汽车网站开发背景/广州seo托管
 标星★公众号,第一时间获取最新研究
标星★公众号,第一时间获取最新研究
本期作者:Alexandr Honchar
本期翻译:yana | 公众号翻译部
近期原创文章:
♥ 基于无监督学习的期权定价异常检测(代码+数据)
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ 深入研读:利用Twitter情绪去预测股市
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 利用深度学习最新前沿预测股价走势
♥ 一位数据科学PhD眼中的算法交易
♥ 基于RNN和LSTM的股市预测方法
♥ 人工智能『AI』应用算法交易,7个必踩的坑!
♥ 神经网络在算法交易上的应用系列(一)
♥ 预测股市 | 如何避免p-Hacking,为什么你要看涨?
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市交易
♥ 搭建入门级高频交易系统(架构细节分享)

这是公众号关于神经网络在金融领域特别是算法交易上的一个连载系列:
1、简单时间序列预测(已发表)
2、正确的时间序列预测+回测(已发表)
3、多变量时间序列预测
4、波动率预测和自定义损失函数
5、多任务和多模式学习
6、超参数优化
7、用神经网络增强传统策略
8、概率编程和Pyro进行预测
欢迎大家关注公众号查看此系列。本期我们从讲第三部分。
前言
之前的文章已经介绍了几种预测时间序列的方法:如何规范化数据,以实值或二进制变量的形式进行预测,以及如何处理高噪声中的过拟合。在上一篇文章中,我们只用了经过一些转换的收盘价,如果我们考虑历史数据中的最高价、最低价、开盘价、成交量,将会发生什么?这引出我们处理多元时间序列,每个时间点不止一个变量。在例子中,我们将使用整个OHLCV元组。
这篇文章中,我们会看看如何处理多元时间序列,特别是怎么处理每一个维度,如何对这种数据定义并训练一个神经网络,与上一篇文章比较结果。
数据准备
为了更好地理解什么是多元时间序列,我们看看用图形是怎么表示的,事实上图片不止二维(长和宽),还有代表颜色通道的“深度”。
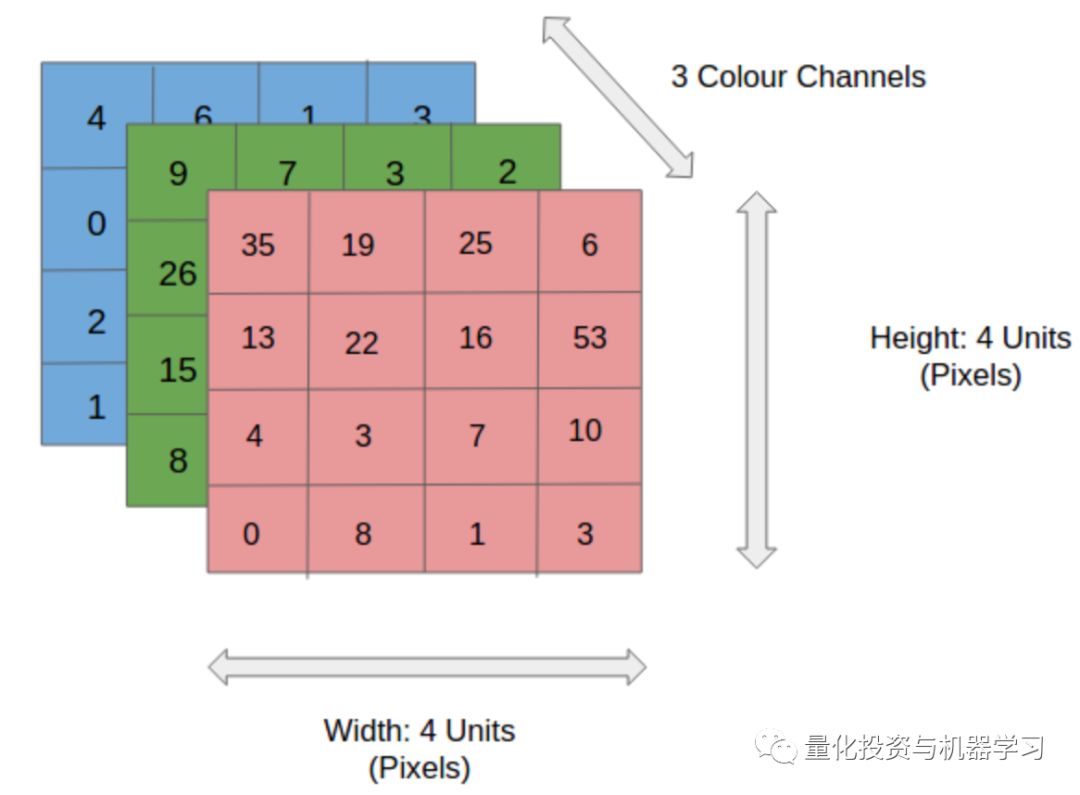
在时间序列的例子中,我们的图片只是1维的(通常在图表上的情况),通道扮演不同值的角色——操作的开盘价,最高价,最低价,收盘价和成交量。你也可以从另一个视角审视它,在任意时间点,时间序列代表的不只是一个值,而是一个向量(每日开盘价,最高价,最低价,收盘价和成交量)。但是,比作图片更利于我们理解,为什么我们今天使用卷积网络来处理这个问题。
关于多元时间序列,重点之一是数据维度可以有不同数据源,不同的数据属性,完全无关和不同的分布。所以必须把它们各自归一化。
我们不需要预测一些精确的值,所以我们对未来的期望值和方差并不是很感兴趣——我们只需要预测上下幅度。这就是为什么我们会冒险只通过他们的均值和方差(z-分数 归一化)来归一化30天窗口,假设在单一时间窗口内,这些值改变不大,且没有触碰未来信息。
但我们将分别规范化时间窗的每个维度:
for i in range(0, len(data_original), STEP): try:
o = openp[i:i+WINDOW]
h = highp[i:i+WINDOW]
l = lowp[i:i+WINDOW]
c = closep[i:i+WINDOW]
v = volumep[i:i+WINDOW]
o = (np.array(o) - np.mean(o)) / np.std(o)
h = (np.array(h) - np.mean(h)) / np.std(h)
l = (np.array(l) - np.mean(l)) / np.std(l)
c = (np.array(c) - np.mean(c)) / np.std(c)
v = (np.array(v) - np.mean(v)) / np.std(v)但是因为我们想要预测第二天价格上涨还是下跌,所以需要考虑单个维度的变化:
x_i = closep[i:i+WINDOW]
y_i = closep[i+WINDOW+FORECAST]
last_close = x_i[-1]
next_close = y_iif last_close < next_close:
y_i = [1, 0]else:
y_i = [0, 1]所以,我们训练数据,和之前一样,是30天时间窗口,但是现在我们用每天整个OHLCV数据归一化来预测收盘价的变动方向。
神经网络框架
正如前面提到的,想用CNN做一个分类器。选它的主要原因是超参数的灵活性和可解释性(卷积内核,下采样大小等),以及类似于RNN的性能,比MLP训练更快。
代码如下:
model = Sequential()
model.add(Convolution1D(input_shape = (WINDOW, EMB_SIZE),
nb_filter=16,
filter_length=4,
border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Convolution1D(nb_filter=8,
filter_length=4,
border_mode='same'))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(64))
model.add(BatchNormalization())
model.add(LeakyReLU())
model.add(Dense(2))
model.add(Activation('softmax'))和第一篇文章的构架唯一不同的是在我们的案例中把EMB_SIZE变量改为5。
训练过程
让我们编译模型
opt = Nadam(lr=0.002)
reduce_lr = ReduceLROnPlateau(monitor='val_acc', factor=0.9, patience=30, min_lr=0.000001, verbose=1)
checkpointer = ModelCheckpoint(filepath="model.hdf5", verbose=1, save_best_only=True)
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(X_train, Y_train,
nb_epoch = 100,
batch_size = 128,
verbose=1,
validation_data=(X_test, Y_test),
callbacks=[reduce_lr, checkpointer],
shuffle=True)并检查性能:
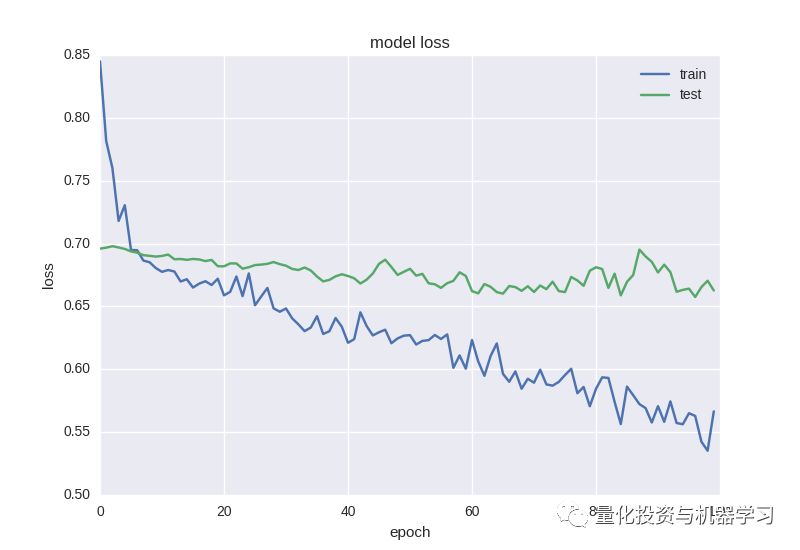
Loss after 100 epochs
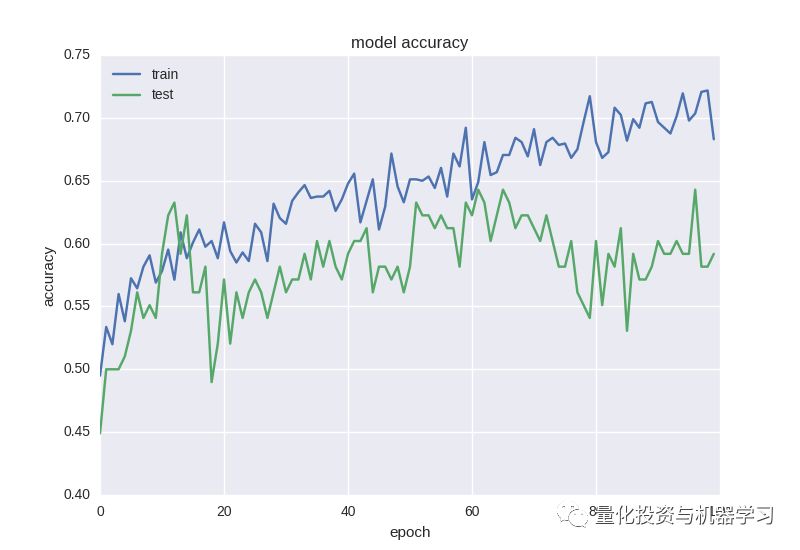
Accuracy of binary classification after 100 epochs
从图中我们可以清楚地看到网络训练充分(对于非常嘈杂的数据),训练集损失随着时间下降,而精确度上升。最重要的是,相对于第一篇文章中的单变量时间序列,我们把准确度性能从58%提高到近65%。
为了检查过拟合,我们也绘制了混淆矩阵:
from sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrix
model.load_weights("model.hdf5")
pred = model.predict(np.array(X_test))
C = confusion_matrix([np.argmax(y) for y in Y_test], [np.argmax(y) for y in pred])print C / C.astype(np.float).sum(axis=1)得到:
[[ 0.75510204 0.24489796]
[ 0.46938776 0.53061224]]以上显示,我们预测向上幅度有75%的准确率,向下幅度有53%的准确率,当然这个结果和测试数据集差不多。
回归如何?
我们可以预测实际价值,即第二天的回报或收盘价,而不是预测二元变量。在我们之前的实验中,我们没有成功地产生好的结果。
不幸的是,在盈利上效果仍然不好:
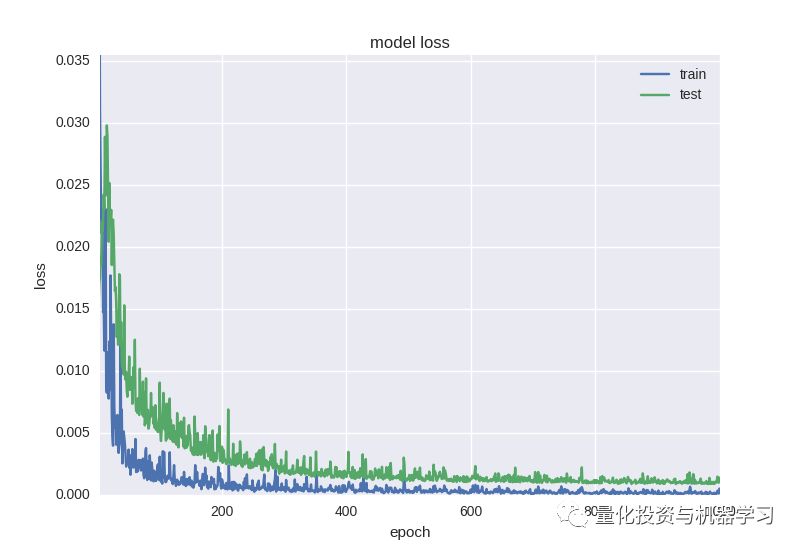
回归问题的损失减少
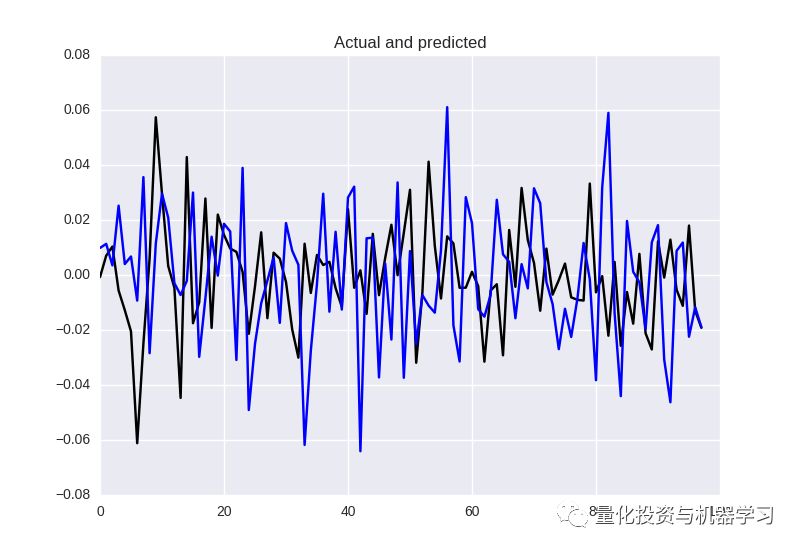
价格变动的预测
预测收盘价不太好
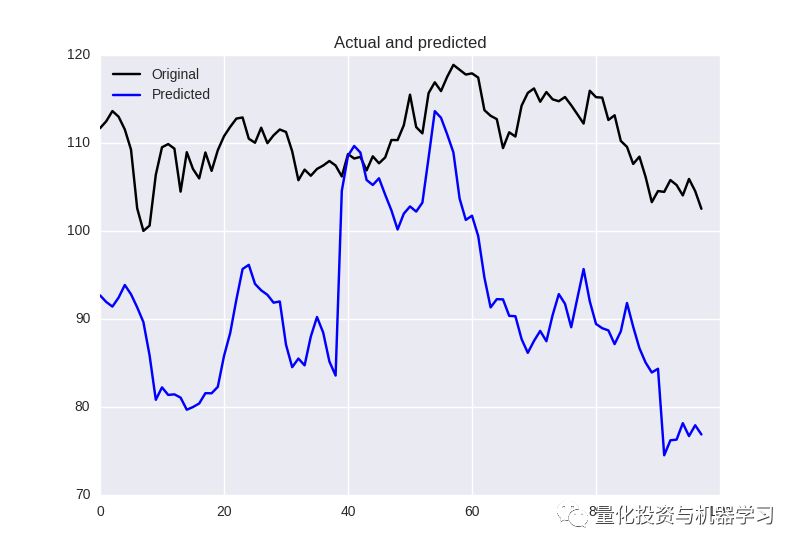
预测收盘价
总结
我们讨论了多元时间序列中数据准备和归一化的一般流程,对它们进行CNN训练,我们取得了分类问题的显著改进(7%),是对股票在第二天上涨还是下跌的分类问题。
与此同时,我们仍然要说明回归问题对我们来说仍然过于复杂,我们会在稍后的工作中,选择正确的损失指标和激活函数。
在明天的文章中,我们会介绍多模式学习的概念。尽请期待!
推荐阅读
01、经过多年交易之后你应该学到的东西(深度分享)
02、监督学习标签在股市中的应用(代码+书籍)
03、全球投行顶尖机器学习团队全面分析
04、使用Tensorflow预测股票市场变动
05、使用LSTM预测股票市场基于Tensorflow
06、美丽的回测——教你定量计算过拟合概率
07、利用动态深度学习预测金融时间序列基于Python
08、Facebook开源神器Prophet预测时间序列基于Python
09、Facebook开源神器Prophet预测股市行情基于Python
10、2018第三季度最受欢迎的券商金工研报前50(附下载)
11、实战交易策略的精髓(公众号深度呈现)
12、Markowitz有效边界和投资组合优化基于Python
13、使用LSTM模型预测股价基于Keras
14、量化金融导论1:资产收益的程式化介绍基于Python
15、预测股市崩盘基于统计机器学习与神经网络(Python+文档)
16、实现最优投资组合有效前沿基于Python(附代码)
17、精心为大家整理了一些超级棒的机器学习资料(附链接)
18、海量Wind数据,与全网用户零距离邂逅!
19、机器学习、深度学习、量化金融、Python等最新书籍汇总下载
20、各大卖方2019年A股策略报告,都是有故事的人!
扫码关注我们
