外贸电商做俄罗斯市场网站/电话百度
CTR 预估中的场景:
如下为FM论文中的截图,是电影评分系统的记录。
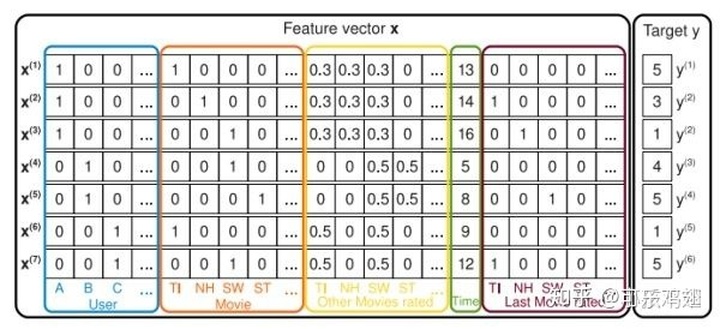
target是用户对电影的评分,其它还有用户id、电影id、评分时间等特征。而用户id,电影id是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。而经过one-hot编码以后,导致样本数据变得很稀疏。尤其是数据量大的时候,有些用户id出现了很少的次数,这样会使得数据更加的稀疏。
那么在这种稀疏数据之上使用传统的构建交叉特征方式(下式右侧)会导致什么问题呢?
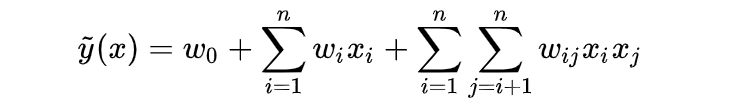
上面提到特征x是非常稀疏的,如NH特征和C特征相乘计算二者的交叉特征,二者相乘之后发现结果全是0,那么交叉权重
这就是在ctr预估中由于数据稀疏导致的训练不充分的问题。
补充:在ctr这类问题中构造交叉特征的必要性:一个简单的例子
如果预测一个商品的点击率:如果有一个用户id,还有一个时间,那么在这个时间上可以提出来节日信息,使用这个用户信息
和节日信息做交叉,那么 中国人 + 双11和日本人 + 双11 这两个特征自然会有比较大的强弱之分。FM&&FFM 就是用于解决上述的数据稀疏导致的训练不充分的问题。
FM
FM论文摘要
1、因式分解机(fm)结合了SVM和因式分解模型二者的优势
2、FM可以像SVM一样处理real value 特征,二者FM还可以处理稀疏的数据,而这里SVM却 是失败了的,FM处理稀疏数据主要机制是:因式分解参数可以对任何两个特征直接做组合。
3、FM可以在线性时间完成计算,而不需要像SVM那样需要对偶去转换。
4、因式分解模型也有其他的,如,SVD++等,这些模型具有的缺点是只能在特定输入数据上进行工作,而且根据不同的任务,模型的计算及优化要分别推导。
介绍:
1、如,推荐系统等问题,SVM几乎没有重要的地位,在这些领域中最好的模型就是矩阵分解模型(matrix factorization),SVM没有在这些领域有所施展的原因是:SVM在稀疏数据的复杂(非线性)核空间中不能构学习到可信赖的参数(超平面)
3、张量分解类模型最大的缺点在于:
不能在标准的预测数据(real valued feature vector)中应用。
特制模型的推导是在特制任务完成,需要精心设计学习算法。
4、FM和其他模型比较如下:
FM在线性时间计算,计算时间与参数是呈线性关系,存储模型的时候也不需要存储训练数据,而SVM需要存储训练数据(支持向量),SVM是在对偶空间中优化。而且FM将其他饮因式分解模型概括在内。
- FM模型
模型公式,d=1,定义如下:
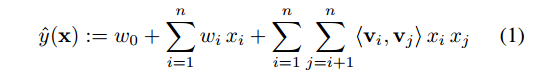
需要估计的参数有W0,Wi,V,<..>是大小为k的向量的点乘。
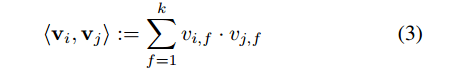
长度为k得向量vi,描述了第i个变量。d=n,描述了捕捉所有n个向量之间的组合关系。
参数描述:
w0 是全局偏置(global bias)
wi 是模型第i个变量的权重、
wij = <vi,vj> 特征i和j的交互,- 数学中的概念:
众所周知的是假如有一个正矩阵W,总是存在一个矩阵V,只要k足够大,总会使得
从式子(1)可以右侧,在计算特征交互的时候,很明显的缺点是遍历计算两两特征直接组合计算复杂度高。于是就是想办法降低计算复杂度。
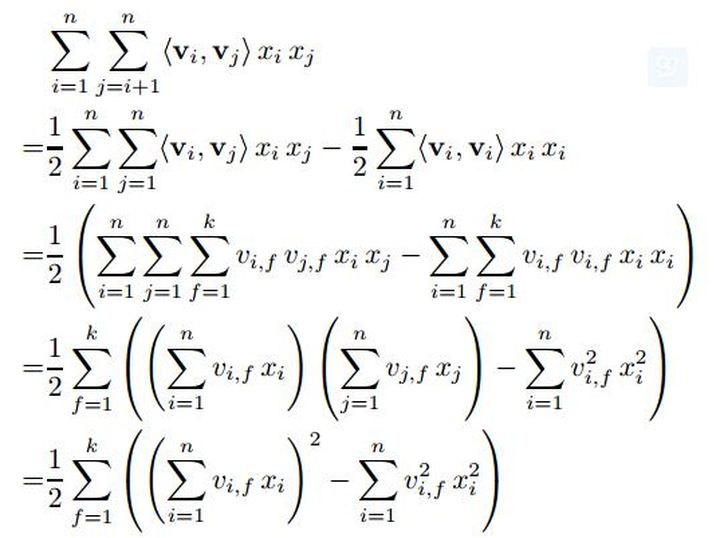
上面的推到结果,将xi和xj 的和其对应的隐变量vi vj结合,而遍历计算交叉特征移除,论文中给出的复杂度降低到O(kn)。
- FM可以应用到的任务:
回归, 二分类,排序
在使用FM应用到上述任务的时候,L2正则经常会加入到损失函数,以避免过拟合。
- 学习算法
FM模型的复杂度为线性的,所以使用优化算法可以很高效的学习这些参数W0,Wi,V
使用SGD学习如下:

作者开源出来自己的libFM库,可以很容易的搜到,也有很多的FM实现,据说xlearn实现的FM非常的高效(文档上看到的)。
- 总结
FM可以在稀疏数据中学习到组合特征,甚至是那些数据中没有观测值的组合特征
学习过程和参数的线性的,FM的学习更加有效
- FM VS SVMs
线性SVM
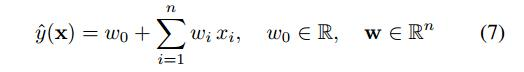
多项式SVM:

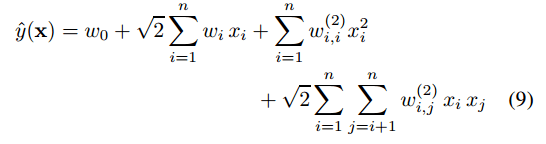
式子(9),和FM的式子(1)
相同之处:
在于都试图去构造这和特征.不同之处:
式9组合特征参数是相互独立的,如第i个特征与第j个特征的组合特征权值wij,和第i个特征与第k个特征的组合特征权值wik,二者是独立的。
而在FM中第i个特征与第j个特征的组合特征权值<vi,vj>,和第i个特征与第k个特征的组合特征权值<vi,vk>是不独立的因为都有参数vi参与计算。为什么SVM不能学习稀疏数据
稀疏数据中大部分值都是0,少数为1,假如只有第i个和第u个为1,
线性SVM的计算结果:
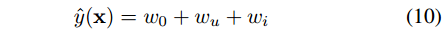

多项式SVM
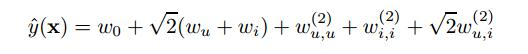

------------------------------------------FFM---------------------------------------------
- 摘要
1、在CTR预估上FFM的性能超过了FM,
- 介绍
1、点击率预估问题可视为二分类问题,采用逻辑回归估计,逻辑回归的参数获得于解决如下问题:
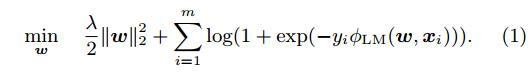
式1中取,线性模型:
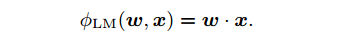
2、学习特征间的关系或者是构造组合特征(feature conjuctions)(似乎翻译很不合适)是CTR预估中关键部分。
虚构出如下数据:采用如下数据去理解组合特征(feature conjuctions)
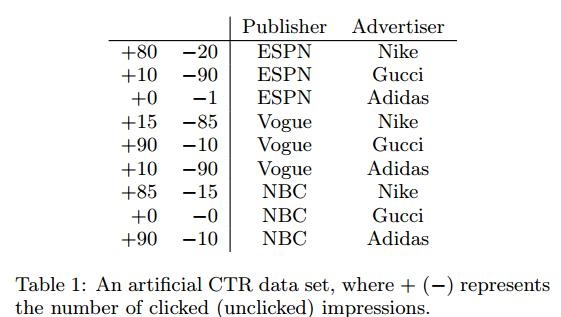
如Gucci对Vogue有很高的点击率,但是一般模型会分别学习他们两个各自的参数
FM模型也称作为PITF(parewise interaction tensor factorization)
- 学习feature conjuctions
1) 2项式(传统方式):
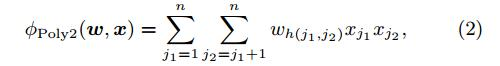
复杂度高O(n^2)
2) FM
将向量在隐空间做因式分解,经过数学推导复杂度能将到O(kn)
FM部分在介绍FM和SVM时候,由于稀疏数据中含有大量的0,和少量的1,在学习参数时候很多参数学习不充分或者学习不到(如,FM中的式10),这里在FFM文章中作者也介绍为什么FM优于2项式的原因:
table1中ESPN和Adidas只有一个-1,在2项式中学习到的权重 只能在这个数据中学习,但是FM中经过英式分解后
二者的权重是有 决定,而这两个参数由可以是从其他的包含Adidas和ESPN数据中学习来的,学习到的会更加的精确。FFM中提出field的概念,在table1中ESPN,Vogue和NBC属于Publish field,NIKE,Adidas, Gicci归为 Advertiser,一下解释FFM是如何工作的:
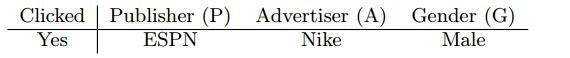
对于FM计算如下:(FFM论文中截图,在FM论文中w应该是用v来表示,表示隐向量)
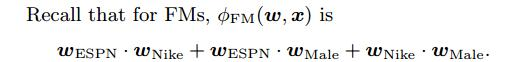
FM中每一个特征只有一个隐向量,这些隐向量的学习也是依据与其他的特征,如
在FFM中每一个特征都会有几个隐向量,取决于使用的其他特征field的个数,上图在FFM中建模的式子为:
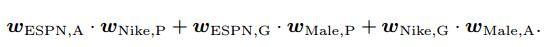
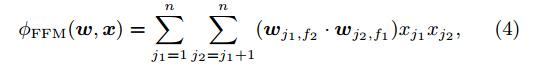
- 优化
使用AdaGrad去优化式子,x是稀疏的,只去更新那些x数据中非0项
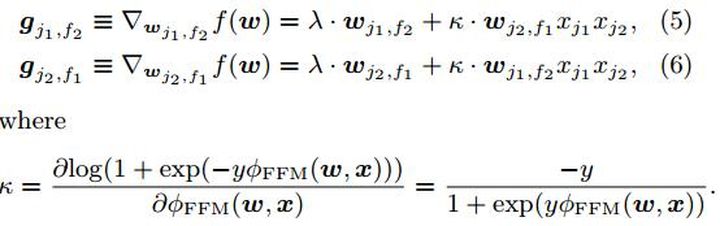


- FFM输入数据格式
LIBSVM的数据格式是:
label feat1:value1 feat2:value2.。。。
FFM数据输入格式:
label field1:feat1:value1 field2:feat2:value2.。。。
类别特征:
一条数据


数值特征:



- 实验
FFM在kaggle两个点击率比赛的表现已经证明了他的能力,文中作者指出FFM对迭代次数epoch很敏感,并进行了分析,实验中使用LIBLINEAR和LIBFM分别训练2项式和FM模型,及作者开发的LIBFFM模型。
1、k值并没有太大的影响结果

2、正则项lambda和学习率alpha对结果的影响会蛮大
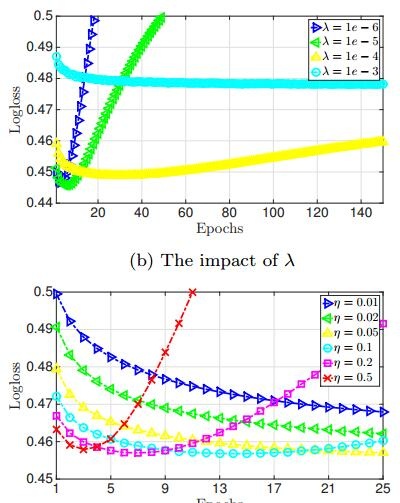
early-stopping会很好的改善FFM的训练,从上图就能看出了,及时的停止训练能增加模型的泛化性能.
3、early_stopping
FFM中部署early_stopping的方法如下

但是FFM对训练epoche很敏感(会有过拟合问题),early_stopping可能会提前停止,文中作者说了集中方法但是结论是都不如直接使用early_stopping(或者early_stopping的patience参数大点多训练几个epoche可以会好点,patience是keras中的early-stopping参数名称),作者也在左后的总结中指出,解决这个问题(训练epoche很敏感)是日后的工作。
推荐2篇FM和FFM 的博文:
小孩不笨:FFM(Field-aware Factorization Machines)的理论与实践zhuanlan.zhihu.com
