厦门市网站建设公司/seo优化推广流程
1. 什么是魔术方法
在Python中,所有以“__”双下划线包起来的方法,都统称为“Magic Method”,中文称『魔术方法』,例如类的初始化方法" __ init __"。
魔法方法是python内置方法,不需要主动调用,存在的目的是为了给python的解释器进行调用,几乎每个魔法方法都有一个对应的内置函数,或者运算符,当我们对这个对象使用这些函数或者运算符时就会调用类中的对应魔法方法,可以理解为重写这些python的内置函数。
基本的魔术方法看参考文章python魔法方法是什么
2. __ getiterm __作用
- 实现自己创建的对象使用for in 执行遍历操作
"""
实现自己创建的对象使用for in 执行遍历操作
定义了__getitem__,调用for in 会自动调用__getitem__方法,返回__getitem__的返回值;但是必须有一个终止条件,不然会无线循环下去
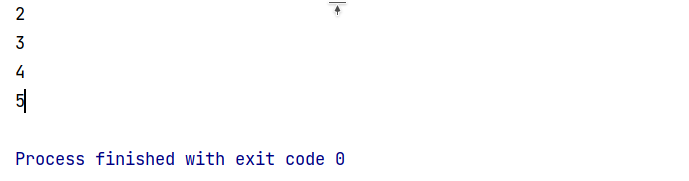
"""class Person():def __init__(self):self.result = 1def __getitem__(self, item):self.result += 1if self.result >= 6:raise StopIterationreturn self.result
p = Person()for i in p:print(i)
输出:
class Person():def __init__(self):self.result = 1def __getitem__(self, item):self.result += 1if self.result >= 6:raise StopIterationreturn self.result
p = Person()
print(p[0])
print(p[8])
print(p[2])
print(p['a'])
print(p[4])
输出:
可以看到,p[key]中key值不论是什么,存不存在,都会调用类中的__getitem__()方法。而且返回值就是__getitem__()方法中规定的return值。

- 可以使自己定义的类的实例化对象实现类似列表或字典一样操作[key]的访问方式
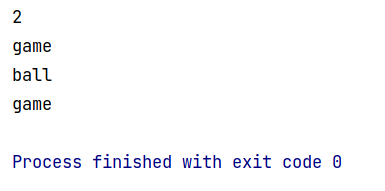
class Student:def __init__(self,name,hobbys):self.name = nameself.hobbys = hobbysdef __len__(self):return len(self.hobbys)def __getitem__(self, item):return self.hobbys[item]bob = Student("bob", ["ball","game"]) #创建一个bob实例,并传进两个值,名字和爱好。
print(len(bob))
print(bob[1])for hobby in bob:print(hobby)
输出:
可以看到如果__getitem__的返回值本身是列表,那么key与list的index对应, key值超出索引或者瞎写’a’会报list访问相关错误
3. 深度学习Dataset类中的__getitem__
详细参考[深度学习] pytorch利用Datasets和DataLoader读取数据
Pytorch提供了很多工具,能让我们读取数据和预处理数据。我们可以通过_getitem__定义自己的数据类,继承和重写这个抽象类。
Pytorch的Dataset类是一个抽象类,其内部有三个魔法方法:__ getitem__ ,_len _,__ add __
class Dataset(object):"""An abstract class representing a Dataset.All other datasets should subclass it. All subclasses should override``__len__``, that provides the size of the dataset, and ``__getitem__``,supporting integer indexing in range from 0 to len(self) exclusive."""def __getitem__(self, index):raise NotImplementedErrordef __len__(self):raise NotImplementedErrordef __add__(self, other):return ConcatDataset([self, other])
__len__方法,用来提供数据库的大小。__getitem__方法,支持一个整形索引,重来获取单个数据,范围是__len__定义的,范围是[0, len(self)]
简单实现MyDatasets类
# -*- coding:utf-8 -*-
__author__ = 'Leo.Z'import osfrom torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.image as mpimg# 对所有图片生成path-label map.txt
def generate_map(root_dir):current_path = os.path.abspath(__file__)father_path = os.path.abspath(os.path.dirname(current_path) + os.path.sep + ".")with open(root_dir + 'map.txt', 'w') as wfp:for idx in range(10):subdir = os.path.join(root_dir, '%d/' % idx)for file_name in os.listdir(subdir):abs_name = os.path.join(father_path, subdir, file_name)linux_abs_name = abs_name.replace("\\", '/')wfp.write('{file_dir} {label}\n'.format(file_dir=linux_abs_name, label=idx))# 实现MyDatasets类
class MyDatasets(Dataset):def __init__(self, dir):# 获取数据存放的dir# 例如d:/images/self.data_dir = dir# 用于存放(image,label) tuple的list,存放的数据例如(d:/image/1.png,4)self.image_target_list = []# 从dir--label的map文件中将所有的tuple对读取到image_target_list中# map.txt中全部存放的是d:/.../image_data/1/3.jpg 1 路径最好是绝对路径with open(os.path.join(dir, 'map.txt'), 'r') as fp:content = fp.readlines()str_list = [s.rstrip().split() for s in content]# 将所有图片的dir--label对都放入列表,如果要执行多个epoch,可以在这里多复制几遍,然后统一shuffle比较好self.image_target_list = [(x[0], int(x[1])) for x in str_list]def __getitem__(self, index):image_label_pair = self.image_target_list[index]# 按path读取图片数据,并转换为图片格式例如[3,32,32]img = mpimg.imread(image_label_pair[0])return img, image_label_pair[1]def __len__(self):return len(self.image_target_list)if __name__ == '__main__':# 生成map.txt# generate_map('train/')train_loader = DataLoader(MyDatasets('train/'), batch_size=128, shuffle=True)for step in range(20000):for idx, (img, label) in enumerate(train_loader):print(img.shape)print(label.shape)