做垃圾网站/郑州关键词优化顾问
接上一个博客《Machine Learning In Action 学习笔记之 Logistic regression》,这使用的是Numpy进行回归,但我想改用Pytorch框架来写这个程序。
给定数据集(前两列为特征x1, x2,第三列为标签y) 如下所示:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
-0.026632 10.427743 0
0.850433 6.920334 1
1.347183 13.175500 0
1.176813 3.167020 1
…
原来是将数据转化为np.array形式,而为了使用Pytorch,就需要将numpy转化为tensor数据,使用torch.from_numpy()进行转化,数据导入与转换代码如下:
def loadData():fr = open('testSet.txt')X = []y = []for line in fr.readlines():lineArr = line.strip().split()X.append([float(lineArr[0]), float(lineArr[1])])y.append(int(lineArr[2]))X, y = loadData()X = np.array(X)y = np.array(y)# 转为tensor类型X = torch.from_numpy(X) y = torch.from_numpy(y)return X, y
但这里会出现一个问题:
 意思就是期望的数据类型为Float,但是给的数据类型是Double,所以报错。查了很久从这篇博客中发现了 from_numpy() 的一个问题:博客地址 , 其中,当 ndarray的类型是float64时,from_numpy(ndarray) 转化为 torch.DoubleTensor ,所以不能使用这样的转化函数,另辟蹊径,选择 torch.Tensor() 进行numpy的转化就没有错了。
意思就是期望的数据类型为Float,但是给的数据类型是Double,所以报错。查了很久从这篇博客中发现了 from_numpy() 的一个问题:博客地址 , 其中,当 ndarray的类型是float64时,from_numpy(ndarray) 转化为 torch.DoubleTensor ,所以不能使用这样的转化函数,另辟蹊径,选择 torch.Tensor() 进行numpy的转化就没有错了。
X = torch.Tensor(X)
因为Logistics Regression 的原理就是这张图:
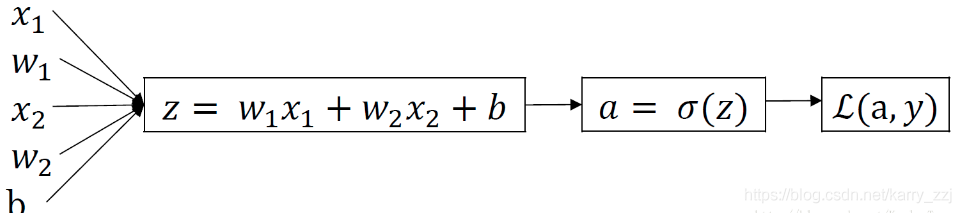
所以可以用Pytorch设计这样的神经网络:

一层为线性层,一层为sigmoid,
则代码如下:
class Logistic(nn.Module):def __init__(self, input_size, hidden_size):super(Logistic, self).__init__()self.layer = nn.Linear(input_size, hidden_size)self.sigmoid = nn.Sigmoid()def forward(self, X):out = self.layer(X)out = self.sigmoid(out)return out
然后开始 训练模型:
def main():X, y = loadData()# print(y)# 一定要将y的shape转化一下y = y.reshape([100, 1])#print(X)#print(y)# m为数据个数,n为特征数即input_sizem, n = X.shapeh_size = 1# 模型为modelmodel = Logistic(n, h_size)# 损失函数criterion = nn.MSELoss()# 优化器optimizer = optim.SGD(model.parameters(), lr = 0.01)for t in range(10000):# 通过模型生成y_predy_pred = model(X)#print(y_pred)# 如果不转换为float,会出ValueError: only one element tensors can be converted to Python scalarsloss = criterion(y.float(), y_pred.float())# 统计正确预测的个数mask = y_pred.ge(0.5).float()correct = (mask == y.float()).sum()accuracy = correct.item()/X.size(0)if t % 100 == 99:print("第{}次损失为{},正确率为{}".format(t, loss.item(), accuracy))# 把梯度置零(必须要)optimizer.zero_grad()# 求lossloss.backward()# 反向传播求stepoptimizer.step()
运行一下,结果如下:

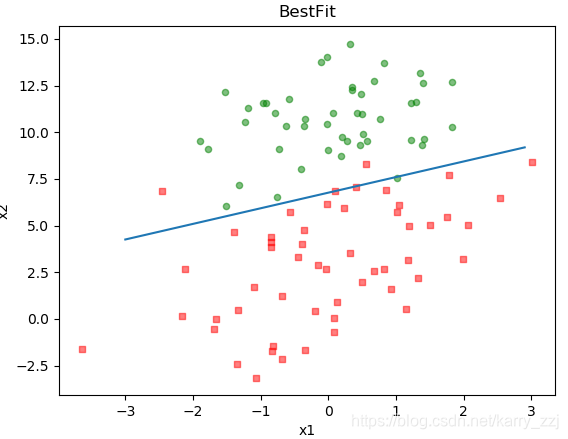
编写一下画图函数:
def plot(weights, bias):# 加载数据集dataMat, labelMat = loadData()# 转换成numpy的array数组dataArr = np.array(dataMat)#print(dataArr)# 数据个数# 例如建立一个4*2的矩阵c,c.shape[1]为第一维的长度2, c.shape[0]为第二维的长度4n = np.shape(dataMat)[0]# 正样本xcord1 = []ycord1 = []# 负样本xcord2 = []ycord2 = []# 根据数据集标签进行分类for i in range(n):if int(labelMat[i]) == 1:# 1为正样本xcord1.append(dataArr[i, 0])ycord1.append(dataArr[i, 1])else:# 0为负样本xcord2.append(dataArr[i, 0])ycord2.append(dataArr[i, 1])# 新建图框fig = plt.figure()# 添加subplotax = fig.add_subplot(111)# 绘制正样本ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5)# 绘制负样本ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5)# x轴坐标x = np.arange(-3.0, 3.0, 0.1)# w1*x1 + w2*x2 + b = 0# x1 = x, x2 = yy = (- bias - weights[0][0] * x ) / weights[0][1]ax.plot(x, y)# 绘制titleplt.title('BestFit')# 绘制labelplt.xlabel('x1')plt.ylabel('y2')# 显示plt.show()
从模型中取出线性层的参数,然后画图即可
# 取出线性层参数params=model.state_dict()weights = params['layer.weight']bias = params['layer.bias']#print(weights.numpy())#print(bias.numpy()[0])plot(weights.numpy(), bias.numpy()[0])
最后显示为: