个人网站策划书怎么做/搜易网服务内容
下面来看下,MapReduce用户对task执行的更多控制
The Task Execution Environment
Hadoop为map task和reduce task提供了运行环境信息。例如,一个map task 可以知道它正在处理的文件的名称,和一个map或reduce task可以找出已经尝试的次数、下表中的属性都可以在job的配置信息中访问到,在老的MapReduce API中可以通过Mapper或reducer的configuer()方法获得这些信息,其中配置作为参数传入。在新的API中,这些属性可以通过context对象获得,该对象被传入到Mapper和Reducer的方法中。

Speculative Execution(推测执行)
MapReduce 模型将job分割成若干task,然后并行运行的这些task的,这使得job的整体执行时间要少于顺序执行这些task的时间。那么执行缓慢的task,将影响job的执行时间,当一个job有上百或上千个task时,有几个“拖后腿”task是很常见的。
Task缓慢有多种原因,包括硬件故障、软件配置错误,但是缓慢的原因又很难检测出来,因为job已成功完成,尽管完成时间比预期的要长。Hadoop不会试着去分析和修复运行缓慢的task,而是自动推测,试着启动另外一个等效的task。这就是所谓的task“推测执行”。
speculative execution并不是在大约同一时间同时运行两个task,而是,调度器跟踪所有task的进度,推测执行只对明显低于平均速率的task(一般占较小比例),才启动一个副本task,当一个task成功完成,那么其所有正在运行的副本task将被杀死,因为不在需要了。如果原task在speculative task之前完成,那么speculative task将被杀死;如果speculative task 先完成,那么原task将被杀死。
Speculative Execution仅是一个优化措施,并不能使job的运行更可靠。如果存在bug,可能会引起task的挂起或运行缓慢。
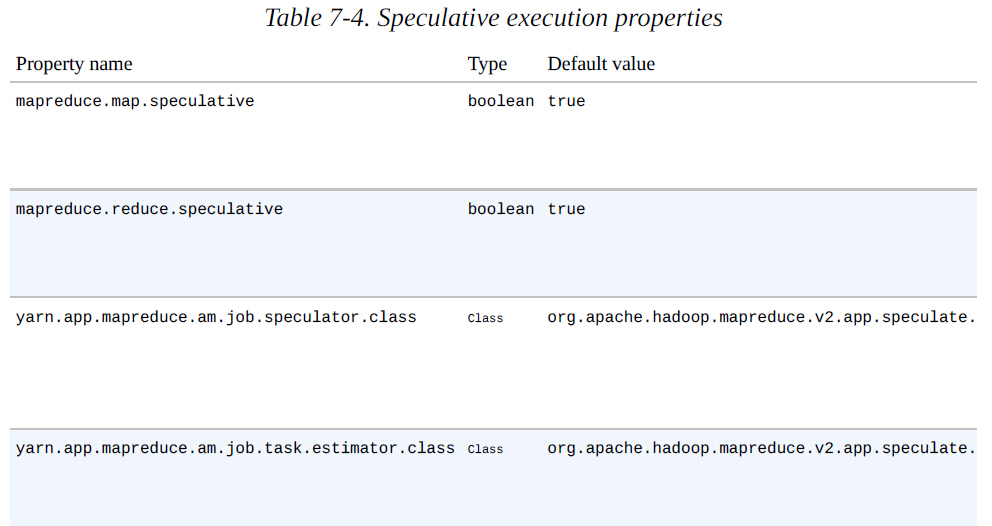
Speculative Execution默认是启用的,也可以单独的为map或reduce task、job、集群范围启用或停用。相关属性见下表:
Speculative Execution的目的就是减少job的执行时间的,但这是以牺牲集群效率为代价的。对于一个比较繁忙的集群,speculative execution 会降低整体的吞吐量,因为冗余的task正在执行。处于这个原因,一些集群管理员通常会关闭speculative execution,但用户可以为个别的job开启speculative execution。Hadoop老版本更是如此,因为它在调度speculative task时会过度使用speculative execution。
一个关闭speculative execution例子就是reduce task,因为任何speculative task会使用和原reduce task同样的map 输出,这就明显增加了集群的网络传输。
Output Committers
MapReduce使用一个commit协议,来确保job和task的要么完全成功,要么完全失败。该行为是由OutputCommitter实现,在旧的MapReduce API中,是通过掉JobConf的setOutputCommitter()方法或通过setting mapred.output.committer.class属性来设置。在新的MapReduce API中,OutputCommiter是由OutputFormat的getOutputCommitter()方法确定的,默认为FileOutputCommitter,这是基于文件处理的MapReduce。另外,如果有特殊需求,也可以为job或task自定义一个OutputCommitter或写一个新的实现。
OutputCommitter的API如下:
public abstract class OutputCommitter {public abstract void setupJob(JobContext jobContext) throws IOException;public void commitJob(JobContext jobContext) throws IOException { }public void abortJob(JobContext jobContext, JobStatus.State state) throws IOException { }public abstract void setupTask(TaskAttemptContext taskContext) throws IOException;public abstract boolean needsTaskCommit(TaskAttemptContext taskContext) throws IOException;public abstract void commitTask(TaskAttemptContext taskContext) throws IOException;public abstract void abortTask(TaskAttemptContext taskContext) throws IOException;
}
如果job成功,就会调用commitJob()方法,它将会删除临时工作空间,并创建一个隐藏的空的标记文件_SUCCESS,表示job成功完成。如果job没有成功,将会调用abortJob()方法,它带有一个state对象表示job是失败或被杀死(例如用户),默认它也会删除临时工作空间。
setupTask()方法是针对对Task的,它在task运行前调用,默认不做任何事情,因为在写task输出时已经为task的输出创建了临时目录。
task的commit阶段是可选,也可以通过needsTaskCommit().方法返回false来禁用,这将会使框架不必运行分布式提交协议,并且也不会调用commitTask() 、 abortTask()方法。当task没有输出可写时,FileOutputCommitter将跳过commit阶段。
如果task成功,将会调用commitTask()方法,它会将临时输出目录(为避免冲突,不同的task尝试以尝试ID作为目录名)移动到最终的输出路径${mapreduce.output.fileoutputformat.outputdir}。否则,将调用abortTask()方法,它将删除临时输出目录。
MapReduce框架对于一个特定的task,如果多个任务尝试的实例,可以确保仅有一个可以提交,其它的将被放弃。出现这种情况是因为某些原因第一次尝试失败,它将被放弃,之后的尝试成功的将被提交。也可能会发生两个尝试task同时在运行,这种情况,先执行完成的先提交,另一个将被放弃。