网站如何测试/小学生收集的新闻10条
脱敏与python实现
- 背景描述
- 原料
- 代码开发
- 实践效果
- 备注
- 参考内容
背景描述
兄弟小组来了个脱敏需求,希望将一些文件里客户资料和账户密码等信息做脱敏处理。
本来是想在项目里处理的,可是考虑到数据和文档并非是在项目中给出,因而决定使用python来处理,更加简单。
(这是第二次写python脚本,哪里有问题,请大家评论里指出。)
原料
py 3.9 版本,PyCharm 2020.2.3 x64版本,CSV文件
源码在文章里。
代码开发
python脚本如下:
import pandas as pd #导入pandas包
import sysdef main():filePath = sys.argv[1] #入参1 文件路径type = sys.argv[2] #入参2 文件类型,不同文件类型对应不同处理方法print(filePath)print(type)# filePath = 'D:/Code/pythonProject/VIP_KHXX20211203.csv' #测试地址#type = 1if type== '1':# 1# 如果执行后文件的编码格式有问题,可以在encoding这里来解决df = pd.read_csv(filePath,encoding='ANSI', header=0) #读文件 核心逻辑开始#print(df)df['客户名称'] = '张三' #把df里客户名称这一列全部设为某个值df['证件号码'] = '123456789012345678' #把df里证件号码这一列全部设为某个值print(df)df.to_csv(filePath, mode="w",encoding='ANSI' ,index=False) # 写入文件 #核心逻辑结束else :if type== '2':#2df = pd.read_csv(filePath,encoding='ANSI', header=0)#print(df)# df['交易密码'] = '锨潘拖儇'# df['资金密码'] = '锨潘拖儇'df['邮箱'] = '12345678@126.com'df['手机号码'] = '12345678901'print(df)df.to_csv(filePath, mode="w",encoding='ANSI' ,index=False) # 写入新文件else:if type =='3':# 3df = pd.read_csv(filePath, encoding='ANSI', header=0)# print(df)df['KHXM'] = '张三'df['ZJHM'] = '123456789012345678'df['MOBILE'] = '12345678901'df['DH'] = '021-12345678'df['EMAIL'] = '12345678@126.com'df['DZ'] = '上海市徐汇区xx路'# df['JYMM'] = '锨潘拖儇'# df['ZJMM'] = '锨潘拖儇'print(df)df.to_csv(filePath, mode="w", encoding='ANSI' ,index=False) # 写入新文件print("完成")
if __name__ == '__main__': # 入口main()
实践效果
执行 python CSV.py param1 param2 命令
(参数1和参数2分别是 路径和 文件类型,针对不同的文件类型将进行不同的字段脱敏。
你可以针对这段代码稍加更改,使之符合你的要求。)
就可以实现对excel文档里的敏感字段进行脱敏。(本机测试截图)
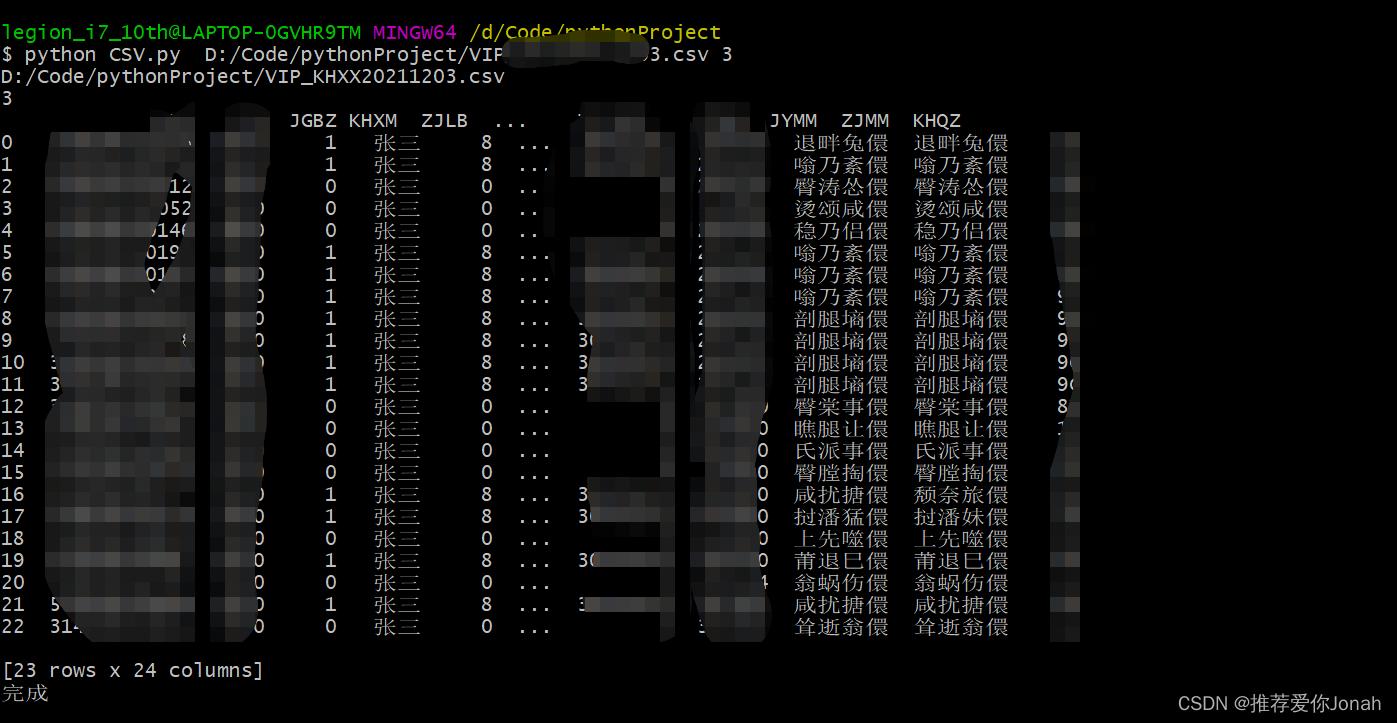
结果展示,本机测试数据

备注
1、执行代码需要考虑文件的编码格式,文件的编码格式应当在py执行前后保持不变。具体方案可以去看代码。我代码有注释。
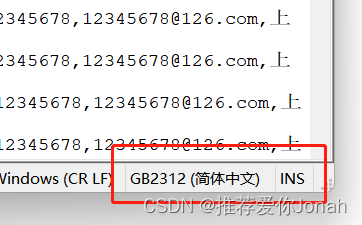 /
/
2、如果要到linux环境使用,需要在服务上配置py3和pandas,pandas版本太高会有问题。可以参考这个版本
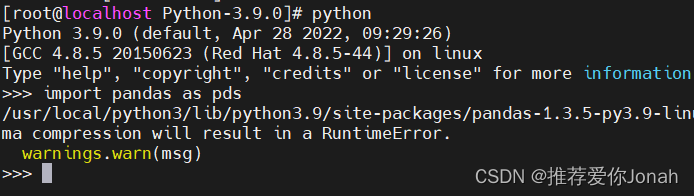
配置好之后就可以在linux上随便找个目录执行 命令了。
参考内容
https://blog.csdn.net/m0_37530301/article/details/110531728?spm=1001.2014.3001.5502
https://github.com/WuJonah/py_autoTest
https://www.liaoxuefeng.com/wiki/1016959663602400
其实还有很多参考,但过去一两周了,找不太到了。
想学习python又不想看英文的可以去看看廖雪峰的博客。第三个网址就是。