一站式网站建设报价/八大营销方式有哪几种
目录
- 📝论文下载地址
- 🔨代码下载地址
- 👨🎓论文作者
- 📦模型讲解
- [论文解读]
- [网络结构]
- [对转换过程的优化]
- [层分离内容监督转换]
- [训练策略]
- [双模数据之间的转换不平衡]
- [融合过程]
- [结果分析]
- [数据集]
- [训练细节]
- [[SUN RGB-D数据集上的结果]]()
- [NYUD2数据集上的结果]
📝论文下载地址
[论文地址]
🔨代码下载地址
[GitHub]
👨🎓论文作者
📦模型讲解
[论文解读]
本文作者提出了一种场景识别(Recg)的网络,并且包括模态转换(T)的多任务网络(TRecgNet)。
[网络结构]
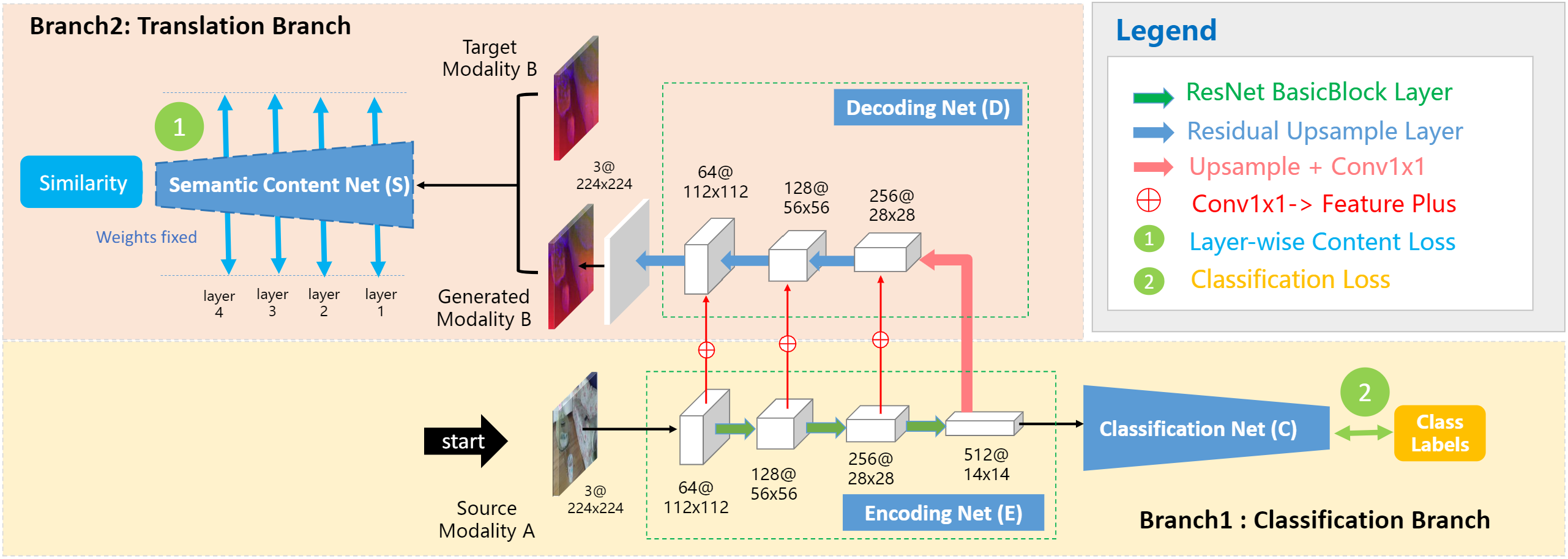
网络的主干是编码网络(E)、解码网络(D)、分类网络(C)和语义网络(S)。从上面的网络结构可以看出网络主要有两个分支。分支1是分类分支由EC组成,分支2是转换分支由ED组成。E与C选择的是ResNet18预训练好的网络进行特征提取,D解码网络对E的特征图及进行重建互补数据。网络可以改变数据源模式,但是不需要改变网络结构。
使用RGB-D跨模态数据进行训练,假设配准的RGB-D数据表示为(MA,MB)(M_A,M_B)(MA,MB)的类别属于L={1,2,...,Nc}L=\{1,2,...,N_c\}L={1,2,...,Nc},NcN_cNc是场景类别总数。网络的学习目标是包含转化映射T:Rd→MBT:\mathbb R^d\to M_BT:Rd→MB和类别预测函数C:Rd→LC:\mathbb R^d\to LC:Rd→L的嵌入E:MA→RdE:M_A\to \mathbb R^dE:MA→Rd。核心问题是如何通过编码网络学习有效的有利于分类的模态互补特征。
[对转换过程的优化]
作者采取三种措施来增强转换过程。
①凭经验删除ResNet的第一个最大池化操作。因为这个过程丢失的信息是比较多的,网络中主要通过卷积及进行特征图的缩小。
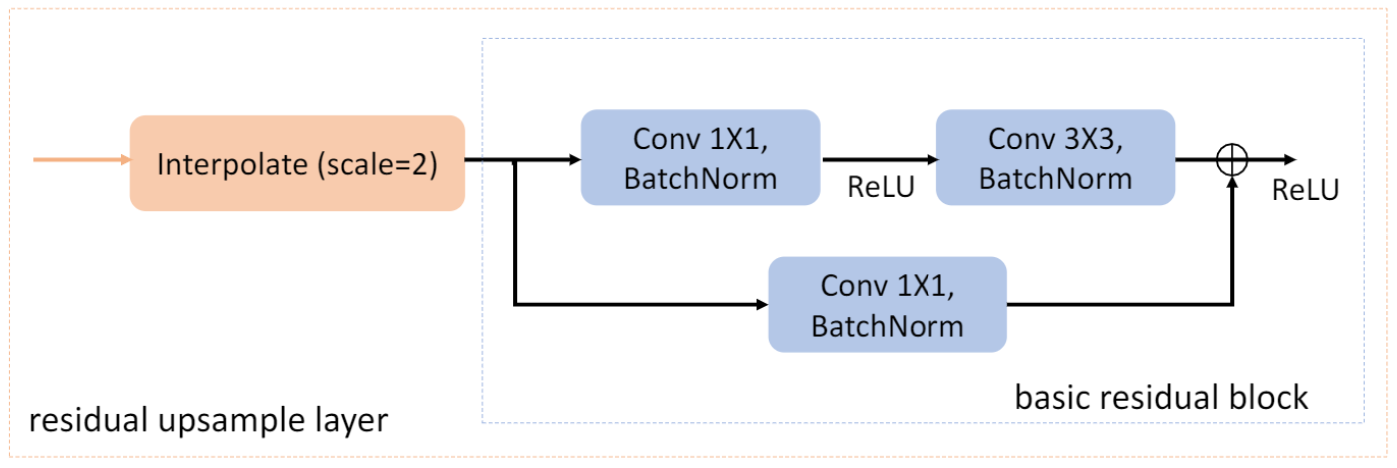
②在D网络中引入残差上采样模块。残差上采样模块对特征图进行双线性插值运算,并带有一个残差块,该残块模拟ResNet的残差块。其结构如下图所示。
③作者将上下文信息从E的三个阶段传到D。使用”加号“操作而不是串联操作,这可以减少D网络中的参数数量。
[层分离内容监督转换]
转换网络旨在提高补充数据和E网络学习特征的可表示性,该过程由语义RGB卷积网络监督,该模型使用从低层到高层的特征组合,来衡量E网络学习特征生成的数据和配对的数据的相似性。在ImageNet上与训练好的ResNet作为S网络的结构。
使用Φ={ϕMl,l∈[1,2,3,4]}\Phi=\{\phi_M^l,l\in[1,2,3,4]\}Φ={ϕMl,l∈[1,2,3,4]}表示输入的特征,ϕMl\phi_M^lϕMl表示第iii层的输入特征。S网络它输入图像从模态MMM映射到Rd\mathbb R^dRd维的特征向量。具体来说,作者定义两个特征向量之间的L1损失以进行转换网络的监督。假设正在训练MAM_AMA的分类任务。生成的图像yi′y'_iyi′和MBM_BMB是到S网络的输入,可以从yi′y'_iyi′和MBM_BMB获得分层特征。通过L1损失,限制每个层(ResNet中的layer1-layer4)相同。
Lcontent(yi,yi′)=∑l=1L∣∣ϕyil−ϕT(xi)l∣∣1L_{content}(y_i,y_i')=\sum^L_{l=1}||\phi^l_{y_i}-\phi^l_{T(x_i)}||_1Lcontent(yi,yi′)=l=1∑L∣∣ϕyil−ϕT(xi)l∣∣1
[训练策略]
为了同时学习分类和转换,以多任务方式优化了E,C,D网络。具体来说,给定一对RGB-D图像,令eMA=E({xi})e_{M_A}=E(\{x_i\})eMA=E({xi})表示E网络对输入MAM_AMA提取到的特征,而dMB=D(E({xi})d_{M_B}=D(E(\{x_i\})dMB=D(E({xi})是从D网络解码的生成的模态B数据。
①E→D→S以最小化分层特征的距离以限制其语义相似性。
①E→C使用交叉熵损失函数进行分类任务。
总损失如下:
Ltotal=αLcontent+βLCclsL_{total}=\alpha L_{content}+\beta L_{C_{cls}}Ltotal=αLcontent+βLCcls
其中LcontentL_{content}Lcontent表示网络S中的分层损失函数,LCclsL_{C_{cls}}LCcls表示网络C的分类损失。α=10,β=1\alpha=10,\beta=1α=10,β=1为两个超参数。由于作者使用的数据集类别的不平衡,因此使用赋予每个类别的缩放比例权重来实现交叉熵损失-缩放权重旨在为不同实体类别分配不同的权重以解决不平衡训练的问题。作者使用以下重新缩放策略:
Lweighted_cls=1N∑i−w(yi)logf(xi)yi∑jf(xi)jL_{weighted\_cls}=\frac{1}{N}\sum_i-w(y_i)\log\frac{f(x_i)_{y_i}}{\sum_jf(x_i)_j}Lweighted_cls=N1i∑−w(yi)log∑jf(xi)jf(xi)yi
那么权重w(y)w(y)w(y)按照以下公式计算:
w(y)=N(y)−N(c_min)+δN(c_max)−N(c_min)w(y)=\frac{N(y)-N(c\_min)+δ}{N(c\_max)-N(c\_min)}w(y)=N(c_max)−N(c_min)N(y)−N(c_min)+δ
其中NyN_yNy是y类的图像数。c_minc\_minc_min和c_maxc\_maxc_max代表训练图像最少和最多的类别。δδδ设定为0.01。在测试阶段,仅将识别分支用于识别预测。
[双模数据之间的转换不平衡]
有几个因素表明从RGB到深度和深度到RGB的转换不平衡。例如,从RGB到深度图像的转换是比较自然的过程,而从相反的方向来看这将成为一个不适定的问题。此外,由于采集设备和成像过程的特征,深度数据的真实性还会带来更多的价值误差。因此,从深度TRecgNet(从深度到RGB的转换)中,将与输入特征通道叠加的N(0,1)N(0,1)N(0,1)的随机噪声采样组成网络D的输入。作者发现这对于稳定深度TRecgNet的训练非常有用。在作者的实验中,噪声的维数设置为128。
[融合过程]
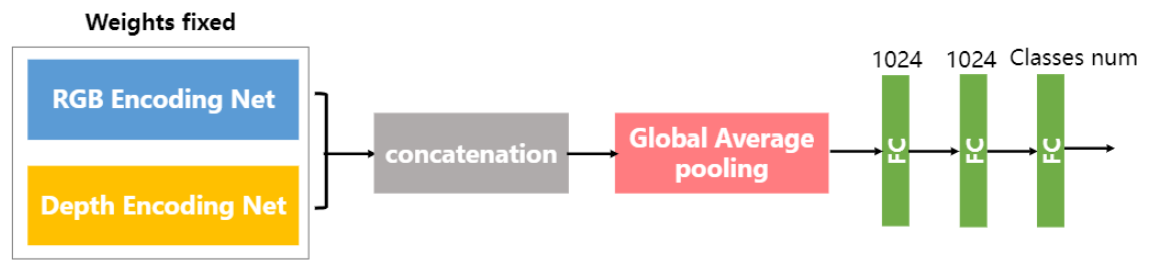
在训练完成TRecgNet后,获得针对RGB数据的分类网络E+C预深度图的分类网络E+C。会通过下图组合完成多源数据的场景识别任务。
[结果分析]
[数据集]
SUN RGB-D数据集是目前最大的RGB-D数据集。它包含来自NYUDepthv2,Berkeley B3DO和SUN3D的RGB-D图像,并且包含3784个Microsoft Kinect v2图像,3389个Asus Xtion图像,2003个Microsoft Kinect v1图像和1159个Intel RealSense图像。作者仅处理19种主要场景类别,其中包含80多个图像。按照标准拆分,总共有4845张图像用于训练,而4659张图像用于测试。
NYU深度数据集V2(NYUD2)是一个相对较小的数据集;它包括27个室内类别。将类别分为十个类别,其中包括九个最常见的类别和另一个代表其余类别的类别。同样,作者使用795/654图像按照标准分割进行训练/测试。
[训练细节]
提出的方法是在NVIDIA TITANXp上利用深度学习框架Pytorch实现的。作者使用SGD更新网络参数,并将batchsize设置为40。将RGB-D图像的大小调整为256×256,并随机裁剪为224×224。作者训练TRecgNet的epoch为70,在前20个epoch中将学习率初始化为2×10−42×10^{−4}2×10−4,在其余50个中,线性改变学习率。在测试阶段,作者对测试图像使用中心裁剪操作。采用真值HHA(水平视差,地上高度和重力角)编码深度图像,网络可以表现出更好的性能,可以捕获用于各种视觉任务的深度数据的场景结构和几何特性。
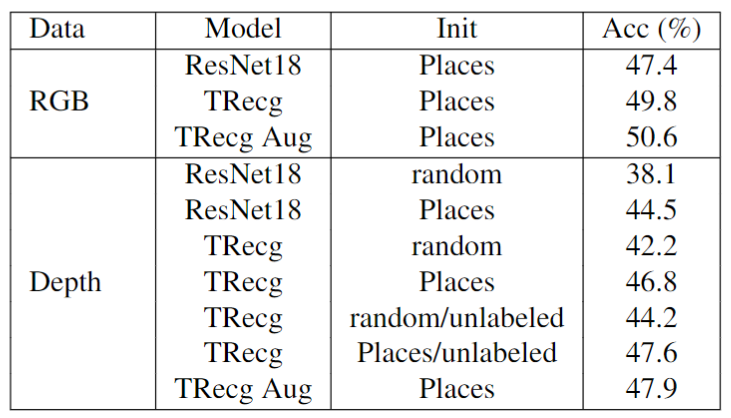
作者分别训练两种TRecgNets进行评估。 在不使用生成的数据的情况下训练了基本的TRecgNet,而TrecgNet_Aug则是在训练TRecgNet时使用了先前对应的基本TRecgNet的生成数据。具体来说,在TrecgNet_Aug的训练阶段,作者随机使用生成的数据,将其数量控制为批量大小的30%,以实现最佳性能。
[SUN RGB-D数据集上的结果]
作者首先在SUN RGB-D数据集上做了一些模型有效性研究。要做的就是证明模态转换学习数据之间的相似性是否对分类任务有效。
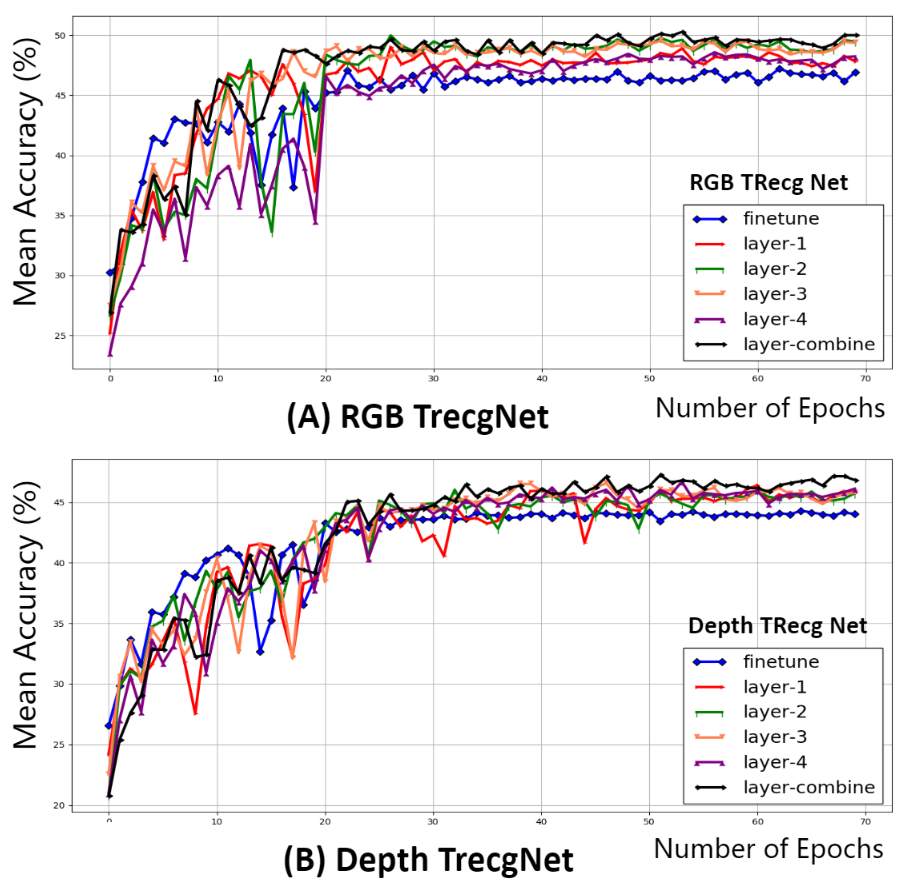
上面finetune表示不使用转换网络,直接训练E+C的训练过程,layer-n表示使用第n层的内容损失。可以看出网络有更好的效果。下图展示利用不同层的损失后生成图像的效果对比。

下图是TrecgNet从SUN RGB-D数据集的测试集中生成的数据示例。(B)是从原始RGB数据(A)转换而来的深度图像,(D)是使用原始深度的(C)生成的RGB图像。

下图是展示图像生成的效果比较,pixel-2-pixel、像素级GAN和本方法。

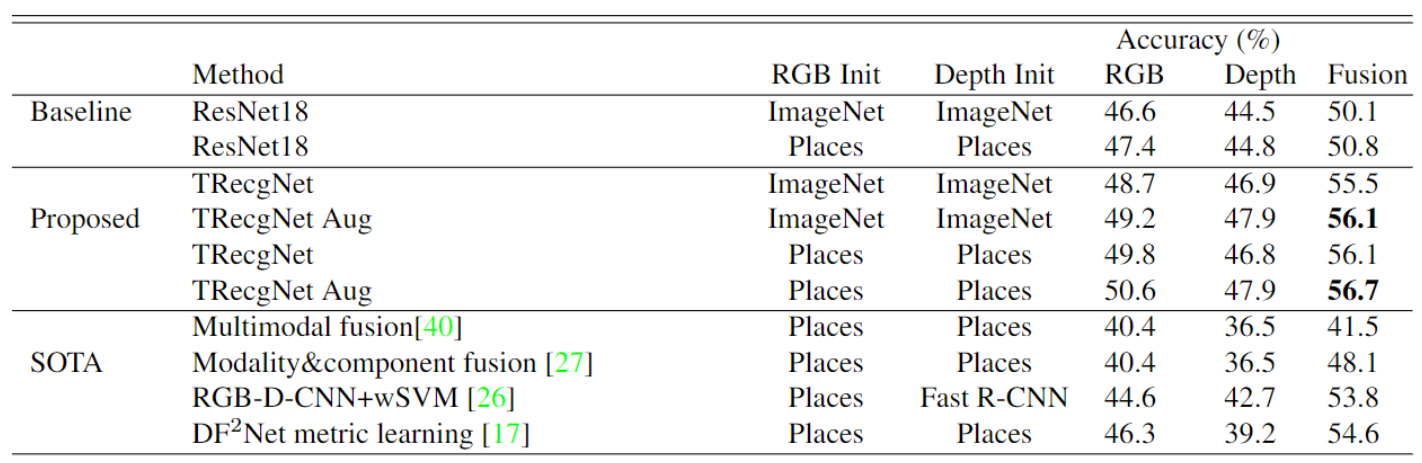
下图是展示本方法与其他分类网络性能的对比。
[NYUD2数据集上的结果]
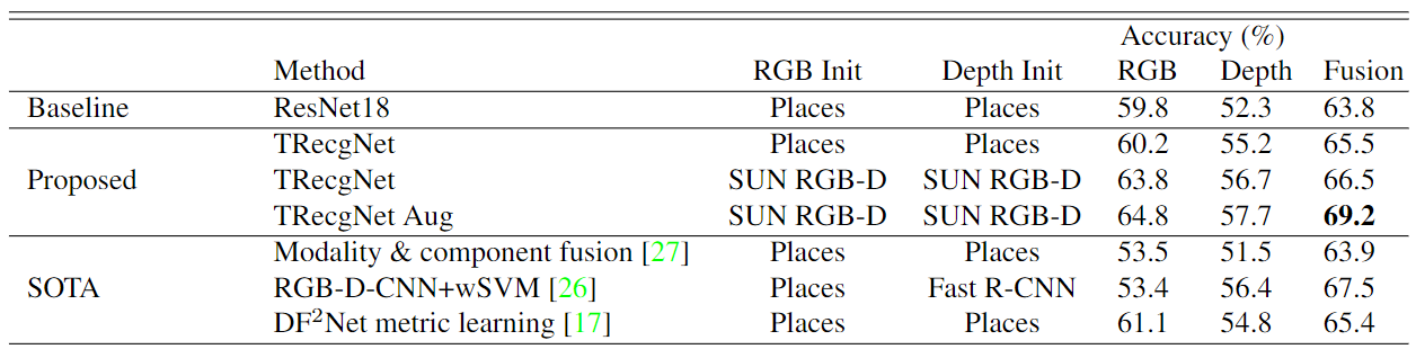
下图是展示本方法与其他分类网络性能的对比。
下图是展示数据模态转换的对比效果,前两行是深度图转RGB的效果对比。后两行是RGB图转换为深度图。
