动态网站设计用那个软件/百度快照seo

在实际开发工作中经常遇到,根据词表或映射表,查找或替换文本中内容,比较简单处理方法就是逐词匹配,这种处理方式不是高效的,而且代码写起来也会感觉很啰嗦,使用FlashText能够很好的帮助我们解决这个问题。
算法原理
FlashText算法是一个高效的字符搜索和替换算法,此算法的时间复杂度不依赖于搜索或替换的字符的数量。比如,对于一个文档有N个字符,和一个有M个词的关键词库,那么时间复杂度就是O(N)。这个算法比我们一般的正则匹配法快很多,因为正则匹配的时间复杂度是O(M*N)。这个算法还遵循最长匹配原则。
FlashText 是一种基于 Trie 字典数据结构和 Aho Corasick 的算法,具体算法原理,这里不展开了,感兴趣的可以仔细了解一下。
关于FlashText与正则对比,下面通过两张图展示一下:
使用FlashText与正则查找关键词用时对比
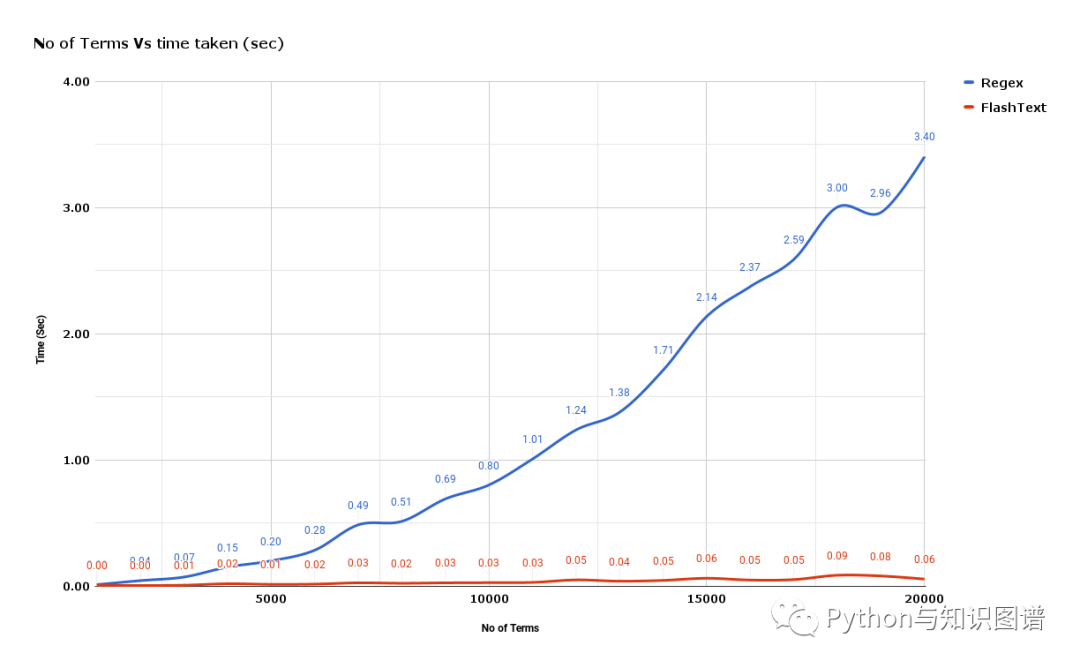
使用FlashText与正则替换关键词用时对比
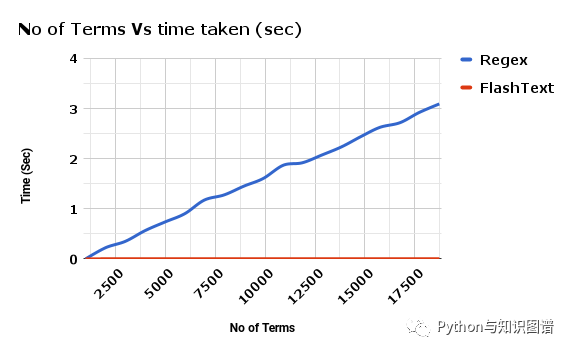
安装
pip install flashtext主要API
from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> # keyword_processor.add_keyword(, )>>> keyword_processor.add_keyword('Big Apple', 'New York')>>> keyword_processor.add_keyword('Bay Area')>>> keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')>>> keywords_found>>> # ['New York', 'Bay Area']2. 替换词组
>>> keyword_processor.add_keyword('New Delhi', 'NCR region')>>> new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')>>> new_sentence>>> # 'I love New York and NCR region.'3. 大小写敏感,通过case_sensitive设置
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor(case_sensitive=True)>>> keyword_processor.add_keyword('Big Apple', 'New York')>>> keyword_processor.add_keyword('Bay Area')>>> keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.')>>> keywords_found>>> # ['Bay Area']4. 获取匹配到字符起始位置,通过span_info设置
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_processor.add_keyword('Big Apple', 'New York')>>> keyword_processor.add_keyword('Bay Area')>>> keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.', span_info=True)>>> keywords_found>>> # [('New York', 7, 16), ('Bay Area', 21, 29)]5. 获取关键词提取时提取信息,包含匹配字符及归一化关键词
>>> from flashtext import KeywordProcessor>>> kp = KeywordProcessor()>>> kp.add_keyword('Taj Mahal', ('Monument', 'Taj Mahal'))>>> kp.add_keyword('Delhi', ('Location', 'Delhi'))>>> kp.extract_keywords('Taj Mahal is in Delhi.')>>> # [('Monument', 'Taj Mahal'), ('Location', 'Delhi')]>>> # NOTE: replace_keywords feature won't work with this.6. 不包含多词归一化的关键词提取
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_processor.add_keyword('Big Apple')>>> keyword_processor.add_keyword('Bay Area')>>> keywords_found = keyword_processor.extract_keywords('I love big Apple and Bay Area.')>>> keywords_found>>> # ['Big Apple', 'Bay Area']7. 增加多词词典
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_dict = {>>> "java": ["java_2e", "java programing"],>>> "product management": ["PM", "product manager"]>>> }>>> # {'clean_name': ['list of unclean names']}>>> keyword_processor.add_keywords_from_dict(keyword_dict)>>> # Or add keywords from a list:>>> keyword_processor.add_keywords_from_list(["java", "python"])>>> keyword_processor.extract_keywords('I am a product manager for a java_2e platform')>>> # output ['product management', 'java']8. 删除关键词
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_dict = {>>> "java": ["java_2e", "java programing"],>>> "product management": ["PM", "product manager"]>>> }>>> keyword_processor.add_keywords_from_dict(keyword_dict)>>> print(keyword_processor.extract_keywords('I am a product manager for a java_2e platform'))>>> # output ['product management', 'java']>>> keyword_processor.remove_keyword('java_2e')>>> # you can also remove keywords from a list/ dictionary>>> keyword_processor.remove_keywords_from_dict({"product management": ["PM"]})>>> keyword_processor.remove_keywords_from_list(["java programing"])>>> keyword_processor.extract_keywords('I am a product manager for a java_2e platform')>>> # output ['product management']9. 查看关键词词条数
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_dict = {>>> "java": ["java_2e", "java programing"],>>> "product management": ["PM", "product manager"]>>> }>>> keyword_processor.add_keywords_from_dict(keyword_dict)>>> print(len(keyword_processor))>>> # output 410. 查看词条是否在词典中
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_processor.add_keyword('j2ee', 'Java')>>> 'j2ee' in keyword_processor>>> # output: True>>> keyword_processor.get_keyword('j2ee')>>> # output: Java>>> keyword_processor['colour'] = 'color'>>> keyword_processor['colour']>>> # output: color11. 获取词典中所有关键词
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_processor.add_keyword('j2ee', 'Java')>>> keyword_processor.add_keyword('colour', 'color')>>> keyword_processor.get_all_keywords()>>> # output: {'colour': 'color', 'j2ee': 'Java'}12. 设置或增加词分隔符,这个方法更适用于英文文本
>>> from flashtext import KeywordProcessor>>> keyword_processor = KeywordProcessor()>>> keyword_processor.add_keyword('Big Apple')>>> print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))>>> # ['Big Apple']>>> keyword_processor.add_non_word_boundary('/')>>> print(keyword_processor.extract_keywords('I love Big Apple/Bay Area.'))>>> # []参考链接:
https://github.com/vi3k6i5/flashtext
推荐阅读
这个NLP工具,玩得根本停不下来
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
从数据到模型,你可能需要1篇详实的pytorch踩坑指南
如何让Bert在finetune小数据集时更“稳”一点
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
Node2Vec 论文+代码笔记
模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
中文命名实体识别工具(NER)哪家强?
学自然语言处理,其实更应该学好英语
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧?