柳州网站建设公司/网站关键词优化教程
嗨害大家好鸭!我是小熊猫~
咳咳年前最后一天…
一点单身福利…
我想… 应该会有需要的吧…

环境开发:
- Python 3.8
- Pycharm
模块使用:
- import parsel
- import requests
- import csv
- import re

爬虫基本思路流程:
一. 数据来源分析:
1. 明确需求:
采集数据是什么
—> 资料数据 <静态网页>
—>在网页源代码里面
二. 代码实现步骤:
1. 发送请求

2. 获取数据
开发者工具 —> response
3. 解析数据
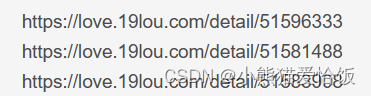
详情页ID —> UID
获取详情页资料信息
4. 发送请求
资料详情页url地址
5. 获取数据
网页源代码
6. 解析数据
基本资料信息
7. 保存数据
- 基本资料信息保存csv表格
- 照片数据, 保存本地文件夹

代码实现
导入模块
import requests
import parsel
import csv
import re
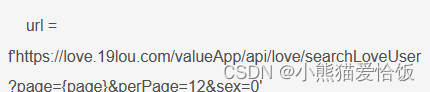
请求链接
伪装模拟
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/557.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}

发送请求
response = requests.get(url=url, headers=headers)print(response)
for循环遍历
for index in response.json()['data']['items']:
. 表示调用方法属性
selector = persel.Selector(html_data)
name = selector.css('.username::text').get()
info_list = selector.css('.info-tag::text').getall()

判断info_list元素个数
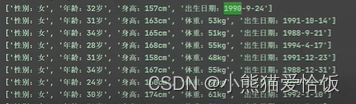
gender = info_list[0].split(':')[-1]age = info_list[1].split(':')[-1]height = info_list[2].split(':')[-1]date = info_list[-1].split(':')[-1]
把获取下来的数据 保存字典
dit = {'昵称': name,'性别': gender,'年龄': age,'身高': height,'体重': weight,'出生日期': date,'生肖': zodiac,'星座': constellation,'籍贯': nativePlace,'所在地': location,'学历': edu,'婚姻状况': maritalStatus,'职业': job,'年收入': money,'住房': house,'车辆': car,'照片': img_url,'详情页': link,}csv_writer.writerow(dit)new_name = re.sub(r'[\/"*?<>|]', '', name)
保存图片, 获取图片二进制数据
img_content = requests.get(url=img_url, headers=headers).content
with open('data\\' + new_name + '.jpg', mode='wb') as img:img.write(img_content)
print(dit)