小程序免费制作平台有吗/seo优化技术厂家
在今天的视频当中,还是为大家介绍在数据科学项目初步阶段的数据处理,在之前的内容中,我们也有简单提到过。在今天视频的demo当中,主要介绍了Oracle ADS中对于数据集做概要了解的show_in_notebook()方法。
比如我们做一个保险费预测的例子,在这个例子当中,我们首先了解一下数据的基本情况,先使用常规的head()方法,查看一下大致的数据情况。
from ads.dataset.factory import DatasetFactoryds = DatasetFactory.open("insurance.csv", target="charges")ds.head()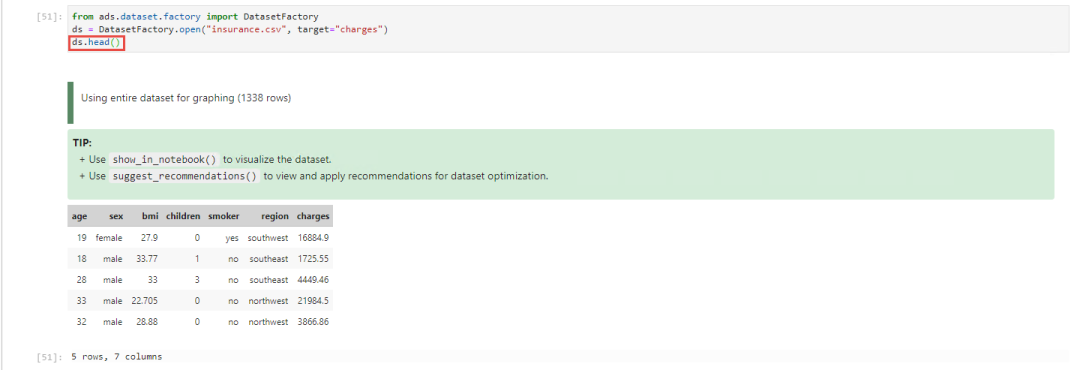
通过观察发现,一共有1338条记录,7个columns。接下来使用describe()命令都看看数据的分布,这里需要注意的是,默认情况下describe()只对数值型的数据做处理,如果想看其他类型的数据部分,可以加上include关键字,然后跟上参数,具体说明可以查询pandas官方文档中对dataframe的describe()方法的描述。
ds.describe(include='all')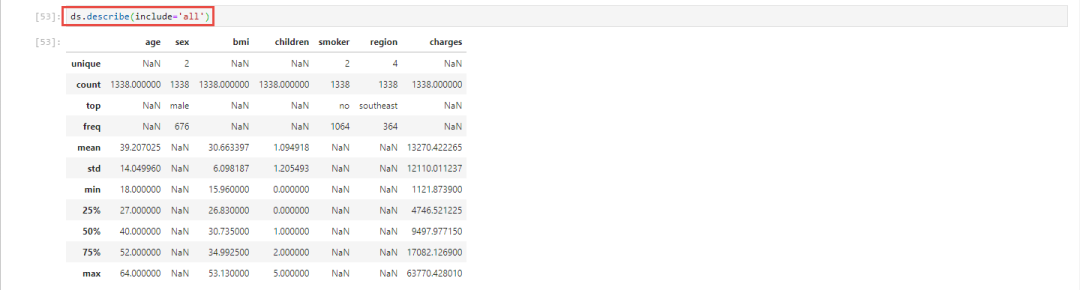
无论是使用head()还是describe(),查询出来的结果都不够直观,于是Oracle Data Science在ADS当中的DataFactory里面提供了一个show_in_notebook()方法,我们在创建DataFactory对象ds的时候,使用如下代码:ds = DatasetFactory.open("insurance.csv", target="charges"),在这个例子当中,我们将charges作为日后机器学习时候的预测目标,就如我们在数据科学课程中提到的,在数据预处理阶段的train_y一样。下面我们就通过两个例子看看show_in_notebook()的使用。这个方法或者叫做函数,不只是对DataFrame or DataFactory对象可以使用,对Series对象也可以使用,比如我们就看看这个target Charges,它的数据分布情况。通过下图可以发现,在ADS当中,默认情况下都会使用ADS认为合适的图形将数据展示出来。当然,您也可以选择自己喜欢的可视化图形进行显示。本次Charges是使用直方图来显示。
ds.target.show_in_notebook()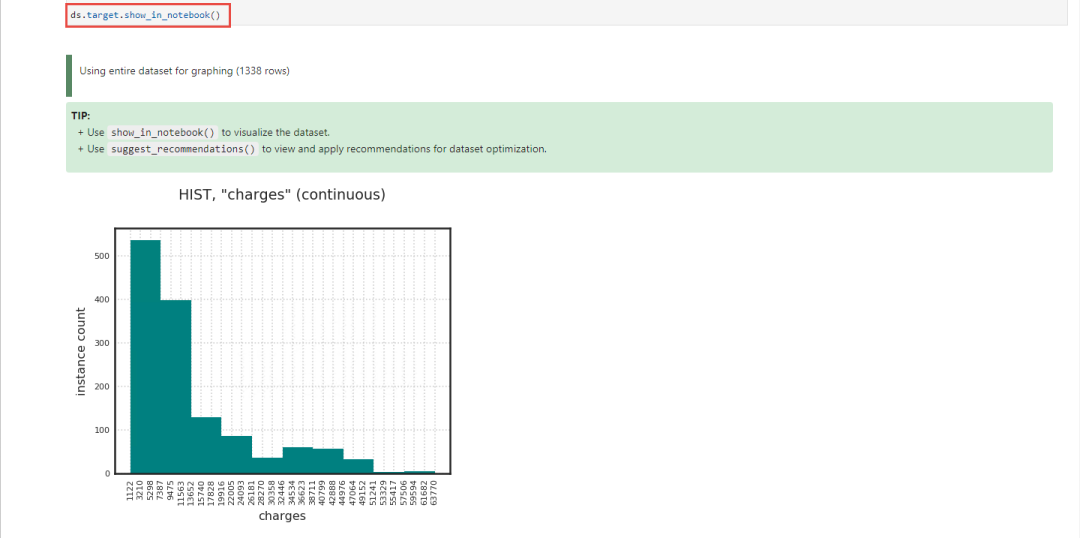
接下来,我们看看show_in_notebook的feature_names参数,如果对某一个Series使用show_in_notebook方法的时候,加入feature_names参数,结果会出现这个Series与feature_names中所提到的features的二维数据展现,比如在下面的例子当中,我们对target进行show_in_notebook(feature_names=['age','bmi']),会出现这两个features的维度下,target的值分布情况。需要注意的是,feature_names要使用list给出具体数据。
ds.target.show_in_notebook(feature_names=['age','bmi'])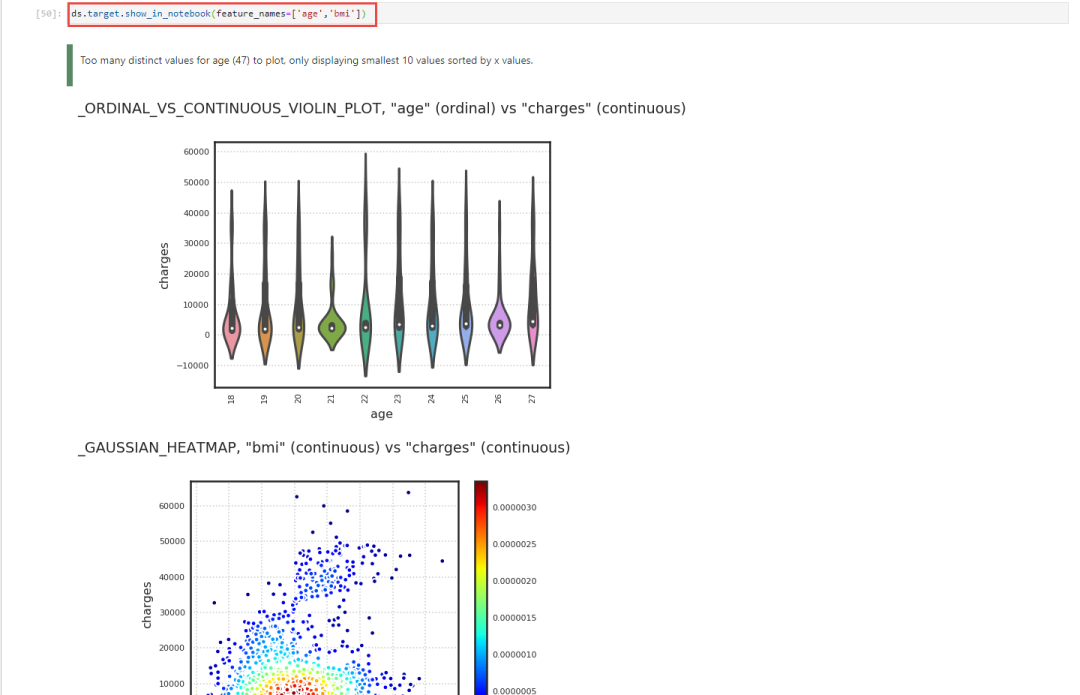

相关链接:
Oracle数据科学公开课(1):OCI基础
Oracle数据科学公开课(2):OCI Data Science Tenancy Setup
Oracle数据科学公开课(3): Resource Stack
Oracle数据科学公开课(4):Notebook的创建与管理
Oracle数据科学公开课(5):JupyterLab环境详解
Oracle数据科学公开课(6):Notebook Session Enviroment
Oracle数据科学公开课(7):ADS Python SDK
Oracle数据科学公开课(8):ADS Connectivity to Data
Oracle数据科学公开课(9):ADS特征选择
使用OCI的GPU环境实现去除照片马赛克
手把手教你:搭建Data Science环境
手把手教你:使用Oracle Data Science分析纽约民宿数据
扫描下方QR Code即刻预约ADW演示

编辑:殷海英