网页设计的基本结构/优化网站排名软件
map的使用
- map
- 1、map简介
- 2、map的功能
- 3、使用map
- 4、map的构造函数
- 5、数据的插入和遍历
- 6、map的查找
- 7、从map中删除元素
- 8、排序-map中的sort问题
- 9、map的基本操作函数:
- 10.注意
- 11.源码分析
map
map是STL的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据 处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。这里说下map内部数据的组织,map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的,后边我们会见识到有序的好处。
建议先看看数据结构-二分搜索树14和数据结构-平衡二叉树01-15
红黑树代码问题太难了,不打算搞了,划不来。这里知道其原理就行了,主要学会使用就好了。
1、map简介
map是一类关联式容器。它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响。
对于迭代器来说,可以修改实值,而不能修改key。
2、map的功能
自动建立Key-value的对应。key 和 value可以是任意你需要的类型。
根据key值快速查找记录,查找的复杂度基本是Log(N),如果有1000个记录,最多查找10次,1,000,000个记录,最多查找20次。
3、使用map
使用map得包含map类所在的头文件
#include <map> //注意,STL头文件没有扩展名.h
map对象是模板类,需要关键字和存储对象两个模板参数:
std:map<int,string> personnel;
这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.
为了使用方便,可以对模板类进行一下类型定义,
typedef map<int,CString> UDT_MAP_INT_CSTRING;UDT_MAP_INT_CSTRING enumMap;
4、map的构造函数
map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:
map<int, string> mapStudent;
5、数据的插入和遍历
在构造map容器后,我们就可以往里面插入数据了。这里讲三种插入数据的方法:
void main()
{map<int, string> m_map;//1.通过pairm_map.insert(std::pair<int, string>(1, "jacktang1"));m_map.insert(std::pair<int, string>(3, "jacktang3"));//2.通过pairm_map.insert(make_pair(5, "jacktang4"));m_map.insert(make_pair(2, "jacktang2"));//3.通过数组m_map[4] = "jacktang4";m_map[5] = "jacktang5";//4.value_typem_map.insert(map<int, string>::value_type(7, "jacktang7"));m_map.insert(map<int, string>::value_type(6, "jacktang6"));//5.数据的遍历1for (auto node :m_map){cout << node.first << " " << node.second << endl;}//注意:1.用数组方式插入时候会覆盖之前的数据。//注意:2.用数组以外的方式插入如果有重复的就不插入了m_map[4] = "jacktang4444";m_map.insert(map<int, string>::value_type(7, "jacktang7777"));cout << "***********************华丽的Ty分割线***********************\n";//6.数据的遍历2for (auto it = m_map.begin(); it != m_map.end();it++){cout << it->first << " " << it->second << endl;}cout << "***********************华丽的Ty分割线***********************\n";//7.反向遍历for (auto rit = m_map.rbegin(); rit != m_map.rend();rit++){cout << rit->first << " " << rit->second << endl;}system("pause");
}
结果:

从结果可以看出使用数组的方式插入会覆盖之前的相同key的值,而除此之外的插入方法不会覆盖。
从结果也可以看出map中的数据是有序的。
注意:使用数组的方式取元素的时候,如果没有这个元素,map容器会插入一个。
6、map的查找
在这里我们将体会,map在数据插入时保证有序的好处。
要判定一个数据(关键字)是否在map中出现的方法比较多,这里标题虽然是数据的查找,在这里将穿插着大量的map基本用法。
用find函数来定位数据出现位置,它返回的一个迭代器,当数据出现时,它返回数据所在位置的迭代器,如果map中没有要查找的数据,它返回的迭代器等于end函数返回的迭代器。
代码示例:
void main()
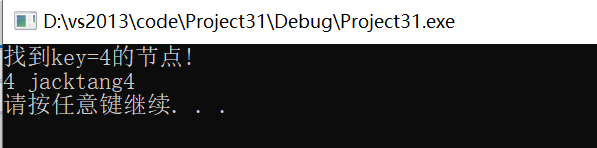
{map<int, string> m_map;//1.通过pairm_map.insert(std::pair<int, string>(1, "jacktang1"));m_map.insert(std::pair<int, string>(3, "jacktang3"));//2.通过pairm_map.insert(make_pair(5, "jacktang4"));m_map.insert(make_pair(2, "jacktang2"));//3.通过数组m_map[4] = "jacktang4";m_map[5] = "jacktang5";//4.value_typem_map.insert(map<int, string>::value_type(7, "jacktang7"));m_map.insert(map<int, string>::value_type(6, "jacktang6"));auto it = m_map.find(4);if (it != m_map.end()){cout << "找到key=4的节点!" << endl;cout << it->first << " " << it->second << endl;}system("pause");
}
结果:
7、从map中删除元素
移除某个map中某个条目用erase()
该成员方法的定义如下:
iterator erase(iterator it);//通过一个条目对象删除
iterator erase(iterator first,iterator last)//删除一个范围
size_type erase(const Key&key);//通过关键字删除
clear()就相当于enumMap.erase(enumMap.begin(),enumMap.end());
这里要用到erase函数,它有三个重载了的函数,下面在例子中详细说明它们的用法:
void main()
{map<int, string> m_map;//1.通过pairm_map.insert(std::pair<int, string>(1, "jacktang1"));m_map.insert(std::pair<int, string>(3, "jacktang3"));//2.通过pairm_map.insert(make_pair(5, "jacktang4"));m_map.insert(make_pair(2, "jacktang2"));//3.通过数组m_map[4] = "jacktang4";m_map[5] = "jacktang5";//4.value_typem_map.insert(map<int, string>::value_type(7, "jacktang7"));m_map.insert(map<int, string>::value_type(6, "jacktang6"));auto it = m_map.find(4);if (it != m_map.end()){cout << "找到key=4的节点!" << endl;cout << it->first << " " << it->second << endl;}cout << "删除前:\n";for (auto node : m_map){cout << node.first << " " << node.second << endl;}//1.使用迭代器删除m_map.erase(it);cout << "使用迭代器删除后遍历:\n";for (auto node : m_map){cout << node.first << " " << node.second << endl;}//2.使用键值删除m_map.erase(7);cout << "使用迭代器删除7后遍历:\n";for (auto node : m_map){cout << node.first << " " << node.second << endl;}m_map.erase(m_map.begin(), m_map.end());cout << "使用区间删除begin->end后:\n";for (auto node : m_map){cout << node.first << " " << node.second << endl;}system("pause");
}
结果:

8、排序-map中的sort问题
map中的元素是自动按Key升序排序,所以不能对map用sort函数;
这里要讲的是一点比较高深的用法了,排序问题,STL中默认是采用小于号来排序的,以上代码在排序上是不存在任何问题的,因为上面的关键字是int 型,它本身支持小于号运算,在一些特殊情况,比如关键字是一个结构体,涉及到排序就会出现问题,因为它没有小于号操作,insert等函数在编译的时候过 不去,下面给出个方法解决这个问题:
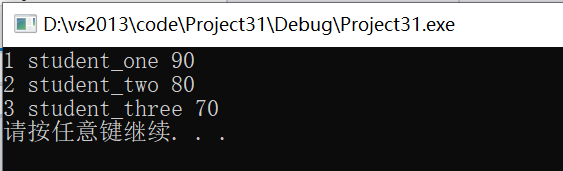
typedef struct tagStudentinfo{int niD;string strName;bool operator < (tagStudentinfo const& _A) const{ //这个函数指定排序策略,按niD排序,如果niD相等的话,按strName排序 if (niD < _A.niD) return true;if (niD == _A.niD)return strName.compare(_A.strName) < 0;return false;}}Studentinfo, *PStudentinfo; //学生信息 int main(){int nSize; //用学生信息映射分数 map<Studentinfo, int>mapStudent;map<Studentinfo, int>::iterator iter;Studentinfo studentinfo;studentinfo.niD = 1;studentinfo.strName = "student_one";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 90));studentinfo.niD = 3;studentinfo.strName = "student_three";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 70));studentinfo.niD = 2;studentinfo.strName = "student_two";mapStudent.insert(pair<Studentinfo, int>(studentinfo, 80));for (iter = mapStudent.begin(); iter != mapStudent.end(); iter++)cout << iter->first.niD << ' ' << iter->first.strName << ' ' << iter->second << endl;system("pause");return 0;
}
结果:
要说明的是,map中由于它内部有序,由红黑树保证,因此很多函数执行的时间复杂度都是log2N的,如果用map函数可以实现的功能,而STL Algorithm也可以完成该功能,建议用map自带函数,效率高一些。
9、map的基本操作函数:
C++ maps是一种关联式容器,包含“关键字/值”对
| 成员函数 | 功能 |
|---|---|
| begin() | 返回指向map头部的迭代器 |
| clear() | 删除所有元素 |
| count() | 返回指定元素出现的次数 |
| empty() | 如果map为空则返回true |
| end() | 返回指向map末尾的迭代器 |
| equal_range() | 返回特殊条目的迭代器对 |
| erase() | 删除一个元素 |
| find() | 查找一个元素 |
| get_allocator() | 返回map的配置器 |
| insert() | 插入元素 |
| key_comp() | 返回比较元素key的函数 |
| lower_bound() | 返回键值>=给定元素的第一个位置 |
| max_size() | 返回可以容纳的最大元素个数 |
| rbegin() | 返回一个指向map尾部的逆向迭代器 |
| rend() | 返回一个指向map头部的逆向迭代器 |
| size() | 返回map中元素的个数 |
| swap() | 交换两个map |
| upper_bound() | 返回键值>给定元素的第一个位置 |
| value_comp() | 返回比较元素value的函数 |
10.注意
map和set一样是关联式容器,它们的底层容器都是红黑树,区别就在于map的值不作为键,键和值是分开的。它的特性如下:
map以RBTree作为底层容器
所有元素都是键+值存在
不允许键重复
所有元素是通过键进行自动排序的
map的键是不能修改的,但是其键对应的值是可以修改的
在map中,一个键对应一个值,其中键不允许重复,不允许修改,但是键对应的值是可以修改的,原因可以看上面set中的解释。下面就一起来看看STL中的map的源代码。
11.源码分析
map的数据结构
// 默认比较器为less<key>,元素按照键的大小升序排列
template <class Key, class T, class Compare = less<Key>, class Alloc = alloc>
class map {
public:typedef Key key_type; // key类型typedef T data_type; // value类型typedef T mapped_type;typedef pair<const Key, T> value_type; // 元素类型, 要保证key不被修改typedef Compare key_compare; // 用于key比较的函数
private:// 内部采用RBTree作为底层容器typedef rb_tree<key_type, value_type,identity<value_type>, key_compare, Alloc> rep_type;rep_type t; // t为内部RBTree容器
public:// 用于提供iterator_traits<I>支持typedef typename rep_type::const_pointer pointer; typedef typename rep_type::const_pointer const_pointer;typedef typename rep_type::const_reference reference; typedef typename rep_type::const_reference const_reference;typedef typename rep_type::difference_type difference_type; // 注意:这里与set不一样,map的迭代器是可以修改的typedef typename rep_type::iterator iterator; typedef typename rep_type::const_iterator const_iterator;// 反向迭代器typedef typename rep_type::const_reverse_iterator reverse_iterator;typedef typename rep_type::const_reverse_iterator const_reverse_iterator;typedef typename rep_type::size_type size_type;// 常规的返回迭代器函数iterator begin() { return t.begin(); }const_iterator begin() const { return t.begin(); }iterator end() { return t.end(); }const_iterator end() const { return t.end(); }reverse_iterator rbegin() { return t.rbegin(); }const_reverse_iterator rbegin() const { return t.rbegin(); }reverse_iterator rend() { return t.rend(); }const_reverse_iterator rend() const { return t.rend(); }bool empty() const { return t.empty(); }size_type size() const { return t.size(); }size_type max_size() const { return t.max_size(); }// 返回用于key比较的函数key_compare key_comp() const { return t.key_comp(); }// 由于map的性质, value和key使用同一个比较函数, 实际上我们并不使用value比较函数value_compare value_comp() const { return value_compare(t.key_comp()); }// 注意: 这里有一个常见的陷阱, 如果访问的key不存在, 会新建立一个T& operator[](const key_type& k){return (*((insert(value_type(k, T()))).first)).second;}// 重载了==和<操作符,后面会有实现friend bool operator== __STL_NULL_TMPL_ARGS (const map&, const map&);friend bool operator< __STL_NULL_TMPL_ARGS (const map&, const map&);
}
map的操作函数
insert
同set一样,直接调用RBTree的插入函数即可,注意map不允许键值重复,所以调用的是insert_unique
// 对于相同的key, 只允许出现一次, bool标识
pair<iterator,bool> insert(const value_type& x) { return t.insert_unique(x); }
// 在position处
插入元素, 但是position仅仅是个提示, 如果给出的位置不能进行插入,
// STL会进行查找, 这会导致很差的效率
iterator insert(iterator position, const value_type& x)
{return t.insert_unique(position, x);
}
// 将[first,last)区间内的元素插入到map中
template <class InputIterator>
void insert(InputIterator first, InputIterator last) {t.insert_unique(first, last);
}
参考:https://www.cnblogs.com/ZY-Dream/p/10037931.html