个人域名怎么申请/厦门seo搜索排名

在公众号的文章有源码链接。
前几天学了scrapy,虽然还不太明白,但是我也要试试用scrapy把之前的前程无忧爬虫改一下,而且不懂还可以问小哥哥鸭¯ω¯~
按照流程,先创建一个项目。打开命令行,进入存放项目的目录,输入“scrapy startprojcet 项目名”。

然后进去项目里, 创建一个爬虫。进入存放项目的目录后,输入“scrapy genspider 爬虫名”。

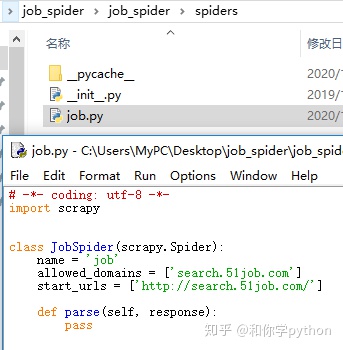
接下来编写items.py的代码,之前的目标是获取公司名、链接、职位名、工资、职位描述。
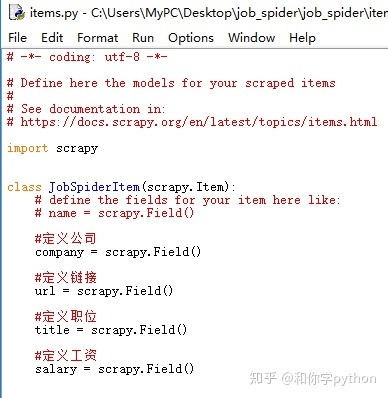
把之前的代码复制进job.py再修改一下¯ω¯~我真聪明
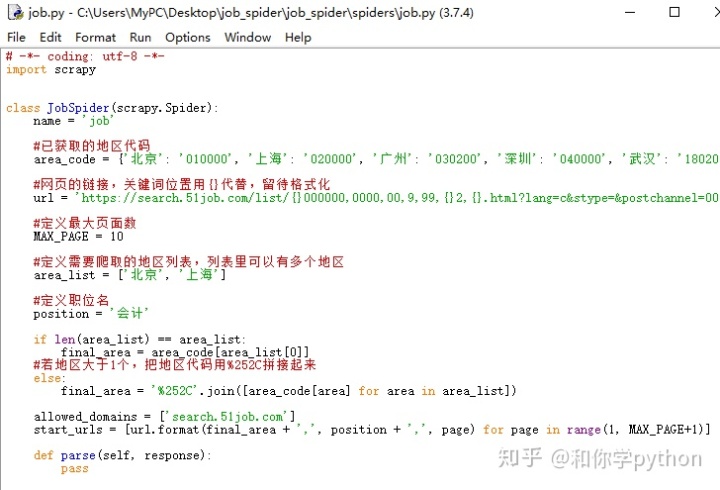
运行一下看有没有问题。
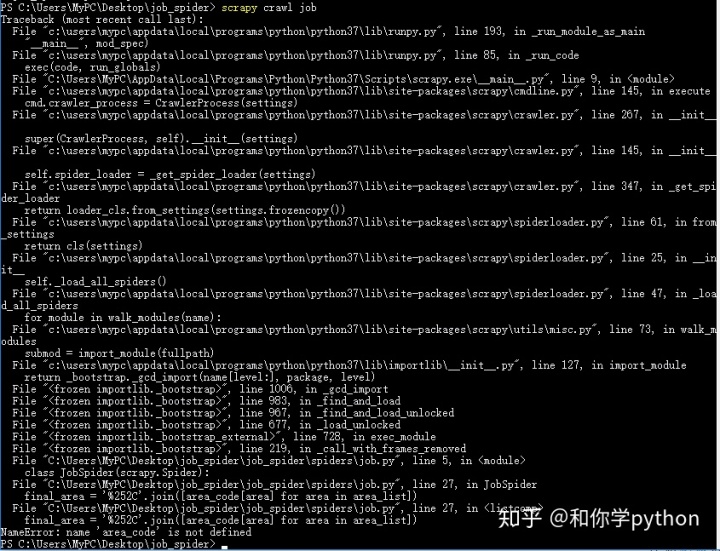
emmm……好像是说area_code没定义?我上面不是定义了吗?QAQ只好去求助小哥哥了。
惨绿青年:你试下重写start_requests方法把那些变量放到里面去试试。
我:什么是重写鸭?
惨绿青年:你直接写一个start_requests方法就行了,因为这个类本来有这个方法,你再写就会覆盖掉原来的方法。记得start_requests要返回scrapy.Request(),scrapy.Request()的使用方法和requests库类似。顺便把start_urls删掉吧。
惨绿青年:Request()的参数放url和需要使用的函数就可以了,当Request处理完url就会将结果作为参数去调用函数。下图是Request的部分源码,函数就是作为callback的参数。

我:好,我试试。

我:QAQ怎么还是不行鸭???
惨绿青年:scrapy.Request()的url参数需要字符串,你给了个列表,改一下吧……
我:好吧QAQ。

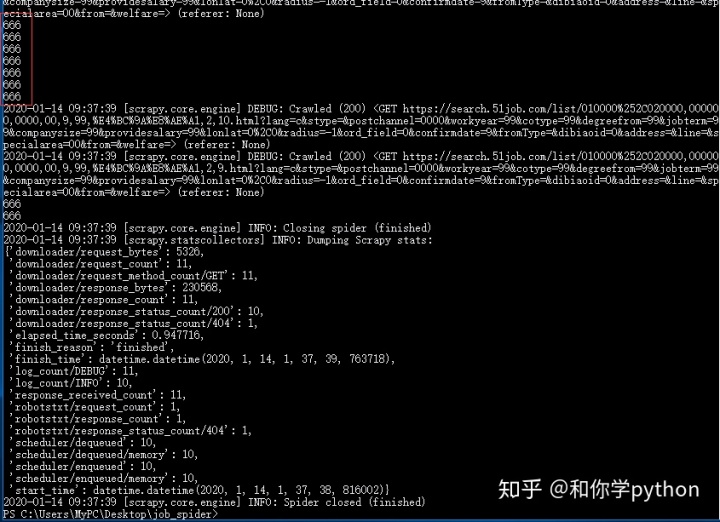
终于可以了QAQ,接下来把提取数据的代码也搬过去吧。这次改一下用xpath试试。
先看下链接,是a标签的href属性,上一层是span标签,再上一层是p标签,最上层是class为el的div标签。
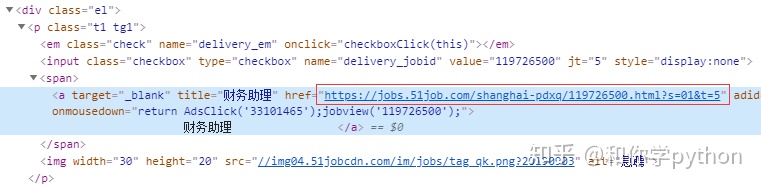
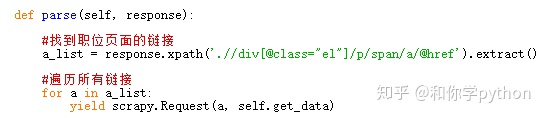
创建一个get_data函数获取职位页面的数据。
进入职位页面,看一下公司的名字,是class为cname的p标签下的a标签title属性。


网页链接直接可以从response获取。

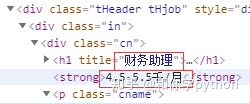
看一下职位名和工资,职位名在class为cn的div里h1标签的title属性里,工资在class为cn的div里的strong标签里。

最后就是职位描述了,在class为bmsg job_msg inbox的div下一层的p标签里。因为文本里有些空格,小哥哥教我用re()去清除。使用re()后返回一个列表,列表里是一个个的字符,所以用join()连接起来即可。
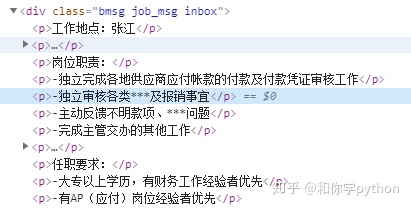

最后记得返回item。

试一下行不行。
好像还是不行QAQ,问一下小哥哥是什么回事?
惨绿青年:看了一下报错信息,应该是allowed_domains限制了爬取的域名,把它删掉就好。
按照小哥哥的教导,终于可以了。
打开保存的文件看一下。
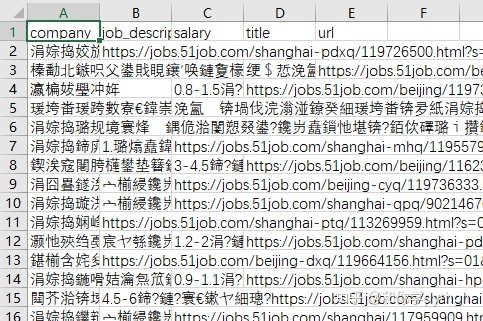
果然是乱码,按照之前的教程,在settings.py添加对应的代码试试。
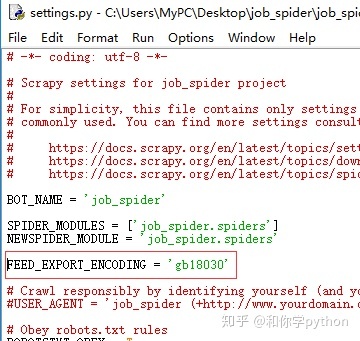
再看一下保存的文件。

没有乱码,而且没!有!空!行!但是有些职位描述是空白,我点进去看了下,有些职位描述是在class为bmsg job_msg inbox的div下一层的div标签里,有些甚至不在div标签和p标签里……只好改一下代码了。

修改代码后暂时没有发现问题,试了一下爬取20页的数据只需要16秒左右。20页数据每页50条,都上千条数据了!
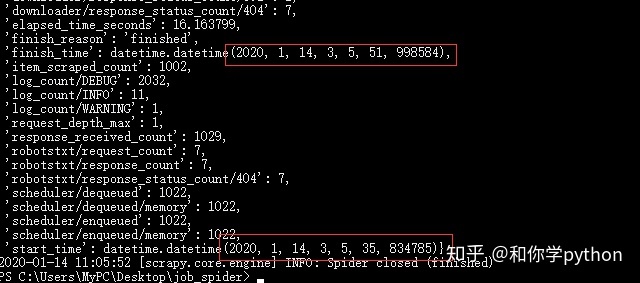
没想到scrapy这么厉害,1秒能爬100多条数据!这是第一次用scrapy写爬虫,还是把以前做过的改写,都花了很多时间QAQ。当然还是非常感谢惨绿青年小哥哥的教导啦,让我学到了这么多东西~
总结:
- allowed_domains用来限制爬取的域名,start_urls用来存放一开始爬取的链接。
- 需要用变量时可以重写start_requests()把变量放到里面试试。
- scrapy.Request()需要给一个链接,还需要指定callback的函数。
- 获取数据后记得返回item。
- 导出csv文件乱码时可以在settings.py修改设置。
今天也学到了很多东西呢,明天有什么新知识呢?真期待鸭~如果喜欢文章可以关注我哦~
