论文公式1
以上四步是动态路由前向传播,下图中蓝色向量代表红框2中的某一行胶囊的部分向量,红色箭头代表s_i,也就是最终所有向量共同作用的结果。
3.与传统神经网络的对比:
-
Capsule Network的输入输出都是向量了,而非传统网络的标量。
- 上一层传入后,Capsule Network需要做一下仿射变换(Affine Transformation),提供不同的观察角度,而传统神经网络并没有这回事。
- Capsule Network的非线性激活使用的是squash函数,而传统的神经网络是ReLU, tanh, sigmoid等。
4.改进方向:
- squash 函数,存在的必要存疑,以及对该函数本身的改进
- 动态路由,现在实际上是给了一个框,这个“路由”实际上是一个聚类,现在已经有了用EM做动态路由了
- 现有动态路由中有
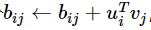 但这样会使得迭代轮数也成为超参数,是否应该改为
但这样会使得迭代轮数也成为超参数,是否应该改为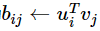 ,变成迭代轮数越大越好
,变成迭代轮数越大越好 - 神经元原先是一个标量,现在用向量表示,可不可以用矩阵,n维张量表示?
5.self-attention 原理:
权重向量的计算公式:![]()
为了利用用户序列的顺序信息,加入了可训练的位置embedding,将w2扩展。
通过attention矩阵聚合用户序列,得到Vu:![]()
模型训练通过找到和目标item最接近的兴趣向量Vu,然后用softmax计算出目标item的概率,最后累加logloss,由于复例数量庞大,论文进行了采样处理:
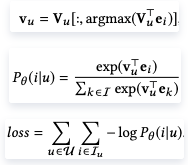
在获得多个兴趣向量后,每一个都可以通过ANN检索出topN个item,聚合时按点积排序可以提高准确率,但考虑到多样性,需要最大化Q值:![]()
6.与MIND对比:
MIND模型的流程:
MIND模型的输入为用户相关的特征,输出是多个用户表征向量,主要用于召回阶段使用。输入的特征主要包括三部分,即用户自身相关特征、用户行为特征(如浏览过的商品id)和label特征。所有的id类特征都经过Embedding层,其中对于用户行为特征对应的Embedding向量进行average pooling操作,然后将用户行为Embedidng向量传递给Multi-Interest Extract layer(生成interest capsules),将生成的interest capsules与用户本身的Embedding concate起来经过几层全连接网络,就得到了多个用户表征向量,在模型的最后有一个label-aware attention层。在线上使用的时候同样应该采用类似向量化召回的思路,选取TopN。
MIND提出了一种Behavior-to-Interest (B2I)动态路由,用于自适应地将用户的行为聚合为兴趣表示向量。
动态路由这部分,Comirec是原始动态路由,MIND对于b这个参数不是增量更新的。而且MIND最后有个MLP和Lable aware attention让模型变得更深了,学的更深的话可能导致上层兴趣embedding学的不好。
7.核心代码解析:
8.优缺点及线上效果:
4.序列召回
MIMN模型、SIM模型、SDM模型,初衷是为了解决以往序列模型对于长期观影序列信息的数据损失问题,同时它们也能从序列中提取到用户长短期兴趣,进行召回。
详见 推荐系统——召回策略中的融合_码一码码码的博客-CSDN博客
5.Encoder
PolyEncoder模型代表的是seqcense2vec序列召回这类方法,这类模型摆脱了原来item2item点对点召回的单一性,也解决了交叉融合对于观影序列内部item之间的联系的信息损失,转而在训练过程中就把关联信息引入。
6.Attention机制
Attention机制应该是最近相当热门的研究方向,它的初衷是使序列中与key有关的部分拥有更大的权重,同时降低与key相关性较小的item对推荐结果的影响力。
7.按类别召回
对用户观影序列中的视频,按照一级类或聚类标签进行分类,得到用户的多个兴趣表达,针对每个兴趣,分别召回视频,然后再融合。
8.Multi-Tag
通过计算共现矩阵得到LLR相似度的方式或word2vec得到embedding相似度的方式,得到标签之间的相似关系,取topK个相似标签,作为新的trigger,联合召回。即通过人工特征交叉的方式,实现了特征联合召回。
9.双塔模型MOE和MMOE
详见 推荐系统——排序算法综述_码一码码码的博客-CSDN博客
10.多模态特征
详见 推荐系统——召回策略中的融合_码一码码码的博客-CSDN博客
参考文献:
【1】千人万面奇妙自见:爱奇艺短视频推荐技术中多兴趣召回技术的演变
【2】揭开迷雾,来一顿美味的Capsule盛宴 - 科学空间|Scientific Spaces