公司网站制作流程2016/seo流量排名工具
01
Kudu的设计初衷
在介绍Kudu是什么之前,还是先简单的说一下现存系统针对结构化数据存储的一些痛点问题。结构化数据的存储,通常包含如下两种方式:
- 静态数据通常以Parquet或者Avro形式直接存放在HDFS中,对于分析场景,这种存储通常是更加适合的。但无论以哪种方式存在于HDFS中,都难以支持单条记录级别的更新,随机读取也并不高效。
- 可变数据的存储通常选择HBase或者Cassandra,因为它们能够支持记录级别的高效读写。但这种存储却并不适合分析场景,因为它们在大数据量顺序读取场景下的性能相对较差(针对HBase而言,有两方面的主要原因。一是HFile本身的结构定义,它是按行组织数据的,这种格式针对大多数的分析场景,都会带来较大的IO消耗,因为可能会读取很多不必要的数据,相对而言Parquet格式针对分析场景就做了很多优化。二是由于HBase本身的LSM-Tree架构决定的,HBase的读取路径中,不仅要考虑内存中的数据,同时要考虑HDFS中的一个或多个HFile,较之于直接从HDFS中读取文件而言,这种路径是过长的)。
可以看出,如上两种存储方式,都存在明显的优缺点。直接存放于HDFS中,尽管适合分析,但却不利于记录级别的随机读写。而直接将数据存放于HBase中,适合记录级别的随机读写,但却并不适合分析。而在很多业务场景中,我们都可能同时存在这两类场景。我们的通常做法有如下几种:
数据存放于HBase中,对于分析任务,基于Hive Over HBase/MapReduce进行。可容忍这种场景下的分析性能。
对于分析性能要求较高的,可以将数据在HDFS/Hive中多冗余存放一份。
或者将HBase中的数据定期的导出成Parquet格式的数据。
明显的,这种方案中,数据一致性是一个较大的问题。
同时,架构也较复杂。
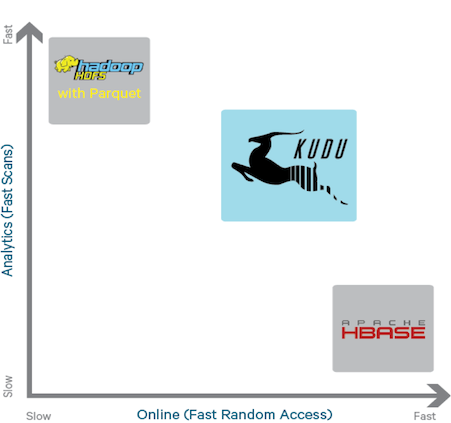
图表 1 Kudu在生态系统中的定位
Kudu的设计,就是试图在实时分析与随机读写之间,寻求一个最佳的结合。另外一个初衷,在Cloudera发布的《Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data》一文中有提及,Kudu作为一个新的分布式存储系统也是为了进一步提升CPU的使用效率。下面的章节中,将会详细介绍Kudu的设计原理。
02
Kudu的原理介绍
(在阅读Kudu的论文之间,我特意留意了一下该论文的作者列表,其中有好几位都是HBase社区的Committer以及PBC成员,这其中就包含第一作者。在阅读这篇论文的过程中,也能够强烈的感觉到BigTable/HBase/HydraBase的很多设计思想都被包含在Kudu的设计中。也正因此原因,在如下的描述中,我将会多次谈及Kudu与HBase在设计上的异同)。
2.1
表与Schema
Kudu设计是面向结构化存储的,因此,Kudu的表,需要用户在建表时定义它的Schema信息,这些Schema信息包含:列定义(含类型),Primary Key定义(用户指定的若干个列的有序组合)。数据的唯一性,依赖于用户所提供的Primary Key中的Column组合的值的唯一性。Kudu提供了Alter命令来增删列,但位于Primary Key中的列是不允许删除的。
Kudu当前并不支持二级索引。
2.2
API
Kudu提供了Java/C++两种语言的API(尽管也提供了Python API,但尚处于Experimental阶段)。通过这些API,可以进行如下一些操作:
- Insert/Update/Delete
- 批量数据导入/更新操作
- Scan(可支持简单的Filter)
- …………
2.3
事务与一致性模型
Kudu仅仅提供单行事务,也不支持多行事务。这一点与HBase是相似的。但在数据一致性模型上,与HBase有较大的区别。Kudu提供了如下两种一致性模型:
- Snapshot Consistency
这是Kudu中的默认一致性模型。在这种模型中,只保证一个客户端能够看到自己所提交的写操作,而并不保障全局的(跨多个客户端的)事务可见性。
- External Consistency
最早提出External Consistency机制的,应该是在Google的Spanner论文中。传统关系型数据库中的两阶段提交机制,需要两回合通信,这过程中带来的代价是较高的,但同时这过程中的复杂的锁机制也可能会带来一些可用性问题。一个更好的实现分布式事务/一致性的思路,是基于一个全局发布的Timestamp机制。Spanner提出了Commit-wait的机制,来保障全局事务的有序性:如果一个事务T1的提交先于另外一个事务T2的开始,则T1的Timestamp要小于T2的TimeStamp。我们知道,在分布式系统中,是很难于做这样的承诺的。在HBase中,我们可以想象,如果所有RegionServer中的SequenceID发布自同一个数据源,那么,HBase的很多事务性问题就迎刃而解了,然后最大的问题在于这个全局的SequenceID数据源将会是整个系统的性能瓶颈点。回到External Consistency机制,Spanner是依赖于高精度与可预见误差的本地时钟(TrueTime API)实现的(即需要一个高可靠和高精度的时钟源,同时,这个时钟的误差是可预见的。感兴趣的同学可以阅读Spanner论文,这里不赘述)。Kudu中提供了另外一种思路来实现External Consistency,基于Timestamp扩散机制,即,多个客户端可相互通信来告知彼此所提交的Timestamp值,从而保障一个全局的顺序。这种机制也是相对较为复杂的。
与Spanner类似,Kudu不允许用户自定义用户数据的Timestamp,但在HBase中却是不同。用户可以发起一次基于某特定Timestamp的查询。
2.4
Kudu的架构
Kudu也采用了Master-Slave形式的中心节点架构,管理节点被称作Kudu Master,数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
Kudu Master在Kudu集群中,发挥如下的一些作用:
- 用来存放一些表的Schema信息,且负责处理建表等请求。
- 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
- 存放Tablet到Tablet Server的部署信息。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
- Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
- 一个Tablet被部署到了多个Tablet Server中。然而,在HBase最初的架构中,一个Region却是被部署在了一个RegionServer中,它的数据多副本是交由HDFS来保障的。尽管后来HBase有了Region Replica特性,或者是Facebook贡献的HydraBase的设计思路来实现Region的多个副本,来优化HBase的MTTR时间,但迄今为止均尚不成熟。
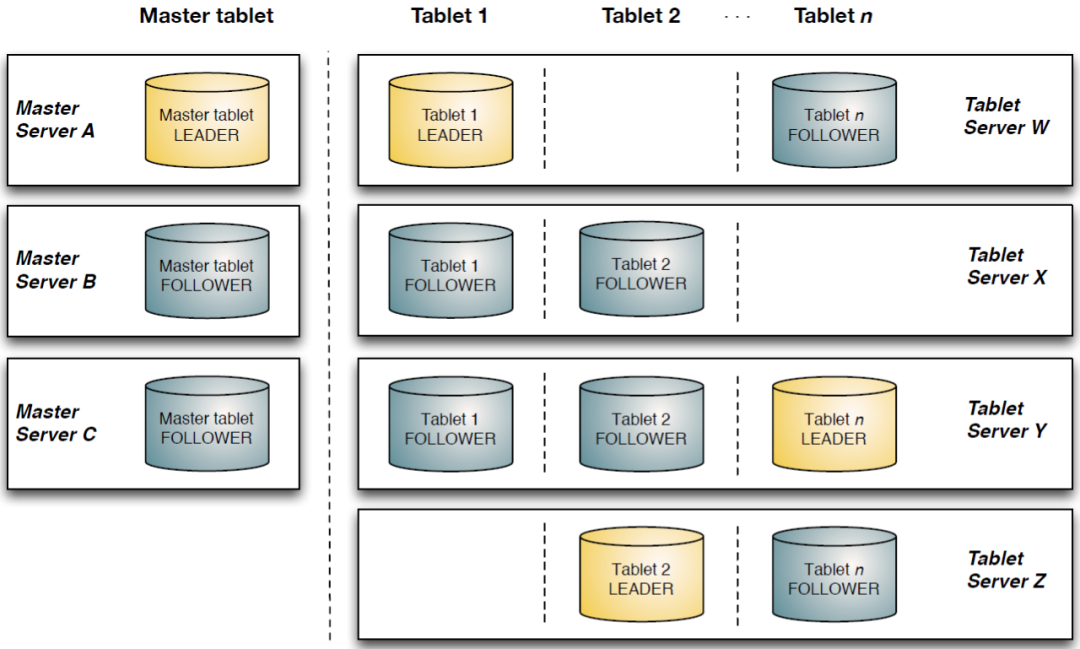
图表2Kudu的数据多副本机制
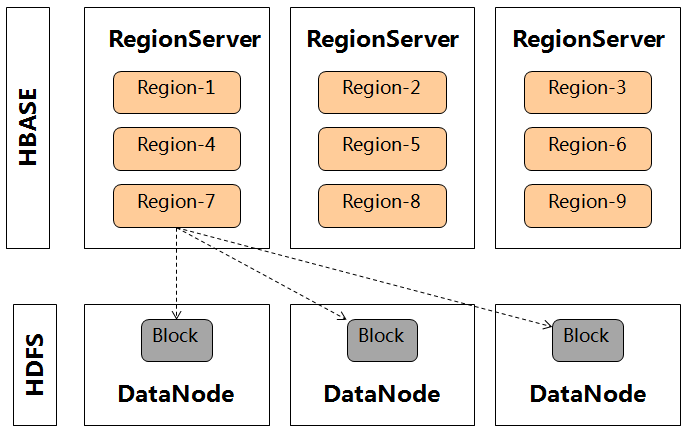
图表3HBase的数据多副本机制
2.5
Kudu的底层数据模型
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下的几个设计目标:
- 可提供快速的列式查询
- 可支持快速的随机更新
- 可提供更为稳定的查询性能保障
为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元:
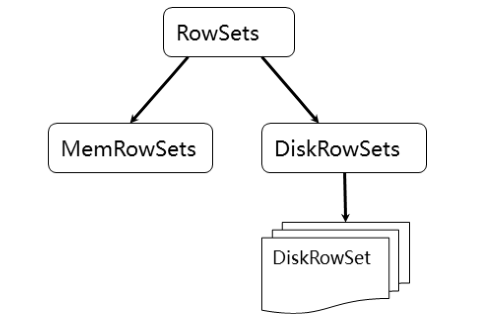
图表 4 RowSets
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。
DiskRowSet中的数据按照Column进行组织,与Parquet类似。这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的?与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
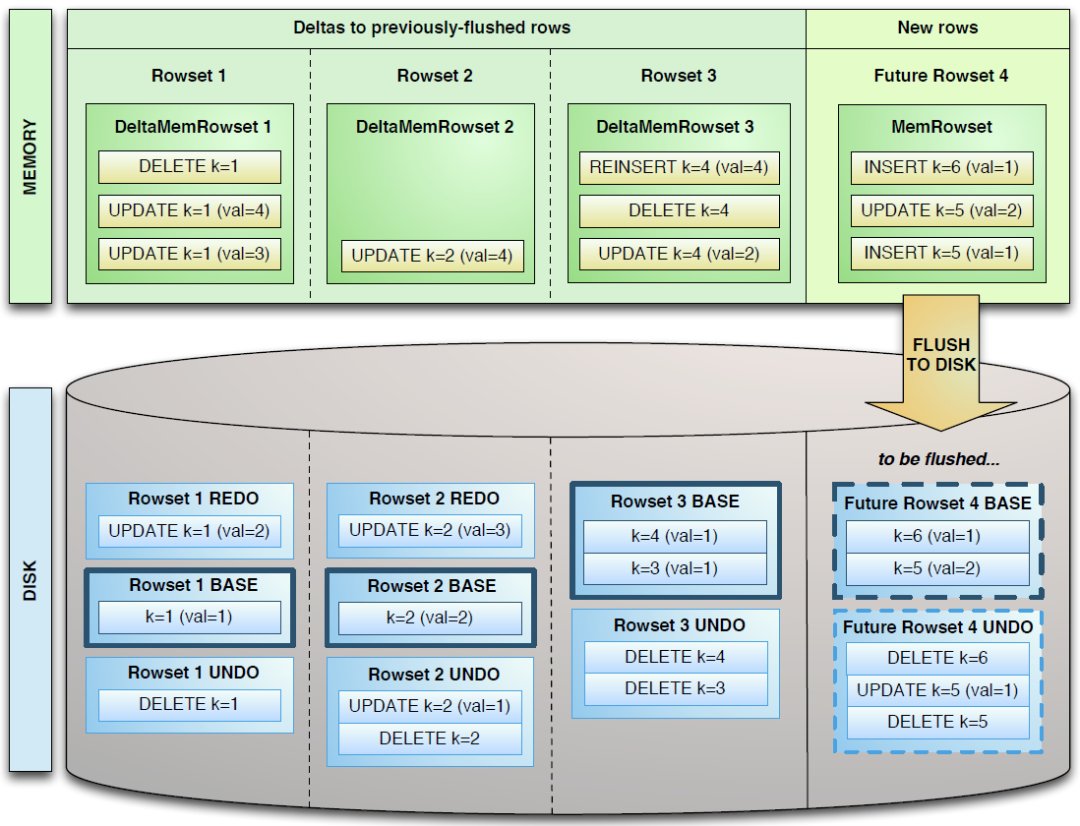
图表 5 Delta Store Design
上图来自Kudu的源工程文件。从上图来看,Delta数据部分应该包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异。如下是源码中关于REDO与UNDO的解释:

REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。
UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。
2.6
数据读写流程
写数据的流程,如下图所示:
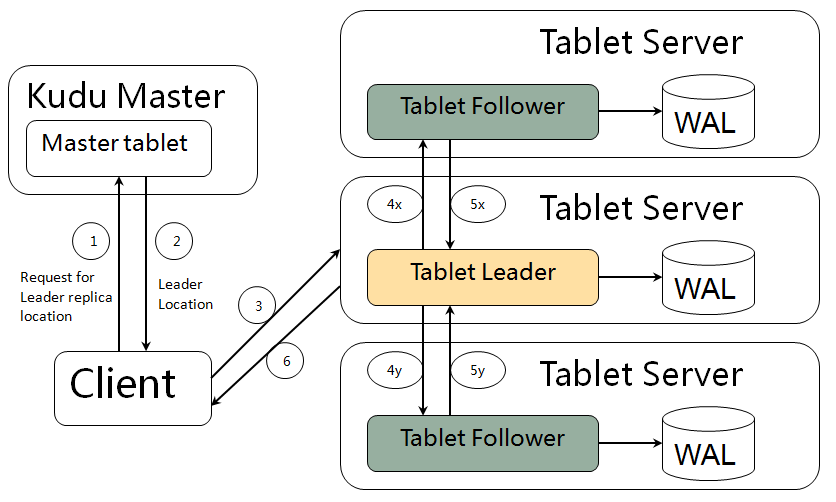
Kudu不允许用户数据的Primary Key重复,因此,在Tablet内部写入数据之前,需要先从已有的数据中检查当前新写入的数据的Primary Key是否已经存在,尽管在DiskRowSets中增加了BloomFilter来提升这种判断的效率,但可以预见,Kudu的这种设计将会明显增大写入的时延。
数据一开始先存放于MemRowSets中,待大小超出一定的阈值之后,再Flush成DiskRowSets。这部分已经在图表5中有详细的介绍。随着Flush次数的不断增加,生成的DiskRowSets也会不断的增多,在Kudu内部也存在一个Compaction流程,这样可以将已经存在的多个存在Primary Key交集的DiskRowSets重新排序而生成一个新的DiskRowSets。如下图所示:
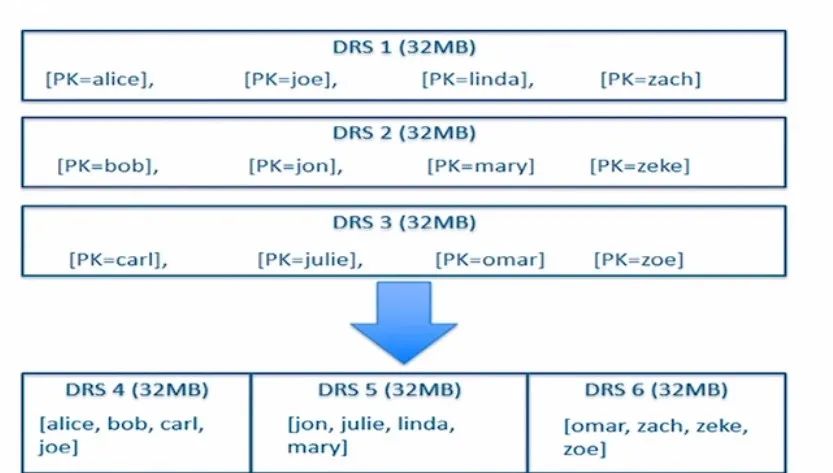
图表 7 RowSet Compaction
读数据的流程,既要考虑存在于内存中的MemRowSets,又要读取位于磁盘中的一个或多个DiskRowSets,在Scanner的高层抽象中,应该与HBase类似。如下重点提一些细节的优化点:
- 通过Scan的范围,与每一个DiskRowSets中的Primary Key Range进行对比,可以首先过滤掉一些不必要参与此次Scan的DiskRowSets。
- Delta Store部分,针对记录级别的更改,记录了Base Data中对应原始数据的Offset。这样,在判断一条记录是否存在更改的记录时,将会更加的快速。
- 由于DiskRowSets的底层文件是按照列组织的,基于一些列的条件进行过滤查询时,可以优先过滤掉一些不必要的Primary Keys。Kudu并不会在一开始读取的时候就将一行数据的所有列读取出来,而是先读取与过滤条件相关的列,通过将这些列与查询条件匹配之后,再来决定是否去读取符合条件的行中的其它的列信息。这样可以节省一些磁盘IO。这就是Kudu所提供的Lazy Materialization特性。
2.7
Raft模型
与HydraBase类似,Kudu采用了Raft协议,来保持Tablet多副本之间的数据一致性。Raft是比Paxos更容易理解且更简单的一种一致性协议,请参考:https://raft.github.io/。Paxos更多的是从理论上提供了一种一致性模型,而Raft确实一种更贴近实际应用的实现。
03
Kudu与HBase的区别
这里再总结一下Kudu与HBase的一些大的区别点:
- Kudu的数据分区方式相对多样化,而HBase较单一。
- Kudu的Tablet自身具备多副本机制,而HBase的Region依赖于底层HDFS的多副本机制。在HBase 1.0版本中已经有了Region Replica(HBASE-10070)特性,同时,社区还有Facebook贡献的HydraBase的方案,但均尚不成熟。
- Kudu底层不依赖于其它的分布式文件系统。而HBase依赖于HDFS。
- Kudu的底层文件格式采用了类似于Parquet的列式存储格式,而HBase的底层HFile文件却是按行来组织的。
- Kudu关于底层的Flush任务以及Compaction任务,能够结合忙时或者闲时进行自动的调整。HBase还尚不具备这种调度能力。
- Kudu的Compaction无Minor/Major的区分,限制每一次Compaction的IO总量在128MB大小,因此,并不存在长久执行的Compaction任务。Compaction是按需进行的,例如,如果所有的写入都是顺序写入,则将不会触发Compaction。
- Kudu的设计,既兼顾了分析型的查询能力,又兼顾了随机读写能力,这样,势必也会付出一些代价。例如,写入数据时关于Primary Key唯一性的限制,就要求写入前要检查对应的Primary Key是否已经存在,这样势必会增大写入的时延。而底层尽管采用了类似于Parquet的列式文件设计,但与HBase类似的冗长的读取路径,也会对分析性的查询带来一些影响。另外,这种设计在整行读取时,也会付出较高的代价。
04
Kudu与现有系统的对接
Kudu提供了与如下一些系统的对接:
MapReduce: 提供针对Kudu用户表的Input以及Output任务对接。
Spark: 提供与Spark SQL以及DataFrames的对接。
Impala: Kudu自身未提供Shell以及SQL Parser,所以,它的SQL能力源自与Impala的集成。
在这些集成中,能够很好的感知Kudu表数据的本地性信息,能够充分利用Kudu所提供的过滤器对查询进行优化,同时,Impala本身的DDL/DML语法针对Kudu也做了一些扩展。
可以想象,Cloudera在Impala与Kudu的集成上,未来一定会有更多的发力点。
05
在开始本文之前,建议在华为云购买一台云服务器,同时考虑到后续的顺利操作,云服务器需要有一些要求:
CPU架构:x86计算
规格:c6.2xlarge.2(提高编译速度)
镜像:公共镜像,CentOS CentOS 8.0 64bit
系统盘:高IO,100GB
弹性公网:按流量计费(提高下载速度)
02
Kudu的适用场景
Todd Lipcon在今年的Strata+Hadoop World 2015大会上所提供的主题为《Kudu: Resolving transactional and analytic trade-offs in Hadoop》的演讲中,这样子描述Kudu的适用场景:

06
Kudu Benchmark数据解析
如下使得Kudu WhitePage中所提供的一些Benchmark性能测试数据的简单解析(详细的结果请参考论文的第6章节):
- 基于TPC-H测试标准,针对Impala On Parquet以及Impala On Kudu做了对比测试,Impala On Kudu的平均性能比Impala On Parquet提升了31%。这是由于Kudu所提供的Lazy Meterialization特性以及对对CPU效率的提升而带来的成果。
- Impala-Kudu与Phoenix-HBase的对比:测试使用到了TPC-H中的lineitem一表,共导入了62GB的CSV格式的数据。在导入Phoenix时使用了Phoenix所提供的CsvBulkLoadTool工具。测试时的一些配置信息如下所示:
- 为Phoenix表划分了100个Hash Partitions。为Kudu创建了100个Tablets。
- HBase采用默认的Block Cache策略,为每一个RegionServer配置了9.6GB的Cache内存。而Kudu配置了1GB的Block Cache的进程内存,但同时还依赖于操作系统的Buffer。
- HBase表中采用了FAST_DIFF的Block Encoding算法,未启用任何压缩。
数据导入到HBase中之后,主动触发了一次Major Compaction,来确保数据的本地化率。62GB原始数据导入到HBase中之后的总大小约为570GB(这是由于未启用Compression压缩,同时,由于多个列都是独立存在的带来的膨胀导致),而导入到Kudu中之后的大小约为227GB。如下是相应的对比测试场景以及对比结果:
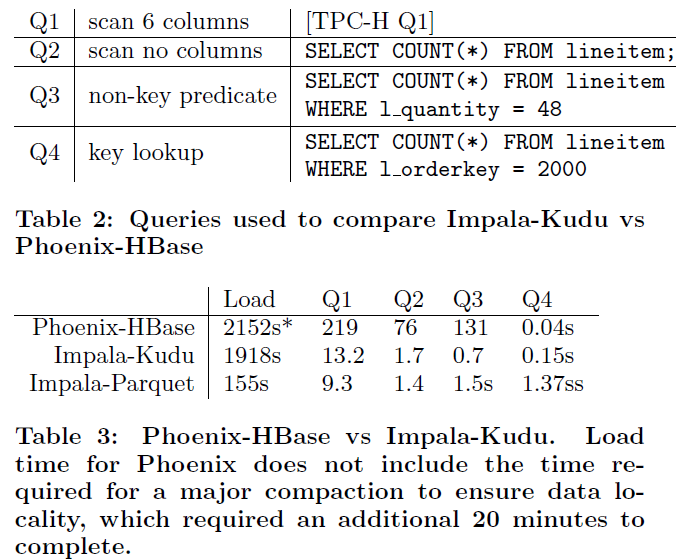
除了基于Key值的整行数据的查询性能,Phoenix有明显的优势以外,其它的基于整表扫描,或者是基于一些列的查询,Impala-Kudu是有明显的优势的。基于Scan + Filter的查询,HBase本身就不擅长。
1. 随机读写能力的对比
如下是对比测试的一些场景:

如下是对比测试的结果:
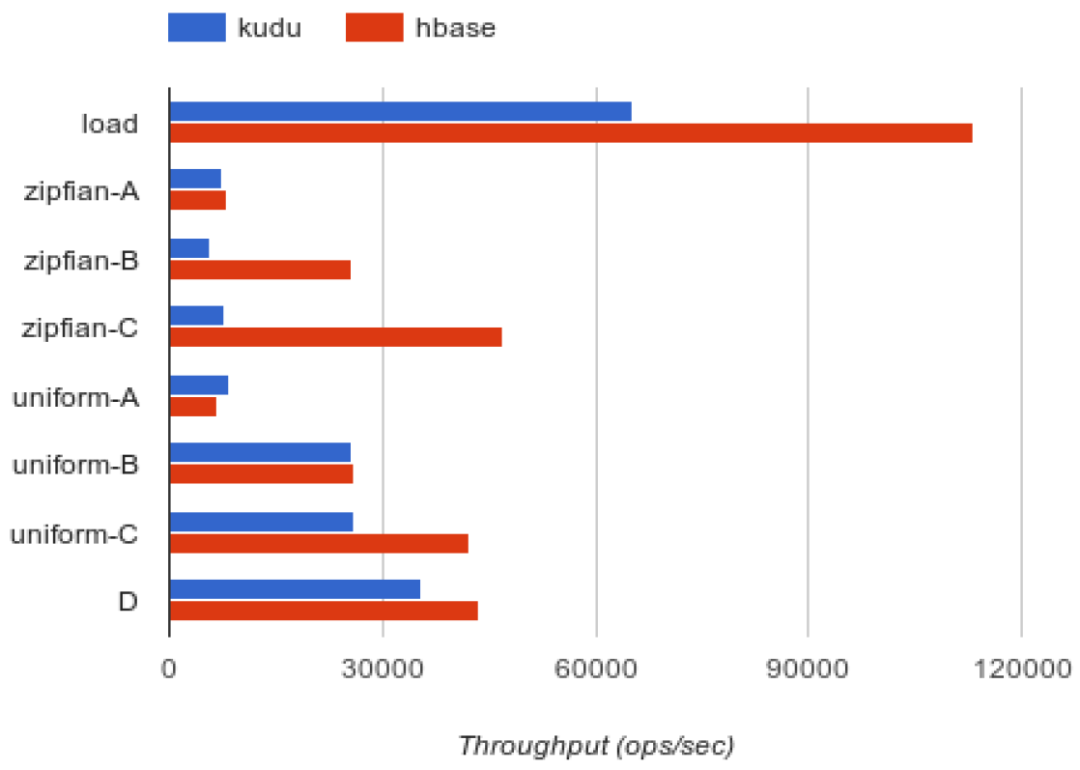
关于加载以及Zipfian分布模式下,HBase的优势更加明显,当前Kudu也正在做关于Zipfian分布模式下的优化(KUDU-749),而在Uniform模式下,HBase的优势稍弱。整体来看,在随机读写上,Kudu的设计较之HBase而言,存在一些劣势,这是为了兼顾分析型查询所付出的一些代价。
07
参考信息
[1]http://blog.cloudera.com/blog/2015/09/kudu-new-apache-hadoop-storage-for-fast-analytics-on-fast-data/
[2]http://getkudu.io/kudu.pdf
[3]https://www.oreilly.com/ideas/kudu-resolving-transactional-and-analytic-trade-offs-in-hadoop
[4]https://dev.mysql.com/doc/refman/5.7/en/innodb-undo-logs.html
[5] https://raft.github.io/
[6]http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/spanner-osdi2012.pdf
-END-

-内容精选,欢迎品鉴-
《上亿条数据,如何查询分析简单又高效》《数据湖探索DLI新功能:基于openLooKeng的交互式分析》《Spark on Elasticsearch一致性问题的探索》《【CloudTable标签索引特性】HBase与AI/用户画像/推荐系统的结合》------------------
感谢你的阅读,这里有一条抽奖链接:11月9日9点开奖,将送出华为云数据湖探索DLI2020限定版卫衣,感谢大家的转发、在看和支持。