python 视频播放网站开发/昆明seo网站建设
# 训练自己的数据进行目标检测
0.建立相关的目录
在项目根目录下新建VOCdevkitVOC2007Annotations、VOCdevkitVOC2007ImageSetsMain、VOCdevkitVOC2007JPEGImages、logs000四个目录
###### 1. 使用标注工具labelimg标注数据
链接:https://pan.baidu.com/s/1SO4NqNSfXyKMNCGQA-4LVQ 提取码:ydqi - 标注数据 open dir 选择需要标注的数据目录,change save dir 选择要保存的目录VOCdevkitVOC2007Annotations,use default label 勾选,填写一个标签名称,create Rectbox 标注数据,保存即可,如下图
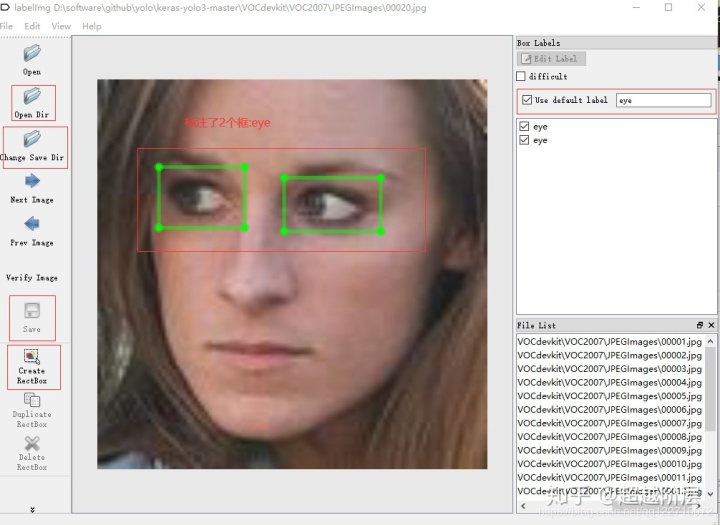
数据标注完成以后,会在VOCdevkitVOC2007Annotations目录下生成相关的.xml文件 ###### 2. 生成训练集测试集验证集 - 在VOC2007目录下新建一个dataShape.py文件,目的是用来分割数据,运行此文件会在VOCdevkitVOC2007ImageSetsMain目录下生成test.txt train.txt trainval.txt val.txt四个文件,dataShape.py文件代码如下:
``` import os import random
trainval_percent = 0.2 train_percent = 0.8 xmlfilepath = 'Annotations' txtsavepath = 'ImageSetsMain' total_xml = os.listdir(xmlfilepath)
num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') fval = open('ImageSets/Main/val.txt', 'w')
for i in list: name = total_xml[i][:-4] + 'n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name)
ftrainval.close() ftrain.close() fval.close() ftest.close()
###### 3.生成yolo3所需的train.txt,val.txt,test.txt
生成的数据集不能供yolov3直接使用。需要运行voc_annotation.py ,classes以检测一个类为例(眼睛),在voc_annotation.py需改你的数据集为:
~~~
classes = ["eye"]
~~~
运行`python voc_annotation.py`会生成 `2007_train.txt``2007_test.txt``2007_val.txt`,把这三个txt文件分别改名为 `train.txt``test.txt``val.txt`## 利用voc制作自己的数据集###### 4.修改参数文件yolo3.cfg
打开yolo3.cfg文件。搜索yolo(共出现三次),每次按下图都要修改[convolutional] size=1 stride=1 pad=1
filters:3(5+len(classes));<===> 3(5+1)
filters=18 activation=linear
[yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes: len(classes) = 1,这里是"eye"一类
classes=1 num=9 jitter=.3 ignore_thresh = .5 truth_thresh = 1
random:改为0
random=0
###### 5.修改model_data下的voc_classes.txt为自己训练的类别
~~~
eye
~~~
###### 6.生成`yolo_anchors.txt`文件
运行 `python kmeans.py`,会在根目录下生成`yolo_anchors.txt`文件,剪切到 `model_data`目录下###### 7.修改train.py代码(用下面代码直接替换原来的代码)
因为 train.py会报错。本人电脑 win10家庭版.坑死人了""" Retrain the YOLO model for your own dataset. """ import numpy as np import keras.backend as K from keras.layers import Input, Lambda from keras.models import Model from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss from yolo3.utils import get_random_data
def _main(): annotation_path = '2007_train.txt' log_dir = 'logs/000/' classes_path = 'model_data/voc_classes.txt' anchors_path = 'model_data/yolo_anchors.txt' class_names = get_classes(classes_path) anchors = get_anchors(anchors_path) input_shape = (416,416) # multiple of 32, hw model = create_model(input_shape, anchors, len(class_names) ) train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'): model.compile(optimizer='adam', loss={ 'yolo_loss': lambda y_true, y_pred: y_pred}) logging = TensorBoard(log_dir=log_dir) checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5", monitor='val_loss', save_weights_only=True, save_best_only=True, period=1) batch_size = 10 val_split = 0.1 with open(annotation_path) as f: lines = f.readlines() np.random.shuffle(lines) num_val = int(len(lines)*val_split) num_train = len(lines) - num_val print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),steps_per_epoch=max(1, num_train//batch_size),validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),validation_steps=max(1, num_val//batch_size),epochs=500,initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')def get_classes(classes_path): with open(classes_path) as f: class_names = f.readlines() class_names = [c.strip() for c in class_names] return class_names
def get_anchors(anchors_path): with open(anchors_path) as f: anchors = f.readline() anchors = [float(x) for x in anchors.split(',')] return np.array(anchors).reshape(-1, 2)
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False, weights_path='model_data/yolo_weights.h5'): K.clear_session() # get a new session image_input = Input(shape=(None, None, 3)) h, w = input_shape num_anchors = len(anchors) y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))if load_pretrained:model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)print('Load weights {}.'.format(weights_path))if freeze_body:# Do not freeze 3 output layers.num = len(model_body.layers)-7for i in range(num): model_body.layers[i].trainable = Falseprint('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})([*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return modeldef data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes): n = len(annotation_lines) np.random.shuffle(annotation_lines) i = 0 while True: image_data = [] box_data = [] for b in range(batch_size): i %= n image, box = get_random_data(annotation_lines[i], input_shape, random=True) image_data.append(image) box_data.append(box) i += 1 image_data = np.array(image_data) box_data = np.array(box_data) y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes) yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes): n = len(annotation_lines) if n==0 or batch_size<=0: return None return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if name == 'main': _main() ```
8.生成模型
运行python train.py,会在 logs000下生成日志文件和trained_weights_stage_1.h5模型文件
9.测试训练效果
把生成的trained_weights_stage_1.h5模型文件,改为yolo.h5,放在 model_data目录下,运行 python yolo_video.py --image,输入图片路径,查看测试效果
2020.01.02 20:54