嘉兴 做网站 推广/市场营销方案范文5篇
目录
定理1 MC control 收敛定理
定理2 SARSA 算法收敛定理
定理3 Q-learning 收敛理论
问题1: 新策略是随机的还是确定的?我们可以使用新策略计算得到的Q值去产生新的轨迹吗?
问题2:SARSA与Q-learning的区别?
问题3: on policy与off policy的区别?
问题4:Both SARSA and Q-learning may update their policy after every step,正确还是错误?
问题5 : 策略控制MC算法的理解
问题6: Maximization Bias Proof / Q值的最大化偏差估计
问题7:为什么Double Q-Learning能对状态-动作值产生无偏估计?
问题8:Q-Learning与Double Q-Learning的区别?
定理1 MC control 收敛定理

当MC control 满足GLIE条件的时候,就保证了该算法的收敛性。

定理2 SARSA 算法收敛定理

定理3 Q-learning 收敛理论

问题1: 新策略是随机的还是确定的?我们可以使用新策略计算得到的Q值去产生新的轨迹吗?
答:确定的,不可以。

问题2:SARSA与Q-learning的区别?
答:选择动作的更新策略不同,如下图所示:

从下面这道例题可以清楚的区别:
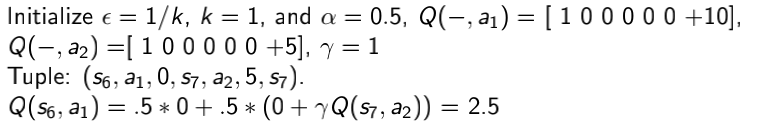
运用SARSA算法,得出的结果为2.5

运用Q-learning算法,得出的结果为5,为什么SARSA算法和Q-learning算法的结果有差?因为SARSA算法在状态7选择的动作是某轨迹中的真实动作,但是Q-learning算法选择的却是状态7所有轨迹中的Q值最大的动作。
问题3: on policy与off policy的区别?
答:易知,on policy learning,即同策学习、在线学习,off policy learning,即异策学习、离线学习。同策学习与异策学习的定义如下:

on policy在学习的过程中以及探索的过程中使用的都是同一个策略,即学习从该策略中获得的经验来评估该策略,例如SARSA算法,运用同一个策略去获取At,At+1,而off policy学习使用从不同策略中收集的经验来评估策略,在学习的过程中使用的是贪婪算法,但是在探索的过程中使用的是更激进的算法,例如通过选取下一个状态的Q值的最大值来确定行为。
问题4:Both SARSA and Q-learning may update their policy after every step,正确还是错误?
答:正确。因为这两个算法都是TD算法。
问题5 : 策略控制MC算法的理解

问题6: Maximization Bias Proof / Q值的最大化偏差估计
在有限样本中采用贪婪策略估计Q值会导致较大偏差,证明过程如红框中的内容所示:

为了解决这个问题,提出了Double Q-Learning
问题7:为什么Double Q-Learning能对状态-动作值产生无偏估计?

Double Q-Learning的思想,亦或者什么是Double Q-Learning?

如上所述,Double Q-Learning将样本分为独立的对Q值无偏估计的两部分,Double Q-Learning Q值更新的时候不再选取下一状态Q值的最大值时的动作/行为,而是选择当前状态Q值的最大值时的动作/行为。
问题8:Q-Learning与Double Q-Learning的区别?


Q-learning的伪代码为:

Q-Learning算法由于受到大规模的动作值过估计(overestimation)而出现不稳定和效果不佳等现象的存在,而导致overestimation的主要原因来自于最大化值函数(max)逼近,该过程目标是为了最大的累计期望奖励,而在这个过程中产生了正向偏差。而本文章作者巧妙的是使用了两个估计器(double estimator)去计算Q-learning的值函数,作者将这种方法定义了一个名字叫“Double Q-learning”(本质上一个off-policy算法),并对其收敛过程进行了证明(缺点:当然double Q-learning算法有时会低估动作值,但不会像Q学习那样遭受过高估计)。
论文地址: https://papers.nips.cc/paper/3964-double-q-learning.pdf
参考资料
https://blog.csdn.net/gsww404/article/details/103413124
斯坦福cs234课件:http://web.stanford.edu/class/cs234/index.html