做网站现在用什么语言/成都培训机构排名前十
TD可以根据episode的一部分来更新,不必要等到最终结果出来,即不必等到一个episode结束,这是跟上一章介绍的Monte Carlo方法最大的区别
6.1 TD Prediction
- Monte Carlo方法必须要等到episode的结束,才能更新V(St)V(St)
- TD 方法则只需要等到下一个时间步,就可以做更新了
对一个every-visit Monte Carlo method,这称为 constant-α MCconstant-αMC
这里的αα是恒定step-size参数,在第二章中介绍过,使用恒定的step-size是要 给最近的reward更大的权重 。
最简单的TD方法的公式可以表示为,
到了时刻t+1,该公式马上使用当前观察到的reward Rt+1Rt+1 和估计值 V(St+1)V(St+1) 来做更新。其实该TD方法是后面要讲的TD方法的一个特例,TD(0) 或称 one-step TD
蒙特卡洛方法与TD方法的不同点是,蒙特卡洛方法的更新target是GtGt,而TD方法的更新target是Rt+1+γV(St+1)Rt+1+γV(St+1)

由于TD(0)的更新部分基于现有的估计,因此我们说它是一种 bootstrapping 方法。
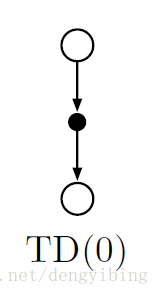
将TD和Monte Carlo更新称为sample updates。因为他们涉及往样本后继状态看一步,使用后继的value和走向后继状态得到的reward来更新原始状态的值。
Sample updates与DP方法的expected updates不同,因为它们基于单个样本后继而不是所有可能后继的完整分布。
TD error,以各种形式出现,贯穿强化学习始终
要计算TD error还是需要等待一个time step的,因为得到t+1时刻的 Rt+1Rt+1和 V(St+1)V(St+1)
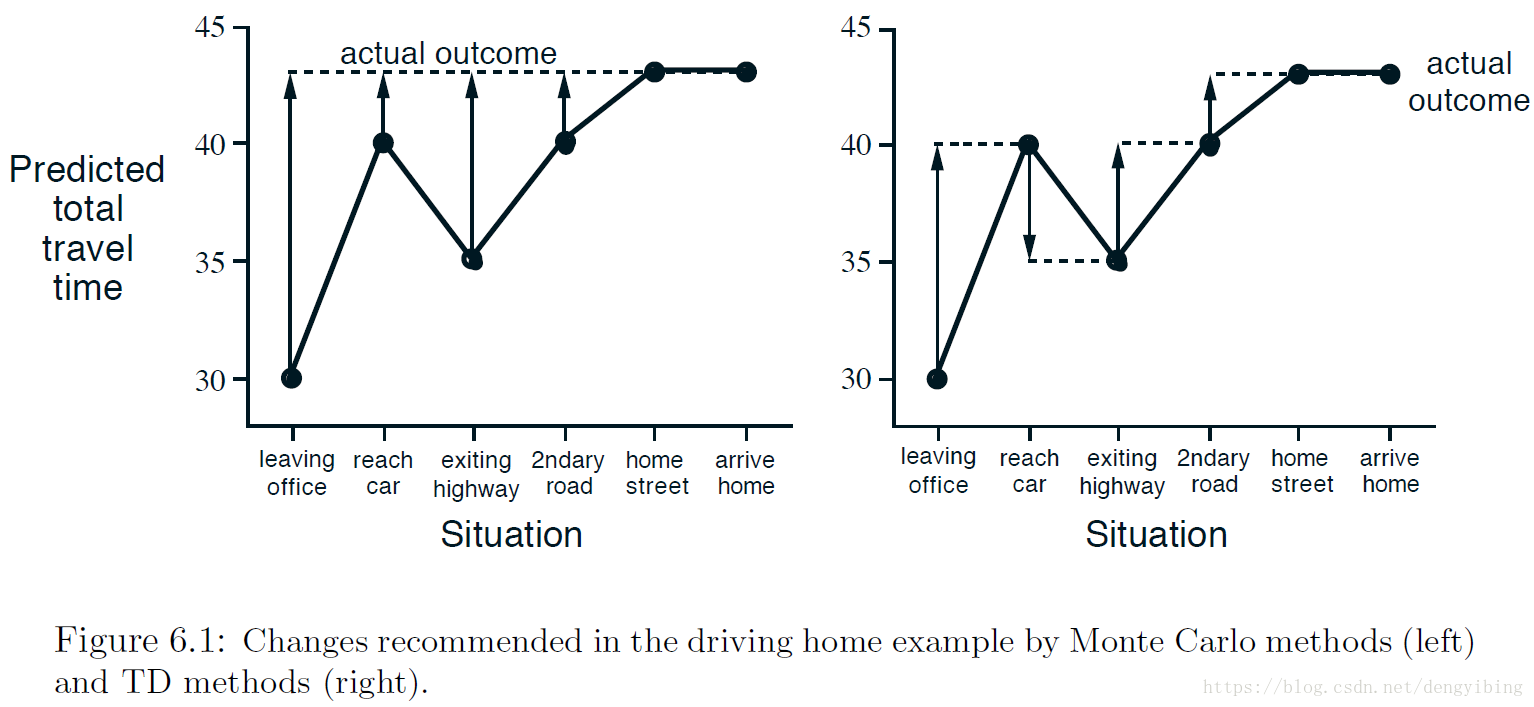
有个很有趣的例子来说明Monte Carlo methods和TD methods的区别。该例子是用开车回家来说明的。对于Monte Carlo方法,只有在完全回家后(一个episode结束后)才能更新每个时间点的状态值;对于TD方法,在有了t+1时刻的估计值就可以更新当前t时刻的状态值。
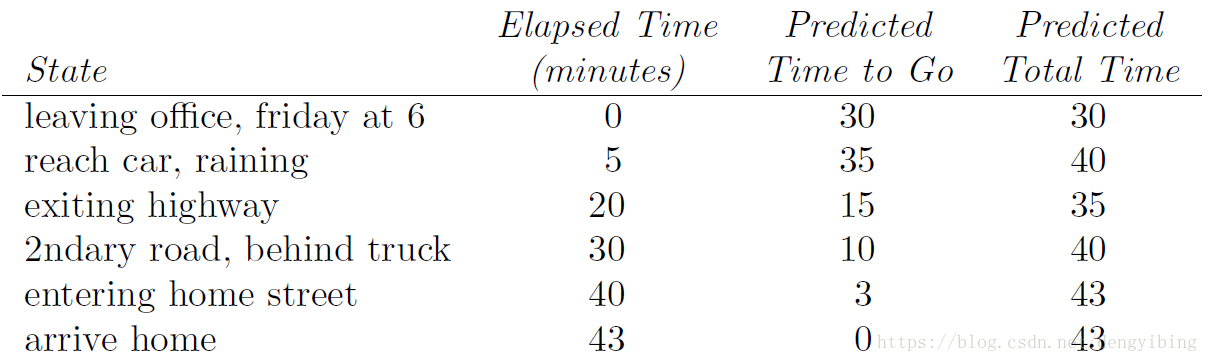
在每个状态时间点,估计要回家要花费的时间
6.2 Advantages of TD Prediction Methods
- 一些蒙特卡洛方法必须ignore或者discount采取实验性行动的事件,这会大大减缓学习速度。 TD方法对这些问题的影响要小得多,因为他们可以从每次转换中学习,而不管后续采取什么行动。
- TD methods也是保证收敛的
- 实践中,TD methods要比constant-α MC收敛的更快
6.3 Optimality of TD(0)
因为每次更新都是在处理了一整个batch的训练数据之后才进行的,所以称为batch updating
batch TD表现的更好的,原因是蒙特卡罗方法仅在有限的方式下才是最优的,但TD在与predict returns更相关的方面是最优的。
Batch Monte Carlo方法总是可以找到最小化训练集上均方误差的估计值,而batch TD(0)始终可以找到对马尔可夫过程的最大似然模型完全正确的估计值。
6.4 Sarsa: On-policy TD Control
在第5章讲到了On-policy和Off-policy方法的特点和区别。
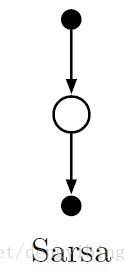
Learn about policy π from experience sampled from π
用来产生样本的policy与被更新的policy是同一个policy

6.5 Q-learning: On-policy TD Control
Learning about policy π from experience sampled from μ
用来产生样本的policy与被更新的policy不是同一个policy,这里下面方框介绍的方法中产生样本的policy是greedy-policy,选择 maxαQ(S′,a)maxαQ(S′,a)

学习到的action-value函数直接近似于最优action-value函数,而与所遵循的policy无关。其实策略只要能保证所有状态都能被访问到,并且被更新就行。
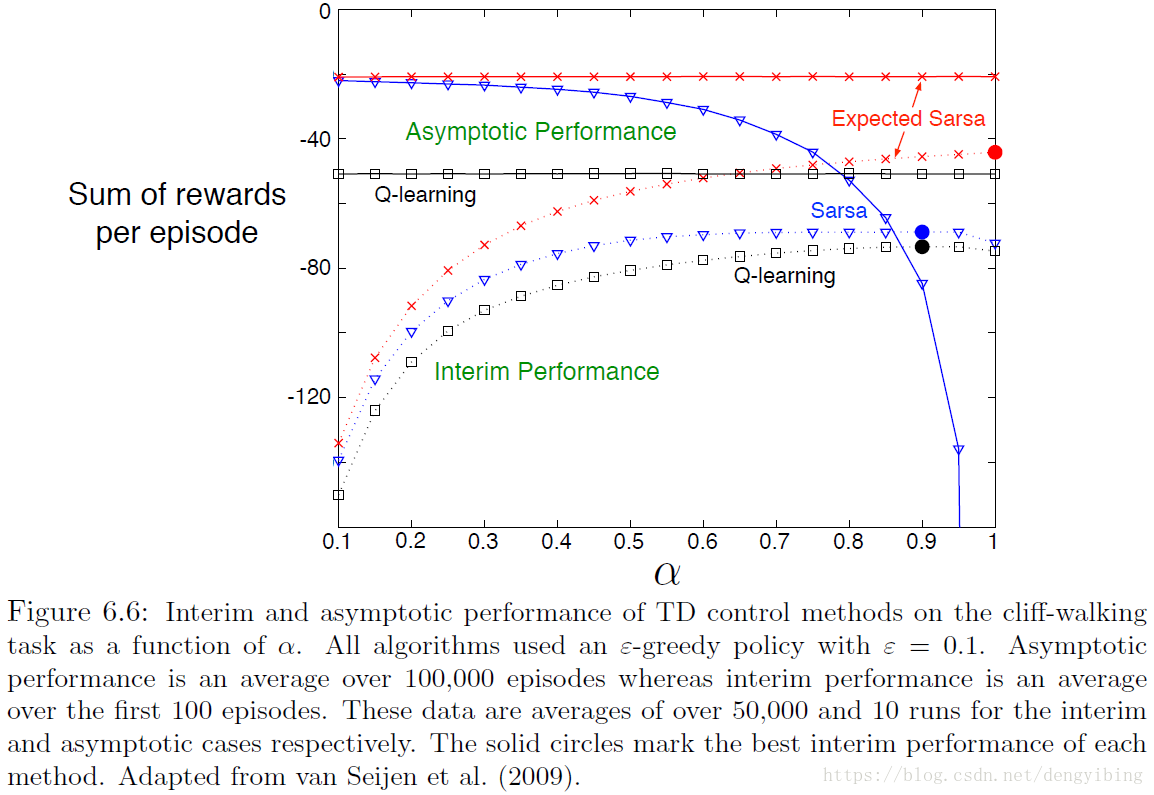
6.6 Expected Sarsa
类似于Q-learning,但是考虑的是在当前策略下接下来每一个动作的可能性,而不是仅仅考虑最大state-action对的动作

除了需要额外的运算,
Expected Sarsa subsumes and generalizes Q-learning while reliably improving over Sarsa.
6.7 Maximization Bias and Double Learning
到目前为止,我们所讨论的所有控制算法都涉及到构建其target policy时的最大化。在Q-learning中target policy是给定当前action values时的greedy policy,即定义的 max 操作;在Sarsa中,policy常常是ε-greedyε-greedy,同样也有最大化的操作。这样的最大化操作可以导致明显的positive bias。我们称之为 maximization bias 。

一种看待这个问题的方法是,这是由于使用了相同的samples(plays)来确定maximizing action和estimate its value。
我们把plays分成两组,用它们来学习两个独立的估计,Q1Q1和Q2Q2,每个都是真实值q(a)q(a) 的估计,所有的a∈Aa∈A。
我们可以使用一个estimate,可以是Q1Q1,来确定maximizing action A∗=argmaxaQ1(a)A∗=argmaxaQ1(a),然后使用另外一个,Q2Q2,来提供the estimate of its value,Q2(A∗)=Q2(argmaxaQ1(a))Q2(A∗)=Q2(argmaxaQ1(a))。
我们也可以重复这个过程,将这两个估计的作用颠倒过来以产生第二个无偏估计 Q1(A∗)=Q1(argmaxaQ2(a))Q1(A∗)=Q1(argmaxaQ2(a))。这两个过程完全平等对待。
这就称为 double learning,最后只要用一个estimate。这个方法使用了双倍的内存,但是计算量却是一样的。
