深圳联雅网站建设/托管竞价推广公司
CoNLL-2003 数据集包括 1,393 篇英文新闻文章和 909 篇德文新闻文章。我们将查看英文数据。
1. 下载CoNLL-2003数据集
https://data.deepai.org/conll2003.zip
下载后解压你会发现有如下文件。

打开train.txt文件, 你会发现如下内容。
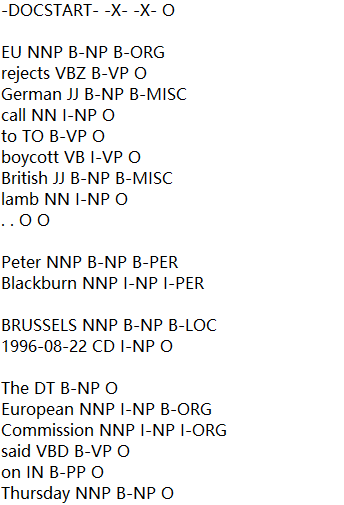
CoNLL-2003 数据文件包含由单个空格分隔的四列。每个单词都单独占一行,每个句子后面都有一个空行。每行的第一项是单词,第二项是词性 (POS) 标记,第三项是句法块标记,第四项是命名实体标记。块标签和命名实体标签的格式为 I-TYPE,这意味着该单词位于 TYPE 类型的短语内。仅当两个相同类型的短语紧随其后时,第二个短语的第一个单词才会带有标签 B-TYPE 以表明它开始一个新短语。带有标签 O 的单词不是短语的一部分。
2. 对数据预处理
数据文件夹中的 train.txt、valid.txt 和 test.txt 包含句子及其标签。我们只需要命名实体标签。我们将单词及其命名实体提取到一个数组中 - [ [‘EU’, ‘B-ORG’], [‘rejects’, ‘O’], [‘German’, ‘B-MISC’], [‘call’, ‘O’], [‘to’, ‘O’], [‘boycott’, ‘O’], [‘British’, ‘B-MISC’], [‘lamb’, ‘O’], [‘.’, ‘O’] ]。请参阅下面的代码来提取单词以及命名实体。我们获得了训练、有效和测试中所有句子的具有命名实体的单词。
import osconll2003_path = 'D:/ML/datasets/conll2003_new'
def split_text_label(filename):f = open(filename)split_labeled_text = []sentence = []for line in f:if len(line)==0 or line.startswith('-DOCSTART') or line[0]=="\n":if len(sentence) > 0:split_labeled_text.append(sentence)sentence = []continuesplits = line.split(' ')sentence.append([splits[0],splits[-1].rstrip("\n")])if len(sentence) > 0:split_labeled_text.append(sentence)sentence = []return split_labeled_text
split_train = split_text_label(os.path.join(conll2003_path, "train.txt"))
split_valid = split_text_label(os.path.join(conll2003_path, "valid.txt"))
split_test = split_text_label(os.path.join(conll2003_path, "test.txt"))for i in range(5):print(split_train[i])print(len(split_train))
print(len(split_valid))
print(len(split_test))输出结果
[['EU', 'B-ORG'], ['rejects', 'O'], ['German', 'B-MISC'], ['call', 'O'], ['to', 'O'], ['boycott', 'O'], ['British', 'B-MISC'], ['lamb', 'O'], ['.', 'O']]
[['Peter', 'B-PER'], ['Blackburn', 'I-PER']]
[['BRUSSELS', 'B-LOC'], ['1996-08-22', 'O']]
[['The', 'O'], ['European', 'B-ORG'], ['Commission', 'I-ORG'], ['said', 'O'], ['on', 'O'], ['Thursday', 'O'], ['it', 'O'], ['disagreed', 'O'], ['with', 'O'], ['German', 'B-MISC'], ['advice', 'O'], ['to', 'O'], ['consumers', 'O'], ['to', 'O'], ['shun', 'O'], ['British', 'B-MISC'], ['lamb', 'O'], ['until', 'O'], ['scientists', 'O'], ['determine', 'O'], ['whether', 'O'], ['mad', 'O'], ['cow', 'O'], ['disease', 'O'], ['can', 'O'], ['be', 'O'], ['transmitted', 'O'], ['to', 'O'], ['sheep', 'O'], ['.', 'O']]
[['Germany', 'B-LOC'], ["'s", 'O'], ['representative', 'O'], ['to', 'O'], ['the', 'O'], ['European', 'B-ORG'], ['Union', 'I-ORG'], ["'s", 'O'], ['veterinary', 'O'], ['committee', 'O'], ['Werner', 'B-PER'], ['Zwingmann', 'I-PER'], ['said', 'O'], ['on', 'O'], ['Wednesday', 'O'], ['consumers', 'O'], ['should', 'O'], ['buy', 'O'], ['sheepmeat', 'O'], ['from', 'O'], ['countries', 'O'], ['other', 'O'], ['than', 'O'], ['Britain', 'B-LOC'], ['until', 'O'], ['the', 'O'], ['scientific', 'O'], ['advice', 'O'], ['was', 'O'], ['clearer', 'O'], ['.', 'O']]
14041
3250
3453
我们为文件夹(训练、有效和测试)中的所有唯一单词和唯一标签(命名实体将称为标签)构建词汇表。 labelSet 包含标签中的所有唯一单词,即命名实体。 wordSet 包含所有唯一的单词。
labelSet = set()
wordSet = set()
# words and labels
for data in [split_train, split_valid, split_test]:for labeled_text in data:for word, label in labeled_text:labelSet.add(label)wordSet.add(word.lower())我们将唯一的索引与词汇表中的每个单词/标签相关联。我们为“PADDING_TOKEN”分配索引 0,为“UNKNOWN_TOKEN”分配索引 1。当一批句子长度不等时,“PADDING_TOKEN”用于句子末尾的标记。 “UNKNOWN_TOKEN”用于表示词汇表中不存在的任何单词,
# Sort the set to ensure '0' is assigned to 0
sorted_labels = sorted(list(labelSet), key=len)
# Create mapping for labels
label2Idx = {}
for label in sorted_labels:label2Idx[label] = len(label2Idx)
idx2Label = {v: k for k, v in label2Idx.items()}
# Create mapping for words
word2Idx = {}
if len(word2Idx) == 0:word2Idx["PADDING_TOKEN"] = len(word2Idx)word2Idx["UNKNOWN_TOKEN"] = len(word2Idx)
for word in wordSet:word2Idx[word] = len(word2Idx)保持word2Idx和idx2Label以备后用
def save_dict(dict, file_path):import json# Saving the dictionary to a filewith open(file_path, 'w') as f:json.dump(dict, f)save_dict(word2Idx, 'dataset/word2idx.json')
save_dict(idx2Label, 'dataset/idx2Label.json')我们读取 split_train、split_valid 和 split_test 文件夹中的单词,并将其中的单词和标签转换为各自的索引。
def createMatrices(data, word2Idx, label2Idx):sentences = []labels = []for split_labeled_text in data:wordIndices = []labelIndices = []for word, label in split_labeled_text:if word in word2Idx:wordIdx = word2Idx[word]elif word.lower() in word2Idx:wordIdx = word2Idx[word.lower()]else:wordIdx = word2Idx['UNKNOWN_TOKEN']wordIndices.append(wordIdx)labelIndices.append(label2Idx[label])sentences.append(wordIndices)labels.append(labelIndices)return sentences, labels
train_sentences, train_labels = createMatrices(split_train, word2Idx, label2Idx)
valid_sentences, valid_labels = createMatrices(split_valid, word2Idx, label2Idx)
test_sentences, test_labels = createMatrices(split_test, word2Idx, label2Idx)for i in range(5):print(train_sentences[i], ':', train_labels[i])print(len(train_sentences), len(train_labels))
print(len(valid_sentences))
print(len(test_sentences))执行结果
[398, 6505, 16052, 7987, 10593, 10902, 7841, 1321, 8639] : [1, 0, 7, 0, 0, 0, 7, 0, 0]
[4072, 9392] : [4, 5]
[18153, 18845] : [3, 0]
[9708, 1010, 23642, 12107, 23888, 18333, 23312, 1546, 11945, 16052, 7845, 10593, 17516, 10593, 23421, 7841, 1321, 11193, 23055, 25107, 3495, 1184, 15306, 22545, 22027, 17777, 19192, 10593, 9610, 8639] : [0, 1, 6, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[19294, 5437, 7563, 10593, 9708, 1010, 8960, 5437, 25577, 3743, 21470, 16473, 12107, 23888, 22066, 17516, 25499, 8578, 15500, 17851, 7591, 15435, 15240, 11445, 11193, 9708, 11011, 7845, 19718, 24582, 8639] : [3, 0, 0, 0, 0, 1, 6, 0, 0, 0, 4, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0]
14041 14041
3250
3453
这些句子的长度不同。我们需要填充句子和标签以使它们的长度相等。 max_seq_len取为128。
max_seq_len = 128
from keras.utils import pad_sequences
import numpy as np
dataset_file = './dataset/dataset'
def padding(sentences, labels, max_len, padding='post'):padded_sentences = pad_sequences(sentences, max_len,padding='post')padded_labels = pad_sequences(labels, max_len, padding='post')return padded_sentences, padded_labels
train_features, train_labels = padding(train_sentences, train_labels, max_seq_len, padding='post' )
valid_features, valid_labels = padding(valid_sentences, valid_labels, max_seq_len, padding='post' )
test_features, test_labels = padding(test_sentences, test_labels, max_seq_len, padding='post' )for i in range(5):print(train_sentences[i], ':', train_labels[i])
执行结果
[384, 3921, 4473, 23562, 12570, 23650, 24802, 21806, 25847] : [6 0 7 0 0 0 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[10972, 13187] : [4 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[10717, 16634] : [5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[9533, 19224, 12621, 23462, 8851, 5819, 24672, 7603, 4497, 4473, 23777, 12570, 14155, 12570, 5401, 24802, 21806, 12477, 172, 4222, 19599, 17172, 13462, 17423, 12114, 2056, 23775, 12570, 4528, 25847] : [0 6 2 0 0 0 0 0 0 7 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[22094, 14925, 14340, 12570, 9533, 19224, 5770, 14925, 7238, 2077, 4983, 5491, 23462, 8851, 10770, 14155, 8428, 14726, 5504, 18165, 2736, 6830, 5921, 11773, 12477, 9533, 11046, 23777, 25350, 21991, 25847] : [0 0 0 0 6 2 0 0 0 4 3 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0]
保持预处理过的训练集,验证集以及测试集,为训练NER模型做准备。
np.savez(dataset_file, train_X=train_features, train_y=train_labels, valid_X=valid_features, valid_y=valid_labels, test_X=test_features,test_y=test_labels)
至此你会有如下三个文件。
下面代码是load这些文件
def load_dict(path_file):import json# Loading the dictionary from the filewith open(path_file, 'r') as f:loaded_dict = json.load(f)return loaded_dict;word2idx = load_dict('dataset/word2idx.json')
idx2Label= load_dict('dataset/idx2Label.json')def load_dataset():dataset = np.load('./dataset/dataset.npz')train_X = dataset['train_X']train_y = dataset['train_y']valid_X = dataset['valid_X']valid_y = dataset['valid_y']test_X = dataset['test_X']test_y = dataset['test_y']return train_X, train_y, valid_X, valid_y, test_X, test_ytrain_X, train_y, valid_X, valid_y, test_X, test_y =load_dataset()