怎么做网站盗号/太原网站建设
本文参考资源:eat_tensorflow_in_30_days
一,准备数据
titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。
结构化数据一般会使用Pandas中的DataFrame进行预处理。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import models, layersdftrain_raw = pd.read_csv('./data/titanic/train.csv')
dftest_raw = pd.read_csv('./data/titanic/test.csv')
# see the first 10 elements 查看读取到的前十个数据
a = dftrain_raw.head(10)
print(a)数据的内容如下:
字段说明:
- Survived:0代表死亡,1代表存活【y标签】
- Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
- Name:乘客姓名 【舍去】
- Sex:乘客性别 【转换成bool特征】
- Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
- SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
- Parch:乘客父母/孩子的个数(整数值)【数值特征】
- Ticket:票号(字符串)【舍去】
- Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
- Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
- Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
利用Pandas的数据可视化功能我们可以简单地进行探索性数据分析EDA(Exploratory Data Analysis)
1、绘制存活和死亡人数条状图
# 存活人数的分布情况
# kind :设置绘图类型(bar--条形图;figsize-绘图尺寸;fontize--字体尺寸;rot--字体旋转角度)
ax = dftrain_raw['Survived'].value_counts().plot(kind='bar', figsize=(12, 8), fontsize=15, rot=-10)
ax.set_ylabel('Counts', fontsize=15)
ax.set_xlabel('Survived', fontsize=15)
plt.show()
2、年龄分布情况
# 年龄分布情况(hist--直方图;bins--直方图的柱数;color--显示的颜色)
ax = dftrain_raw['Age'].plot(kind='hist', bins=100, color='purple', figsize=(12, 8), fontsize=15)
ax.set_ylabel('Frequency', fontsize=15)
ax.set_xlabel('Age', fontsize=15)
plt.show()
3、存活人数的密度图
# 存活人数密度图(density--密度图;legend--设置图的说明信息)
ax = dftrain_raw.query('Survived == 0')['Age'].plot(kind='density', figsize=(12, 8), fontsize=15)
dftrain_raw.query('Survived == 1')['Age'].plot(kind='density', figsize=(12, 8), fontsize=15)
ax.legend(['Survived==0', 'Survived==1'], fontsize=12)
ax.set_ylabel('Density', fontsize=15)
ax.set_xlabel('Age', fontsize=15)
plt.show()
4、数据预处理
# 数据预处理
def preprocessing(dfdata):# DataFrame :读取表格信息dfresult = pd.DataFrame()# Pclass# get_dummies 将分类变量转换为虚拟变量/指示变量dfPclass = pd.get_dummies(dfdata['Pclass'])dfPclass.columns = ['Pclass_' + str(x) for x in dfPclass.columns] # 设定票的类型设定的列名称dfresult = pd.concat([dfresult, dfPclass], axis=1)# Sex 根据性别增加两列dfSex = pd.get_dummies(dfdata['Sex'])dfresult = pd.concat([dfresult, dfSex], axis=1)# Age 根据年龄增加两列(为空或者不为空)# pd.isna 判断数据是否为空dfresult['Age'] = dfdata['Age'].fillna(0)dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')# SibSp,Parch,Fare(3列)dfresult['SibSp'] = dfdata['SibSp']dfresult['Parch'] = dfdata['Parch']dfresult['Fare'] = dfdata['Fare']# Carbin(1列)dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')# Embarked(登船港口 4 列)dfEmbarked = pd.get_dummies(dfdata['Embarked'], dummy_na=True)dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]dfresult = pd.concat([dfresult, dfEmbarked], axis=1)return dfresultx_train = preprocessing(dftrain_raw)
y_train = dftrain_raw['Survived'].valuesx_test = preprocessing(dftest_raw)
y_test = dftest_raw['Survived'].valuesprint("x_train.shape =", x_train.shape)
print("x_test.shape =", x_test.shape)
二、定义模型
使用Keras接口有以下3种方式构建模型:(1)使用Sequential按层顺序构建模型;(2)使用函数式API构建任意结构模型;(3)继承Model基类构建自定义模型。
此处选择使用最简单的Sequential,按层顺序模型。
# 二、定义模型
tf.keras.backend.clear_session()model = models.Sequential()
model.add(layers.Dense(20, activation='relu', input_shape=(15,)))
model.add(layers.Dense(10, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))model.summary()
三、训练模型
训练模型通常有3种方法:(1)内置fit方法;(2)内置train_on_batch方法;(3)以及自定义训练循环。此处我们选择最常用也最简单的内置fit方法。
优化方法:大多数机器学习(深度学习)任务就是最小化损失,在损失函数定义好的情况下,使用一种优化器进行求解最小损失。深度学习常见的优化方式是基于梯度下降的算法。
详细说明请参考该博客
- SGD(stochastic gradient descent):随机梯度下降,算法在每读入一个数据都会立刻计算loss function的梯度来update参数;
- BGD(batch gradient descent):批量梯度下降,算法在读取整个数据集后累加来计算损失函数的的梯度
- Mini-BGD(mini-batch gradient descent):顾名思义,选择小批量数据进行梯度下降,这是一个折中的方法.采用训练集的子集(mini-batch)来计算loss function的梯度.
- Momentum 在更新方向的时候保留之前的方向,增加稳定性而且还有摆脱局部最优的能力.
- Adagrad:(adaptive gradient)自适应梯度算法,是一种改进的随机梯度下降算法.
- Adam:(adaptive moment estimation)是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。优点:每一次迭代学习率都有一个明确的范围,使得参数变化很平稳
损失函数:Keras中常用的损失函数如下:
-
mean_squared_error或mse 均方误差
-
mean_absolute_error或mae 平均绝对误差
-
mean_absolute_percentage_error或mape 平均绝对百分比误差
-
mean_squared_logarithmic_error或msle 均方对数误差
-
squared_hinge
-
hinge
-
binary_crossentropy(亦称作对数损失,logloss)用于二分类中
-
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如
(nb_samples, nb_classes)的二值序列 -
sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:
np.expand_dims(y,-1) -
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
-
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
度量方法:判断模型训练结果好坏所使用的指标;因为常用的指标很多,例如准确率、精确率、召回率、AUC等;不同的情况下选择的指标也存在差异。在分类模型中常用的评价指标是 AUC。
AUC相关详细介绍 ROC 详细介绍
# 三、训练模型
# 二分类问题选择二元交叉熵损失函数
# 定义训练模型的参数
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['AUC'])
# 训练模型
history = model.fit(x_train, y_train,batch_size=64,epochs=30,validation_split=0.2)四、评估模型
评估一下模型在训练集和验证集上的效果
# 四、评估模型
def plot_metric(history, metric):""":type history: object"""train_metrics = history.history[metric]val_metrics = history.history['val_' + metric]epochs = range(1, len(train_metrics) + 1)plt.plot(epochs, train_metrics, 'bo--')plt.plot(epochs, val_metrics, 'ro-')plt.title('Training and validation ' + metric)plt.xlabel("Epochs")plt.ylabel(metric)plt.legend(["train_" + metric, 'val_' + metric])plt.show()plot_metric(history, "loss")
plot_metric(history, "auc")
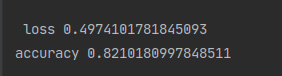
loss, accuracy = model.evaluate(x=x_test, y=y_test)
print('\n loss', loss)
print('accuracy', accuracy)


五、使用模型
# 五,使用模型
# 预测概率
y_pre = model.predict(x_test[0:10])
# model(tf.constant(x_test[0:10].values,dtype = tf.float32)) #等价写法
print(y_pre)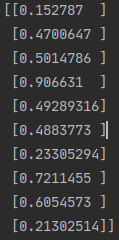
# 预测类别
y_class_pre = model.predict_classes(x_test[0:10])
print(y_class_pre)![]()
六、模型保存
使用TensorFlow原生方式保存,可以跨平台进行模型部署。
# 保存权重,该方式仅仅保存权重张量
model.save_weights('./data/tf_model_weights.ckpt', save_format="tf")
# 保存模型结构与模型参数到文件,该方式保存的模型具有跨平台性便于部署model.save('./data/tf_model_savedmodel', save_format="tf")
print('export saved model.')model_loaded = tf.keras.models.load_model('./data/tf_model_savedmodel')
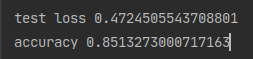
loss_test, accuracy_test = model_loaded.evaluate(x_test, y_test)
print('\n loss', loss_test)
print('accuracy', accuracy_test)