管理员修改网站的参数会对网站的搜效果产生什么影响?/百度推广方式
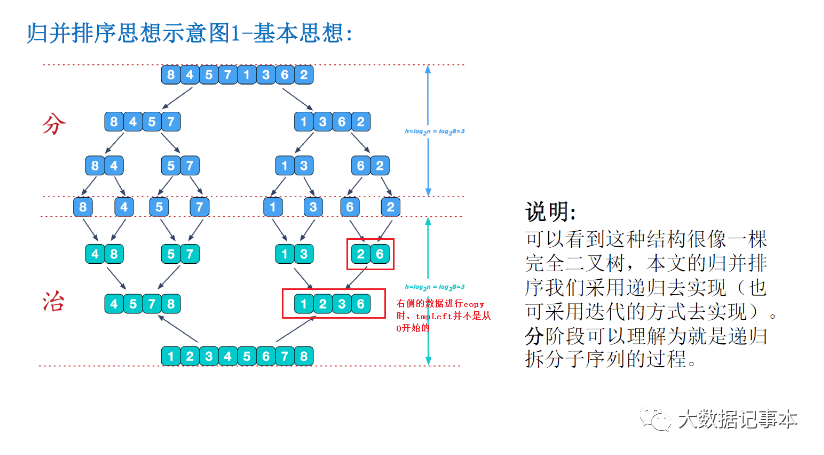 在"分"的阶段,我们把原始数组不断地从中间分开,形成两个新的数组,一直分到每个数组只剩一个元素
在"分"的阶段,我们把原始数组不断地从中间分开,形成两个新的数组,一直分到每个数组只剩一个元素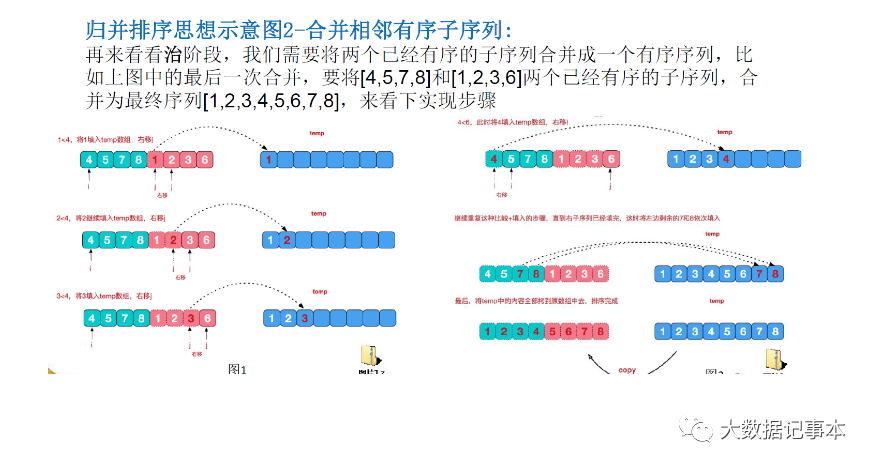 而在"治"的阶段,又把分成的多个数组两两按顺序合起来,从而形成最后排好序的数组。代码实现:
而在"治"的阶段,又把分成的多个数组两两按顺序合起来,从而形成最后排好序的数组。代码实现:public class Merge { public static int[] mergeSort(int[] arr,int left,int right,int[] tmp){ if (left //只要left //取数组中间值下标 int mid = left+((right-left)/2); //对数组中间元素左侧递归切分 mergeSort(arr,left,mid,tmp); //对数组中间元素右侧递归切分 mergeSort(arr,mid+1,right,tmp); //merge是合并的操作 merge(arr,left,mid,right,tmp); } return arr; } //合并的方法 public static void merge(int[] arr,int left,int mid,int right,int[] tmp){ int i = left;//左边开始的下标 int j = mid+1;//右边开始的下标 int t = 0;//临时数组tmp的开始下标 while(i<=mid&&j<=right){//说明左右两个数组都有数据 if (arr[i]<=arr[j]){ tmp[t]=arr[i]; t++; i++; }else{ tmp[t]=arr[j]; t++; j++; } } //不满足第一个while条件说明有一侧数据已经全部拷贝到tmp数组中了 while (i<=mid){//说明左边数据还有数,右边数组已空,将左边数组中的数依次放入临时数组 tmp[t]=arr[i]; i++; t++; } while(j<=right){ tmp[t]=arr[j]; j++; t++; } //将本次的tmp数组的数据拷贝到原数组arr中 t=0; //注意这里原数组下标tmpLeft不从0开始,而是从left开始 int tmpLeft = left; while (tmpLeft<=right){ arr[tmpLeft]=tmp[t]; t++; tmpLeft++; } }}下面用分析一下归并排序的好坏:
(1)归并排序是否是稳定排序算法
从上面的代码中我们可以看出,要判断归并排序是不是稳定关键要看merge()函数,在合并的过程中,由于arr[left,mid] 中元素的下标都小于 arr[mid+1,right] 的下标,我们的判断条件是:if (arr[i]<=arr[j]){tmp[t]=arr[i];t++;i++;},如果有相同的元素,下标小的合并时放入tmp数组的下标也小,在合并前后顺序是不变的,所以归并排序也是一种稳定的排序算法。
(2)归并排序的时间复杂度是多少
由于归并排序采用了递归,假设原始数组排序为问题a,两个子数组排序分别为问题b和问题c,对应的求解时间分别是 T(a), T(b) 和 T( c),那么就有:
T(a)=T(b)+T(c)+K其中,K为子问题b和子问题c合并成问题a所花费的时间。
假设对 n 个元素进行归并排序需要的时间是 T(n),那分解成两个子数组排序的时间都是 T(n/2)。merge() 函数合并两个有序子数组的时间复杂度是 O(n)。所以,套用前面的公式,归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1时,只需要常量级的执行时间,所以表示为C。T(n) = 2*T(n/2) + n;n>1分解得:
T(n) = 2*T(n/2) + n = 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n = 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n = 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n ...... = 2^k * T(n/2^k) + k * n ......得到 T(n) = 2^kT(n/2^k)+kn。当 T(n/2^k)=T(1) 时,也就是 n/2^k=1,我们得到 k=log2n 。将 k 值代入上面的公式,得到 T(n)=Cn+nlog2n 。如果我们用大 O 标记法来表示的话,T(n) 就等于 O(nlogn)。所以归并排序的时间复杂度是 O(nlogn)。
归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
(3)归并排序的空间复杂度是多少
从上面分析可以看出,每次merge都需要一个和原始数组大小相同的tmp数组。所以归并排序并不是一个原地排序算法。
那么它的空间复杂度如何计算呢?尽管每次merge都需要申请一块和原始数组一样大的内存空间,但是合并完成之后,这个空间也就释放了。在任意时刻,只有一个函数在执行,也就只有一个临时数组在使用,所有临时空间最大也就是存放n个元素,所以空间复杂度是O(n)。
二、快速排序
快排利用的也是分治的思想。如果要排序数组中begin到end之间的一组数据,我们选择begin到end之间的一个数据作为分区点(pivot)。遍历begin到end之间的数据,将小于pivot的放到左边,大于pivot的放到右边。经过这个步骤,数组begin到end之间就被分成了三个部分,begin到p-1之间的都是小于pivot的,中间是pivot,p+1到end之间的都是大于pivot的。
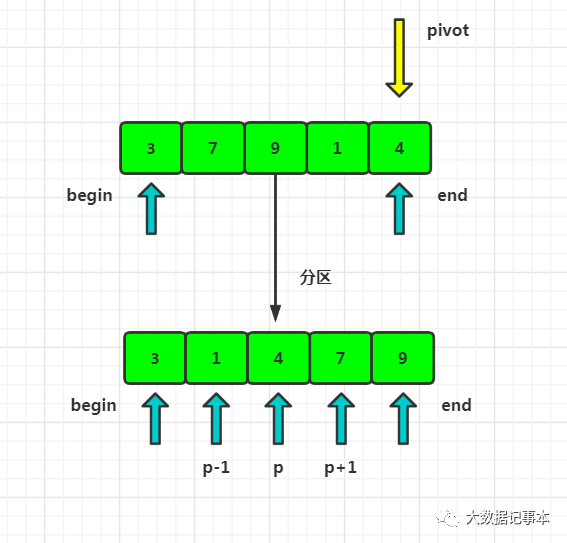
根据分治、递归的处理思想,我们可以用递归排序下标从 begin 到 p-1 之间的数据和下标从 p+1 到end 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
思路分析:
这里定义一个 partition() 分区函数。partition() 分区函数就是随机选择一个元素作为 pivot(一般情况下,可以选择 begin 到end区间的最后一个元素),然后对 arr[begin…end]分区,函数返回 pivot 在数组中的下标。
为了让快排实现原地排序,即空间复杂度为O(1),这里的分区函数partition()必须是一个原地分区函数。它的实现思路如下:
定义一个游标i,将arr[begin,end-1]分成两部分,arr[begin...i-1]的元素都是小于pivot的,称为“已处理区域”,arr[i...end-1]是“未处理区域”。每次都从未处理区域arr[i...end-1]取一个元素arr[j],与pivot对比,如果小于等于pivot,则将其加入到已处理区间的尾部,即arr[i]的位置,然后i后移。遍历结束后,i对应的位置就是排序后pivot的位置,所以交换arr[i]和pivot,此时pivot左边的数都小于等于pivot,右边的数都大于pivot。
图解:
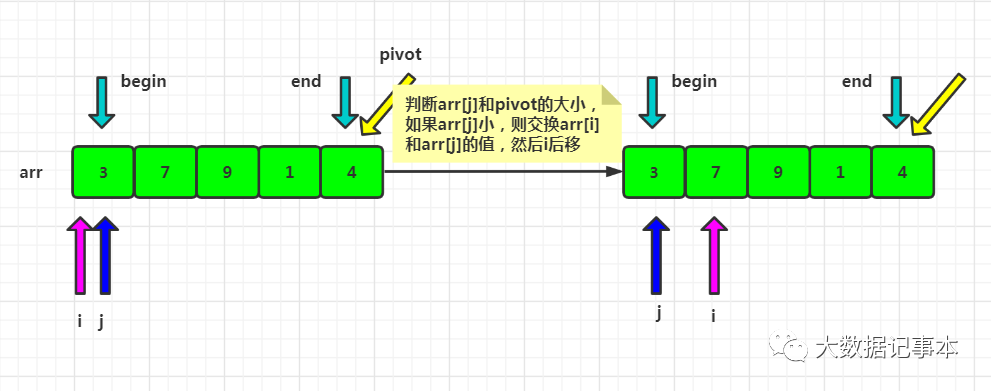
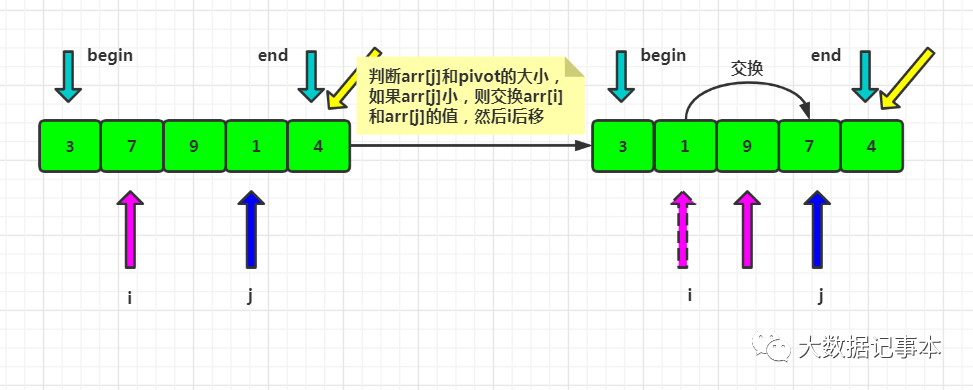
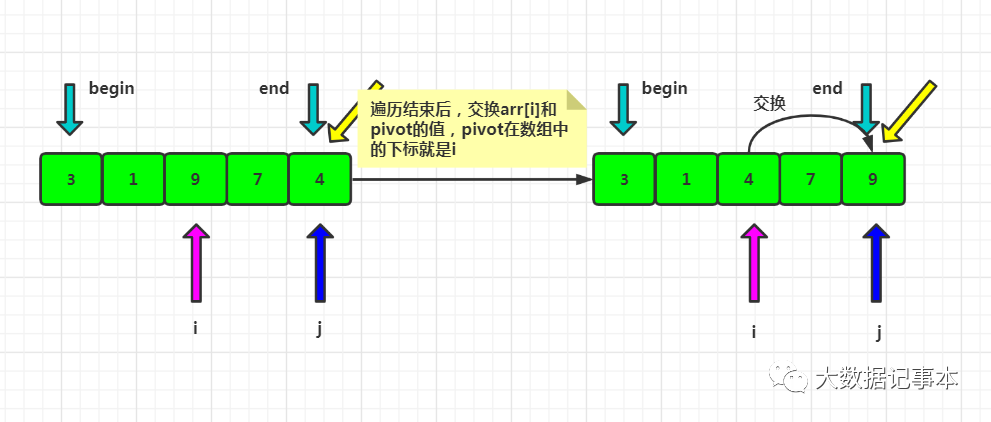
代码实现:
public class Quick { public static int[] quickSort(int[] arr,int begin,int end){ //递归必须满足条件:起始值小于终止值 if(begin //这个方法是确定数组哨兵在排序后的最终位置下标,由于哨兵左边的数都小于哨兵,右边的数都大于哨兵,所以对两边子数组进行递归 int index = partition(arr,begin,end); //对左边的子数组进行递归 quickSort(arr,begin,index-1); //对右边的数组进行递归 quickSort(arr,index+1,end); } return arr; } public static int partition(int[] arr,int begin,int end){ //将数组的最后一个元素作为哨兵 int pivot = arr[end]; //i为起始坐标,注意不一定是(-1) int i = begin ; //对数组进行遍历,j从数组的第一个下标开始,当j对应元素小于哨兵时,交换i和j对应元素,然后i后移 for (int j = begin; j //这里j从begin开始,而不是从0开始 if(arr[j]<=pivot){//这里注意是小于等于 int tmp = arr[i]; arr[i]=arr[j]; arr[j]=tmp; i++; } } //遍历结束后,交换arr[i]和哨兵的值 int tmp = arr[i]; arr[i]=arr[end];//这里不能用pivot来代替arr[end] arr[end]= tmp; //i就是哨兵最终排序后对应的下标 return i; }}总结:
| 原地排序 | 稳定 | 最好时间复杂度 | 最差时间复杂度 | 平均时间复杂度 | |
| 快速排序 | 是 | 否 | O(nlogn) | O(n^2) | O(nlogn) |
| 归并排序 | 否 | 是 | O(nlogn) | O(nlogn) | O(nlogn) |
对于巨大的数据集,如果要求TopN这种操作,由于不能把数据一次性读进内存,快排无法发挥作用,这时可以采取归并的方法,将大的数据集分成多个小的数据集,然后分别求TopN再进行归并,最后从归并的结果中求出TopN。
参考链接:https://time.geekbang.org/column/article/41913