律师网站建设哪家专业/seo技术服务外包
目录
1. 数据库分表问题
2. 数据倾斜问题
3. 数据库分表方案
3.1 Range分库分表
3.1.1 Range分库分表介绍
3.1.2 Range分库分表缺点
3.2 Hash分库分表
3.2.1 Hash分库分表介绍
3.2.2 Hash分库分表错误实践
3.2.3 Hash分库分表实践方案分析
4. 数据库分库分表后的主键问题
4.1 Redis生成ID
4.2 UUID、GUID生成ID
4.3 Snowflake
1. 数据库分表问题
MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行。那么,这个数值多少才合适呢?
这个数值和实际记录的条数无关,而与 MySQL 的配置以及机器的硬件有关。因为,MySQL 为了提高性能,会将表的索引装载到内存中,在InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降。
这个还有具体的表结构的设计有关,最终导致问题原因都是内存限制。
2. 数据倾斜问题
良好的分库分表方案,它的数据应该是需要比较均匀的分散在各个库表中的。如果进行一个拍脑袋式的分库分表设计,很容易会遇到以下类似问题:
- 某个数据库实例中,部分表的数据很多,而其他表中的数据却寥寥无几,业务上的表现经常是延迟忽高忽低,飘忽不定。
- 数据库集群中,部分集群的磁盘使用增长特别块,而部分集群的磁盘增长却很缓慢。
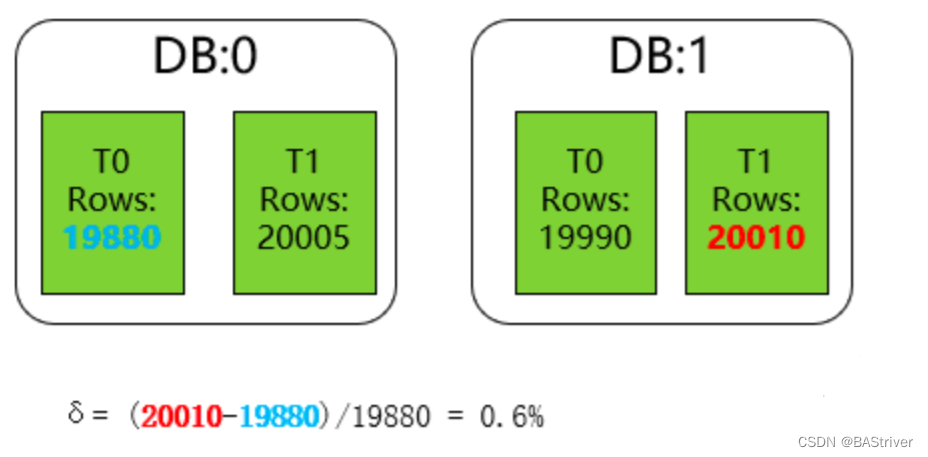
最大数据偏斜率为 :(数据量最大样本 - 数据量最小样本)/ 数据量最小样本
一般来说,如果最大数据偏斜率在5%以内是可以接受的。
3. 数据库分表方案
3.1 Range分库分表
3.1.1 Range分库分表介绍
简单来说,就是根据数据范围划分数据的存放位置。
我们可以把订单表按照年份为单位,每年的数据存放在单独的库(或者表)中。通过数据的范围进行分库分表,该方案是最朴实的一种分库方案,它也可以和其他分库分表方案灵活结合使用。比如TiDB数据库,针对TiKV中数据的打散,也是基于Range的方式进行,将不同范围内的[StartKey,EndKey)分配到不同的Region上。
3.1.2 Range分库分表缺点
- 数据热点问题。比如上面案例中的订单表,很明显当前年度所在的库表属于热点数据,需要承载大部分的IO和计算资源。
- 新库和新表的追加问题。一般我们线上运行的应用程序是没有数据库的建库建表权限的,所以我们需要提前将新的库表提前建立,防止线上故障。
- 业务上的交叉范围内数据的处理。比如订单模块无法避免一些中间状态的数据补偿逻辑,即需要通过定时任务到订单表中扫描那些长时间处于待支付确认等状态的订单。
3.2 Hash分库分表
3.2.1 Hash分库分表介绍
Hash分库分表是最大众最普遍的方案。
针对Hash分库分表的细节部分,相关的资料并不多,如果未结合自身业务贸然参考引用,后期非常容易出现各种问题。
3.2.2 Hash分库分表错误实践
1) 非互质关系导致的数据偏斜问题。
public static ShardCfg shard(String userId) {int hash = userId.hashCode();// 对库数量取余结果为库序号int dbIdx = Math.abs(hash % DB_CNT);// 对表数量取余结果为表序号int tblIdx = Math.abs(hash % TBL_CNT);return new ShardCfg(dbIdx, tblIdx);
}这个方案用Hash值分别对分库数和分表数取余,得到库序号和表序号。
但其实稍微思索一下,我们就会发现,以10库100表为例,如果一个Hash值对100取余为0,那么它对10取余也必然为0。
数据的散落情况如图:
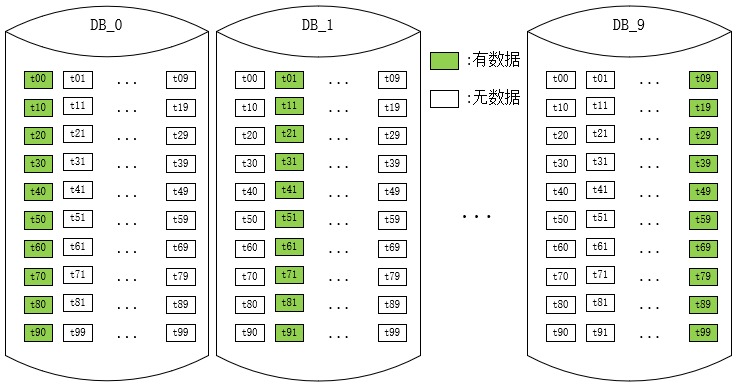
而且,我们除了要考虑数据偏斜的问题,还需要考虑可持续性扩容的问题,一般这种Hash分库分表的方案后期的扩容方式都是通过翻倍扩容法,那11库翻倍后,和100又不再互质。
2) 扩容问题。
把10库100表看成总共1000个逻辑表,将求得的Hash值对1000取余,得到一个介于[0,999)中的数,然后再将这个数二次均分到每个库和每个表中。
public static ShardCfg shard(String userId) {// ① 算Hashint hash = userId.hashCode();// ② 总分片数int sumSlot = DB_CNT * TBL_CNT;// ③ 分片序号int slot = Math.abs(hash % sumSlot);// ④ 计算库序号和表序号的错误案例int dbIdx = slot % DB_CNT ;int tblIdx = slot / DB_CNT ;return new ShardCfg(dbIdx, tblIdx);
}这样解决了数据偏斜的问题,只要Hash值足够均匀,那么理论上分配序号也会足够平均,于是每个库和表中的数据量也能保持较均衡的状态。
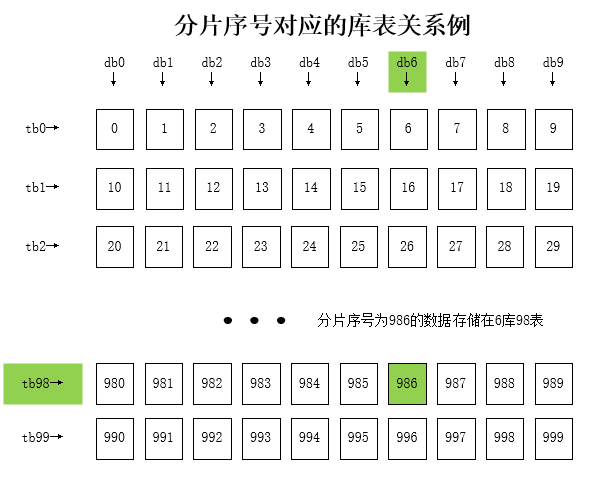
但是该方案有个比较大的问题,那就是在计算表序号的时候,依赖了总库的数量,那么后续翻倍扩容法进行扩容时,会出现扩容前后数据不在同一个表中,从而无法实施。
如上图中,例如扩容前Hash为1986的数据应该存放在6库98表,但是翻倍扩容成20库100表后,它分配到了6库99表,表序号发生了偏移。所以我们在后续在扩容的时候,不仅要基于库迁移数据,还要基于表迁移数据。
3.2.3 Hash分库分表实践方案分析
1) 标准的二次分片法
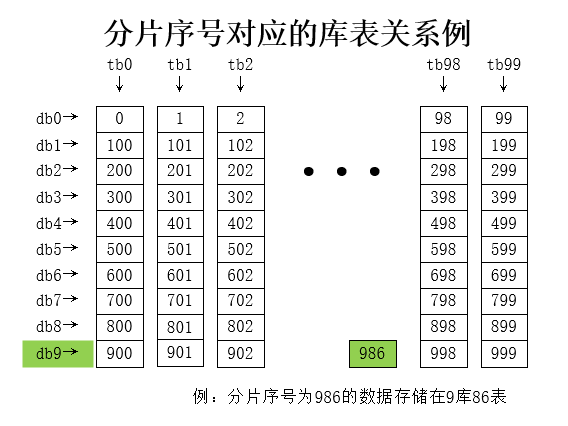
public static ShardCfg shard2(String userId) {// ① 算Hashint hash = userId.hashCode();// ② 总分片数int sumSlot = DB_CNT * TBL_CNT;// ③ 分片序号int slot = Math.abs(hash % sumSlot);// ④ 重新修改二次求值方案int dbIdx = slot / TBL_CNT ;int tblIdx = slot % TBL_CNT ;return new ShardCfg(dbIdx, tblIdx);
}和错误案例二中的区别就是通过分配序号重新计算库序号和表序号的逻辑发生了变化,通过翻倍扩容后,我们的表序号一定维持不变,库序号可能还是在原来库,也可能平移到了新库中(原库序号加上原分库数),完全符合扩容持久性要求。
缺点:
- 翻倍扩容法前期操作性高,但是后续如果分库数已经是大几十的时候,每次扩容都非常耗费资源。
- 连续的分片键Hash值大概率会散落在相同的库中,某些业务可能容易存在库热点(例如新生成的用户Hash相邻且递增,且新增用户又是高概率的活跃用户,那么一段时间内生成的新用户都会集中在相邻的几个库中)。
2) 关系表冗余。
这个方案是将分片键对应库的关系通过关系表记录下来,这张关系表称为"路由关系表"。通过常规的Hash算法计算表序号,而计算库序号时,则从路由表读取数据。因为在每次数据查询时,都需要读取路由表,故我们需要将分片键和库序号的对应关系记录同时维护在缓存中以提升性能。
public static ShardCfg shard(String userId) {int tblIdx = Math.abs(userId.hashCode() % TBL_CNT);// 从缓存获取Integer dbIdx = loadFromCache(userId);if (null == dbIdx) {// 从路由表获取dbIdx = loadFromRouteTable(userId);if (null != dbIdx) {// 保存到缓存saveRouteCache(userId, dbIdx);}}if (null == dbIdx) {// 此处可以自由实现计算库的逻辑dbIdx = selectRandomDbIdx();saveToRouteTable(userId, dbIdx);saveRouteCache(userId, dbIdx);}return new ShardCfg(dbIdx, tblIdx);
}当发现数据存在偏斜时,也可以调整权重使得各个库的使用量调整趋向接近。理论上后续进行扩容的时候,仅需要挂载上新的数据库节点,将权重配置成较大值即可,无需进行任何的数据迁移即可完成。
缺点:
- 每次读取数据需要访问路由表,虽然使用了缓存,但是还是有一定的性能损耗。
- 路由关系表的存储方面,有些场景并不合适。
3) 基因法。
计算库序号的时候做了部分改动,我们使用分片键的前四位作为Hash值来计算库序号。
public static ShardCfg shard(String userId) {int dbIdx = Math.abs(userId.substring(0, 4).hashCode() % DB_CNT );int tblIdx = Math.abs(userId.hashCode() % TBL_CNT);return new ShardCfg(dbIdx, tblIdx);
}假如分库数为16,分表数为100,数量最小行数仅为10W不到,但是最多的已经达到了15W+,最大数据偏斜率高达61%。按这个趋势发展下去,后期很可能出现一台数据库容量已经使用满,而另一台还剩下30%+的容量。但该方案并不是一定不行,而是我们在采用的时候,要综合分片键的样本规则,选取的分片键前缀位数、库数量、表数量,四个变量对最终的偏斜率都有影响。
4) 剔除公因数法。
很多场景下我们还是希望相邻的Hash能分到不同的库中。就像N库单表的时候,计算库序号一般直接用Hash值对库数量取余,该方案的最大数据偏斜度也比较小,针对不少业务从N库1表升级到N库M表下,需要维护库序号不变的场景下可以考虑。
public static ShardCfg shard(String userId) {int dbIdx = Math.abs(userId.hashCode() % DB_CNT);// 计算表序号时先剔除掉公约数的影响int tblIdx = Math.abs((userId.hashCode() / TBL_CNT) % TBL_CNT);return new ShardCfg(dbIdx, tblIdx);
}5) 一致性Hash法。
一致性Hash算法也是一种比较流行的集群数据分区算法,比如RedisCluster即是通过一致性Hash算法,使用16384个虚拟槽节点进行每个分片数据的管理。这个方案我们通常会将每个实际节点的配置持久化在一个配置项或者是数据库中,应用启动时或者是进行切换操作的时候会去加载配置。配置一般包括一个[StartKey,Endkey)的左闭右开区间和一个数据库节点信息。
private TreeMap<Long, Integer> nodeTreeMap = new TreeMap<>();@Override
public void afterPropertiesSet() {// 启动时加载分区配置List<HashCfg> cfgList = fetchCfgFromDb();for (HashCfg cfg : cfgList) {nodeTreeMap.put(cfg.endKey, cfg.nodeIdx);}
}public ShardCfg shard(String userId) {int hash = userId.hashCode();int dbIdx = nodeTreeMap.tailMap((long) hash, false).firstEntry().getValue();int tblIdx = Math.abs(hash % 100);return new ShardCfg(dbIdx, tblIdx);
}正规的一致性Hash算法会引入虚拟节点,每个虚拟节点会指向一个真实的物理节点。这样设计方案主要是能够在加入新节点后的时候,可以有方案保证每个节点迁移的数据量级和迁移后每个节点的压力保持几乎均等。
4. 数据库分库分表后的主键问题
4.1 Redis生成ID
通过Redis的INCR/INCRBY自增原子操作命令,能保证生成的ID肯定是唯一有序的,本质上实现方式与数据库一致。比较适合计数场景,如用户访问量,订单流水号(日期+流水号)等。
优点:整体吞吐量比数据库要高。
缺点:Redis实例或集群宕机后,找回最新的ID值比较麻烦。
4.2 UUID、GUID生成ID
优点:性能非常高,本地生成,没有网络消耗。
缺点:UUID 太长了、占用空间大,作为主键性能太差,由于UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作。
4.3 Snowflake
snowflake算法的特性是有序、唯一,并且要求高性能、低延迟(每台机器每秒至少生成10k条数据,并且响应时间在2ms以内),要在分布式环境(多集群,跨机房)下使用。
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也非常高。
- 根据自身业务特性分配bit位,非常灵活。
缺点:强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。