建站工具 比较/2023年5月最新疫情
前言:在上一篇文章中,我们介绍了在http://PM2.5.in这个网站采集空气质量的数据,本篇文章是对其产生的一些问题的另一种解决方案,提供更加权威的数据采集。
技术框架:selenium、json、etree
这里的selenium是一种自动化测试的工具,它可以帮助我们模拟浏览器打开网页并获取网页数据,本文之所以选择这种方式进行,是因为以requests方式直接请求无法获取到正确的数据,这个网页的数据是动态加载,需要用户执行点击操作才会被请求
我们还是按照常规套路来分析下这个网站,打开F12,看下这个网站的数据请求
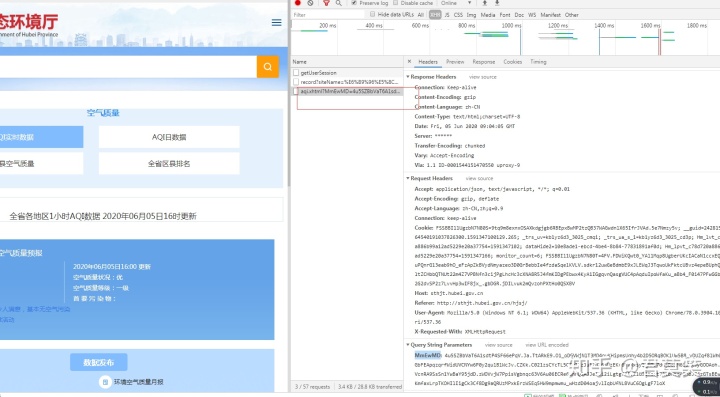
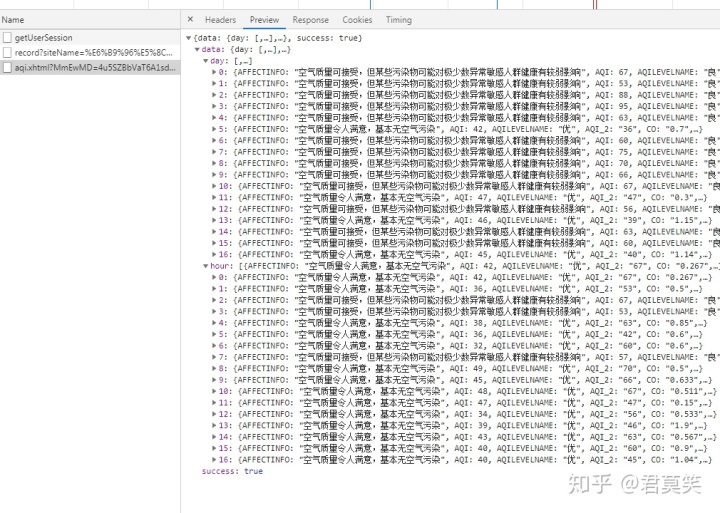
可以发现这个网站的数据的请求接口,但当我们直接用requests去请求这个接口,会发现无法获取正确的数据,原因是这个网站采用了MmEwMD这个值进行了反爬虫,这个是一个比较常见的反爬虫措施,他这个值是在发起请求时动态生成的,最简单的解决这个问题的办法就是采用selenium之类的模拟浏览器方法进行请求,这样的话,发出的请求也会自动带上这个参数
请求的代码如下图所示
driverPath = 'browserchromedriver.exe'options = webdriver.ChromeOptions()options.add_experimental_option("excludeSwitches", ["enable-automation"])options.add_experimental_option('useAutomationExtension', False)# options.add_argument(('--proxy-server=http://' + ip))browser = webdriver.Chrome(options=options, executable_path=driverPath)browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})browser.get(self.url)html = browser.page_sourcebrowser.quit()# print(html)reponse = etree.HTML(html)data = reponse.xpath('//body/text()')[0]json_data = json.loads(data)我们通过调用谷歌浏览器直接请求对应的页面,获取到数据后,关闭浏览器,通过etree解析网页结果,通过观察发现,我们获取到的数据是json数组,因此我们使用json解析数据,然后将对应的数据存储到数据库
result_list = json_data['data']['hour']print(result_list)for result in result_list:item = dict()item['affect'] = result['AFFECTINFO']item['action'] = result['SUGGEST']if('AQIPRIMPOLLUTE' in result):item['primary_pollutant'] = result['AQIPRIMPOLLUTE']else:item['primary_pollutant'] = '无'item['AQI'] = result['AQI']item['PM2.5/1h'] = result['PM25']item['PM10/1h'] = result['PM10']item['CO/1h'] = result['CO']item['NO2/1h'] = result['NO2']item['O3/1h'] = result['O3']item['O3/8h'] = result['O3_2']item['SO2/1h'] = result['SO2']item['city_name'] = result['POINTNAME']item['level'] = result['CODEAQILEVEL']+'('+result['AQILEVELNAME']+')'item['live_data_time'] = result['MONITORTIME']item['live_data_time'] = datetime.datetime.strptime(item['live_data_time'], "%Y年%m月%d日%H") update_time = item['live_data_time'].strftime('%Y-%m-%d %H:%M:%S')item['live_data_unit'] = 'μg/m3(CO为mg/m3)'if(item['city_name'] in city_config):self.save_mysql(item)success_count = success_count+1log_text = '采集的城市:{},采集的结果:{}'.format(item['city_name'],'成功')self.save_log({'log_type':'0','log_text':log_text})self.save_log({'log_type':'3','log_text':log_text})self.update_spider_time(update_time)# 存储运行日志def save_log(self,item):sql = 'INSERT INTO log(log_text,log_type,created_time) VALUES (%s,%s,%s)'values = [item['log_text'],item['log_type'],datetime.datetime.now()]self.cursor.execute(sql,values)self.conn.commit()def save_mysql(self,item):# 查询数据库已存在的数据query_sql = 'select count(1) as count from kongqizhiliang where city_name= %s and live_data_time = %s'values = [item['city_name'],item['live_data_time']]self.cursor.execute(query_sql,values)data = self.cursor.fetchone()# 如果不存在同一城市同一时刻更新的数据,则新增if(data['count'] == 0):sql = ("INSERT kongqizhiliang(city_name,level,live_data_time,live_data_unit,AQI,PM25_1h,PM10_1h,CO_1h"",NO2_1h,O3_1h,O3_8h,SO2_1h,affect,primary_pollutant,action"") VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")values =[item['city_name'],item['level'],item['live_data_time'],item['live_data_unit'],item['AQI'],item['PM2.5/1h'],item['PM10/1h'],item['CO/1h'],item['NO2/1h'],item['O3/1h'],item['O3/8h'],item['SO2/1h'],item['affect'],item['primary_pollutant'],item['action']] self.cursor.execute(sql,values)self.conn.commit()其实当初这个反爬虫措施也困扰了我一段时间的,我这里采用的是最简单的方法解决,虽然效率不高,但能解决我的需求
完整代码如下:其中部分代码是可以不需要的,必须redis和config那个,你们自己改一下,不会的可以问我,这个是当时给别人毕设做的,还有其他功能,所以会有一些其他的
"""
采集空气质量的数据
目标网站:http://sthjt.hubei.gov.cn/hjsj/
"""
import requests
from lxml import etree
import re
from xpinyin import Pinyin
import pymysql
import sys
from settings.config import *
from utils import RedisUtil
import datetime
import json
from selenium import webdriverclass kongqizhiliang:DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}url = 'http://sthjt.hubei.gov.cn/wcmapi/service/aqi.xhtml'redis_key = 'kongqi:config_city'update_time = 'kongqi:update_time'# 汉字转拼音pinyin = Pinyin()def __init__(self):self.conn = pymysql.connect(host=host, port=port, user=user, passwd=passwd, db=db, charset=charset)self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)# 将城市名转化为codedef get_code(self,city_name):return self.pinyin.get_pinyin(city_name, '' )def get_city_config(self):redis_util = RedisUtil.get_redis()city_list = redis_util.list_get_range(self.redis_key)return city_listdef update_spider_time(self,update_time):redis_util = RedisUtil.get_redis()redis_util.str_set(self.update_time,update_time)def get_data(self): city_config = self.get_city_config()log_text = '采集开始,准备采集的城市:{},计划采集的数据量:{}'.format(city_config,len(city_config))self.save_log({'log_type':'2','log_text':log_text})success_count = 0update_time = ''driverPath = 'browserchromedriver.exe'options = webdriver.ChromeOptions()options.add_experimental_option("excludeSwitches", ["enable-automation"])options.add_experimental_option('useAutomationExtension', False)# options.add_argument(('--proxy-server=http://' + ip))browser = webdriver.Chrome(options=options, executable_path=driverPath)browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})browser.get(self.url)html = browser.page_sourcebrowser.quit()# print(html)reponse = etree.HTML(html)data = reponse.xpath('//body/text()')[0]json_data = json.loads(data)# print(json_data)result_list = json_data['data']['hour']print(result_list)for result in result_list:item = dict()item['affect'] = result['AFFECTINFO']item['action'] = result['SUGGEST']if('AQIPRIMPOLLUTE' in result):item['primary_pollutant'] = result['AQIPRIMPOLLUTE']else:item['primary_pollutant'] = '无'item['AQI'] = result['AQI']item['PM2.5/1h'] = result['PM25']item['PM10/1h'] = result['PM10']item['CO/1h'] = result['CO']item['NO2/1h'] = result['NO2']item['O3/1h'] = result['O3']item['O3/8h'] = result['O3_2']item['SO2/1h'] = result['SO2']item['city_name'] = result['POINTNAME']item['level'] = result['CODEAQILEVEL']+'('+result['AQILEVELNAME']+')'item['live_data_time'] = result['MONITORTIME']item['live_data_time'] = datetime.datetime.strptime(item['live_data_time'], "%Y年%m月%d日%H") update_time = item['live_data_time'].strftime('%Y-%m-%d %H:%M:%S')item['live_data_unit'] = 'μg/m3(CO为mg/m3)'if(item['city_name'] in city_config):self.save_mysql(item)success_count = success_count+1log_text = '采集的城市:{},采集的结果:{}'.format(item['city_name'],'成功')self.save_log({'log_type':'0','log_text':log_text})self.save_log({'log_type':'3','log_text':log_text})self.update_spider_time(update_time)# 存储运行日志def save_log(self,item):sql = 'INSERT INTO log(log_text,log_type,created_time) VALUES (%s,%s,%s)'values = [item['log_text'],item['log_type'],datetime.datetime.now()]self.cursor.execute(sql,values)self.conn.commit()def save_mysql(self,item):# 查询数据库已存在的数据query_sql = 'select count(1) as count from kongqizhiliang where city_name= %s and live_data_time = %s'values = [item['city_name'],item['live_data_time']]self.cursor.execute(query_sql,values)data = self.cursor.fetchone()# 如果不存在同一城市同一时刻更新的数据,则新增if(data['count'] == 0):sql = ("INSERT kongqizhiliang(city_name,level,live_data_time,live_data_unit,AQI,PM25_1h,PM10_1h,CO_1h"",NO2_1h,O3_1h,O3_8h,SO2_1h,affect,primary_pollutant,action"") VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)")values =[item['city_name'],item['level'],item['live_data_time'],item['live_data_unit'],item['AQI'],item['PM2.5/1h'],item['PM10/1h'],item['CO/1h'],item['NO2/1h'],item['O3/1h'],item['O3/8h'],item['SO2/1h'],item['affect'],item['primary_pollutant'],item['action']] self.cursor.execute(sql,values)self.conn.commit()if __name__ == "__main__":app = kongqizhiliang()app.get_data()本文首发于
爬虫:利用selenium采集某某环境网站的空气质量数据www.bizhibihui.com