做导航网站备案/怎么做营销推广
作者:谢敏灵,Cloudera资深解决方案架构师
背景
数据质量平台基于定义好的数据稽核和数据质量规则,生成Spark SQL并提交运行到HDP 3.1.5集群的Spark 2.3.2上。Spark 通过以下方式之一获取某Hadoop集群上Hive表的数据:
- JDBC方式。Spark基于已有的Presto JDBC客户端,通过Presto服务器获取某Hadoop集群Hive表数据。
优点:Presto已打通与某Hadoop集群的连通,无需额外开通端口;
缺点:SQL通过Presto走,性能受制于Presto服务器和JDBC连接数。
- Hive Metastore方式。Spark获取Hive Metastore的元数据,基于元数据直接访问某Hadoop集群的HDFS,获取Hive表数据。
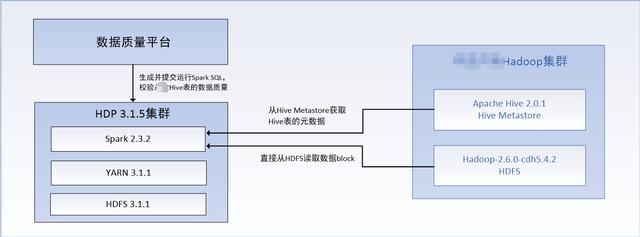
优点:直接访问数据源,性能不受限制,性能调优集中在Spark端。
缺点:需要开通某Hadoop集群的Hive Metastore和HDFS的对应端口(如:Hive Metastore端口、NameNode端口、DataNode端口)。
本文只讨论Hive Metastore方式的配置和验证,即在对应端口已开通的前提下,如何通过配置实现Spark访问外部Hive 2。
1.1 模拟验证环境
基于以下环境模拟验证HDP Spark 2访问外部Hive 2:
- HDP 3.1.5集群,组件版本:Spark 2.3.2,YARN 3.1.1,HDFS 3.1.1
- CDH 6.2.0集群,组件版本:HDFS 3.0.0+cdh6.2.0,Hive 2.1.1+cdh6.2.0
Spark访问外部Hive Metastore
2.1 Spark访问Hive Metastore的相关配置
参考:https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html2.1.1 hive-site.xml
Hive配置文件hive-site.xml需要放置到HDP Spark配置目录/etc/spark2/conf下,Spark基于hive-site.xml获取hive metastore uris等信息。
注意:hive-site.xml文件的属主是:spark:spark。
2.1.2 spark-defaults.conf
Spark SQL的Hive支持最重要的部分之一是与Hive Metastore的交互,这使Spark SQL能够访问Hive表的元数据。从Spark 1.4.0开始,Spark SQL的一个二进制构建包可以使用下面描述的配置来查询不同版本的Hive Metastore。
spark.sql.hive.metastore.version
Hive Metastore的版本。HDP Spark的默认配置为:3.0
spark.sql.hive.metastore.jars
用于实例化HiveMetastoreClient的jar包的位置。可用选项:
- builtin:使用Spark内置的Hive jar包
- maven:使用从Maven存储库下载的指定版本的Hive jar包
- JVM类路径:JVM标准格式的类路径。这个类路径必须包含所有Hive及其依赖项,包括正确版本的Hadoop。这些jar只需要出现在driver上,但是如果在yarn cluster模式下运行,那么必须确保它们与应用程序打包在一起。
HDP Spark的默认配置为:/usr/hdp/current/spark2-client/standalone-metastore/*
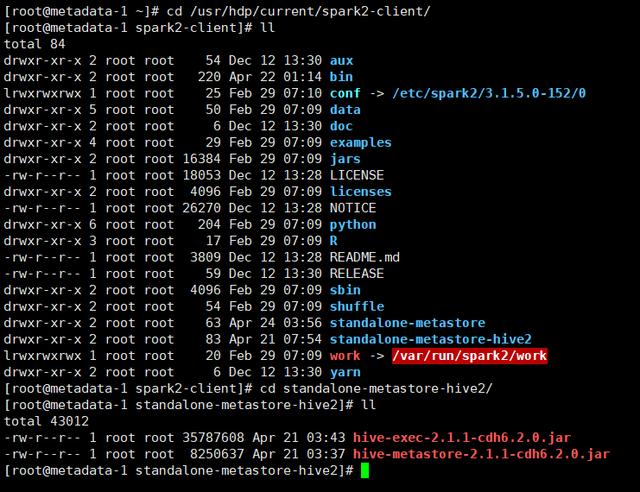
2.2 Option 1:使用外部Hive Jar包
在/usr/hdp/current/spark2-client下创建目录standalone-metastore-hive2,并将外部Hive 2的hive-exec和hive-metastore包放到该目录下:
更改spark-defaults.conf配置:
- spark.sql.hive.metastore.version:2.0
- spark.sql.hive.metastore.jars:
/usr/hdp/current/spark2-client/standalone-metastore-hive2/*
测试验证:
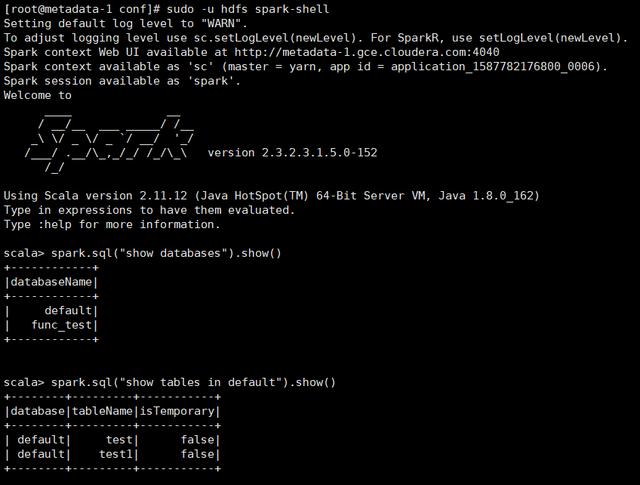
可以访问外部Hive Metastore元数据。
2.3 Option 2:使用Spark内置的Hive Jar包
更改spark-defaults.conf配置:
- spark.sql.hive.metastore.version:1.2.2
- spark.sql.hive.metastore.jars:builtin
测试验证:
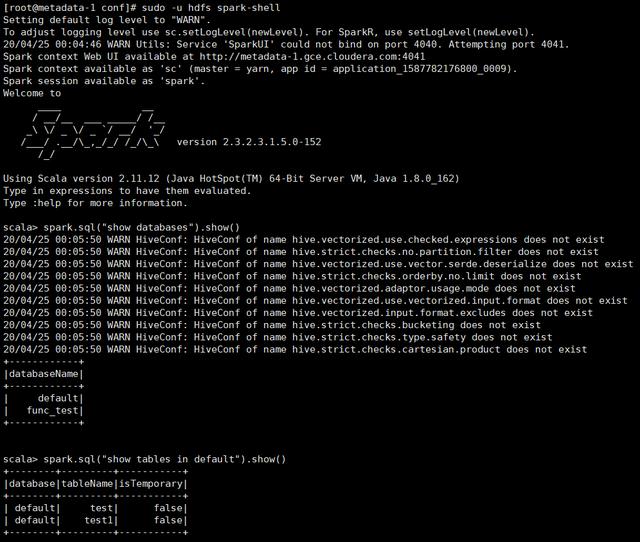
可以访问外部Hive Metastore元数据。
Spark访问外部Hive表
3.1 Option 1:hdfs-site.xml和core-site.xml
将外部Hive 2的hdfs-site.xml(HDFS配置)和core-site.xml(安全配置)文件放置到HDP Spark配置目录/etc/spark2/conf下。
注意:hdfs-site.xml和core-site.xml文件的属主是:spark:spark。
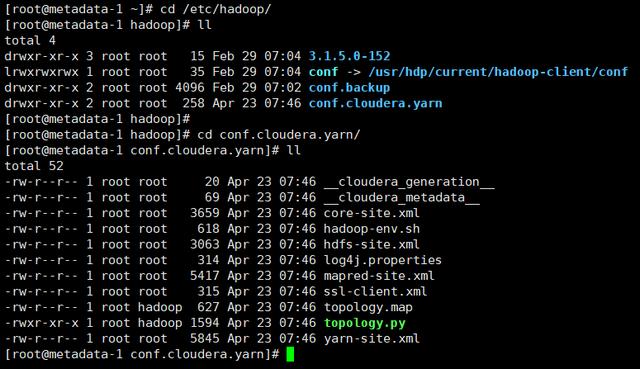
同时,还需要把CDH的yarn配置目录conf.cloudera.yarn整体复制到HDP Hadoop配置目录/etc/hadoop目录下:
Spark访问外部Hive表测试验证:
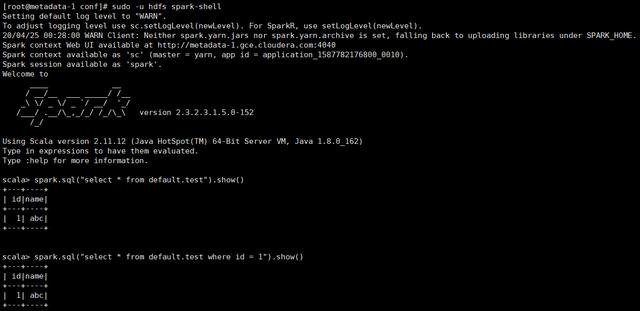
可以访问外部Hive表数据。
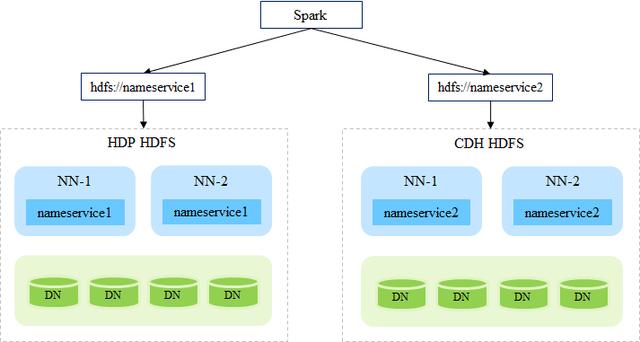
3.2 Option 2:HDFS跨集群访问
Option 1需要复制CDH的hdfs-site.xml、core-site.xml和conf.cloudera.yarn到HDP的相应目录下,比较麻烦,同时这种方式也不够灵活。
本文提出另一种更简单灵活的方式,该方式基于HDP和CDH的HDFS跨集群访问。
要实现HDFS跨集群访问及集群间互访,首先需要保证每个集群的nameservice ID唯一
(更改nameservice参考:https://docs.cloudera.com/documentation/enterprise/5-6-x/topics/admin_ha_change_nameservice.html);其次需要在hdfs-site.xml里增加其它集群的nameserviceID到dfs.nameservices属性中,如:
dfs.nameservices nameservice1,nameservice2,nameservice3,nameservice4同时复制那些引用nameserviceID的其它属性到hdfs-site.xml中,如:
dfs.ha.namenodes.dfs.client.failover.proxy.provider.dfs.namenode.rpc-address..dfs.namenode.servicerpc-address..dfs.namenode.http-address..dfs.namenode.https-address..dfs.namenode.rpc-address..dfs.namenode.servicerpc-address..dfs.namenode.http-address..dfs.namenode.https-address..HDFS跨集群访问测试验证:
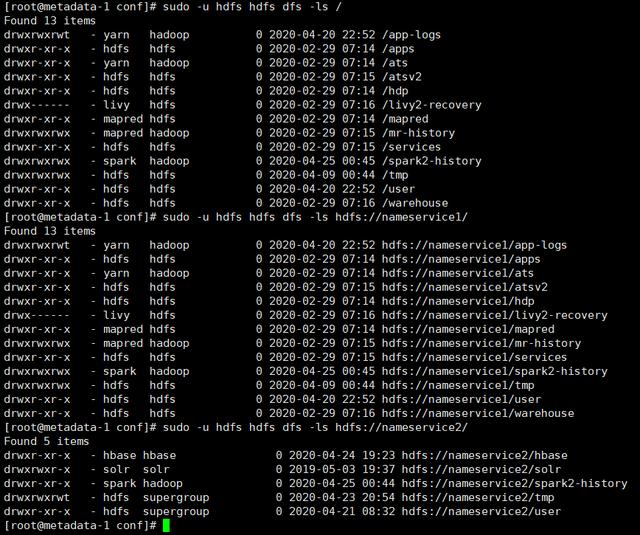
以上,nameservice1是HDP HDFS的ID,nameservice2是CDH HDFS的ID。
Spark访问外部Hive表测试验证:
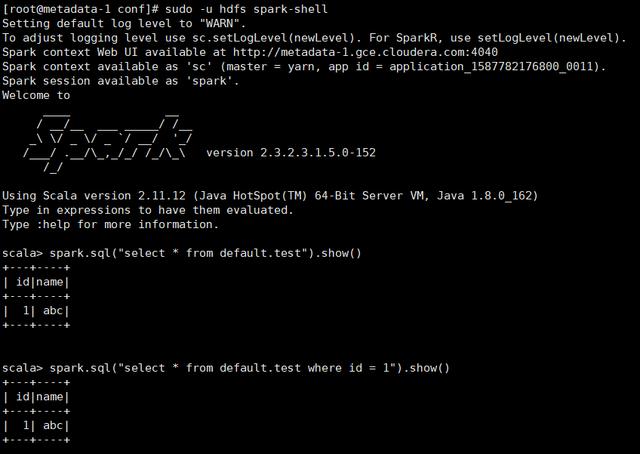
可以访问外部Hive表数据。
相比于Option 1,Option 2无需复制任何配置文件,同时Spark可以灵活地访问两个HDFS集群的文件: