原文链接:
https://mp.weixin.qq.com/s/WTqdSz-lc5zzelJgk4Co8g
写volatile的文章非常多,本人也看过许多相关文章,但始终感觉有哪里不太明白,但又说不上来说为什么。可能是过于追求底层实现原理,老想问一个为什么吧。
而写这篇文章的目的很简单,就是突然之间明白了volatile为什么要这样设计了。好东西当然要拿出来分享了,于是就有了这篇文章。
我们就从硬件到软件,再到具体的案例来聊聊volatile的底层原理,文章比较长,可收藏之后阅读。
CPU缓存的出现
最初的CPU是没有缓存区的,CPU直接读写内存。但这就存在一个问题,CPU的运行效率与读写内存的效率差距百倍以上。总不能CPU执行1个写操作耗时1个时钟周期,然后再等待内存执行一百多个时钟周期吧。
于是在CPU和内存之间添加了缓存(CPU缓存:Cache Memory),它是位于CPU和内存之间的临时存储器。这就像当Mysql出现瓶颈时,我们会考虑通过缓存数据来提升性能一样。总之,CPU缓存的出现就是为了解决CPU和内存之间处理速度不匹配的问题而诞生的。
这时,我们有一个粗略的图:
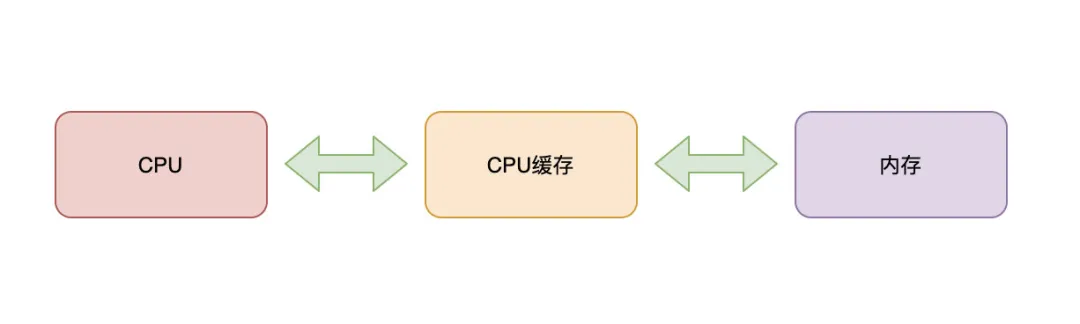
CPU-CPU缓存-内存
但考虑到进一步优化数据的调度,CPU缓存又分为一级缓存、二级缓存、三级缓存等。它们主要用于优化数据的吞吐和暂存,提高执行效率。
目前主流CPU通常采用三层缓存:
- 一级缓存(L1 Cache):主要用于缓存指令(L1P)和缓存数据(L1D),指令和数据是分开存储的。一级缓存属于核心独享,比如4核电脑,则有4个L1。
- 二级缓存(L2 Cache):二级缓存的指令和数据是共享的,二级缓存的容量会直接影响CPU的性能,越大越好。二级缓存同样属于核心独享,4核心电脑,则有4个L2。
- 三级缓存(L3 Cache):作用是进一步降低内存的延迟,同时提升海量数据计算的性能。三级缓存属于核心共享的,因此只有1个。
经过上述细分,可以将上图进一步细化:
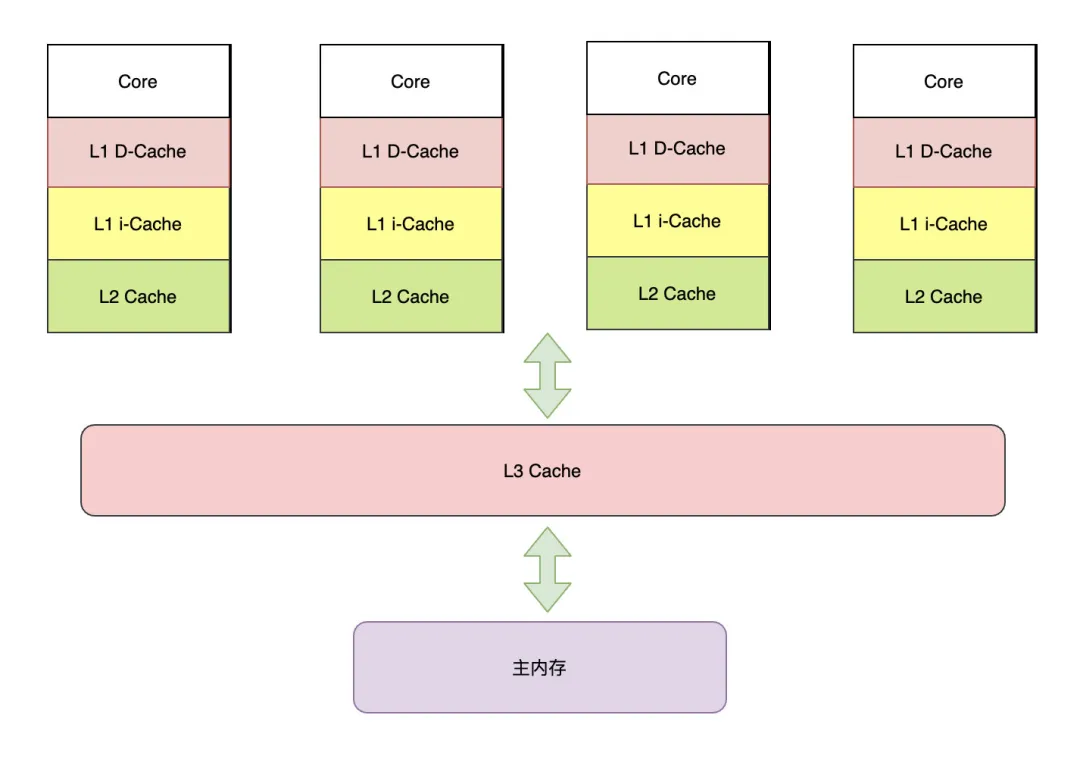
CPU三级缓存
这里再补充一个概念:缓存行(Cache-line),它是CPU缓存存储数据的最小单位,后面会用到。上面的CPU缓存,也称作高速缓存。
引入缓存之后,每个CPU的处理过程为:先将计算所需数据缓存在高速缓存中,当CPU进行计算时,直接从高速缓存读取数据,计算完成再写入缓存中。当整个运算过程完成之后,再把缓存中的数据同步到主内存中。
如果是单核CPU这样处理没有什么问题。但在多核系统中,每个CPU都可能将同一份数据缓存到自己的高速缓存中,这就出现了缓存数据一致性问题了。
CPU层提供了两种解决方案:总线锁和缓存一致性。
总线锁
前端总线(也叫CPU总线)是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号、通过地址总线发送地址信号指定其要访问的部件、通过数据总线双向传输。
比如CPU1要操作共享内存数据时,先在总线上发出一个LOCK#信号,其他处理器就不能操作缓存了该共享变量内存地址的缓存,也就是阻塞了其他CPU,使该处理器可以独享此共享内存。
很显然,这样的做法代价十分昂贵,于是为了降低锁粒度,CPU引入了缓存锁。
缓存一致性协议
缓存一致性:缓存一致性机制整体来说,就是当某块CPU对缓存中的数据进行操作了之后,会通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取。
缓存锁的核心机制就是基于缓存一致性协议来实现的,即一个处理器的缓存回写到内存会导致其他处理器的缓存无效,IA-32处理器和Intel 64处理器使用MESI实现缓存一致性协议。
缓存一致性是一个协议,不同处理器的具体实现会有所不同,MESI是一种比较常见的缓存一致性协议实现。
MESI协议
MESI协议是以缓存行的几个状态来命名的(全名是Modified、Exclusive、Share or Invalid)。该协议要求在每个缓存行上维护两个状态位,每个数据单位可能处于M、E、S和I这四种状态之一,各种状态含义如下:
- M(Modified):被修改的。该状态的数据,只在本CPU缓存中存在,其他CPU没有。同时,对于内存中的值来说,是已经被修改了,但还没更新到内存中去。也就是说缓存中的数据和内存中的数据不一致。
- E(Exclusive):独占的。该状态的数据,只在本CPU缓存中存在,且并没有被修改,与内存数据一致。
- S(Share):共享的。该状态的数据,在多个CPU缓存中同时存在,且与内存数据一致。
- I(Invalid):无效的。本CPU中的这份缓存数据已经失效。
其中上述状态随着不同CPU的操作还会进行不停的变更:
- 一个处于M状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回主内存。
- 一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
- 一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到,则必须把其缓存行状态设置为S。
对于MESI协议,从CPU读写角度来说会遵循以下原则:
CPU读数据:当CPU需要读取数据时,如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S,如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
CPU写数据:当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU设置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为M。
当引入总线锁或缓存一致性协议之后,CPU、缓存、内存的结构变为下图:
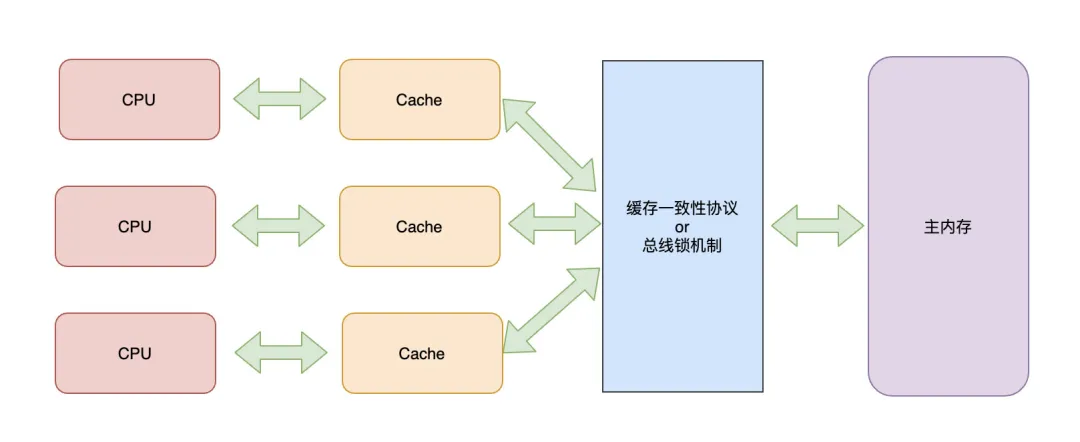
CPU-缓存-总线-内存
MESI协议带来的问题
在上述MESI协议的交互过程中,我们已经可以看到在各个CPU之间存在大量的消息传递(监听处理)。而缓存的一致性消息传递是需要时间的,这就使得切换时会产生延迟。一个CPU对缓存中数据的改变,可能需要获得其他CPU的回执之后才能继续进行,在这期间处于阻塞状态。
Store Bufferes
等待确认的过程会阻塞处理器,降低处理器的性能。而且这个等待远远比一个指令的执行时间长的多。为了避免资源浪费,CPU又引入了存储缓存(Store Bufferes)。
基于存储缓存,CPU将要写入内存数据先写入Store Bufferes中,同时发送消息,然后就可以继续处理其他指令了。当收到所有其他CPU的失效确认(Invalidate Acknowledge)时,数据才会最终被提交。
举例说明一下Store Bufferes的执行流程:比如将内存中共享变量a的值由1修改为66。
第一步,CPU-0把a=66写入Store Bufferes中,然后发送Invalid消息给其他CPU,无需等待其他CPU相应,便可继续执行其他指令了。
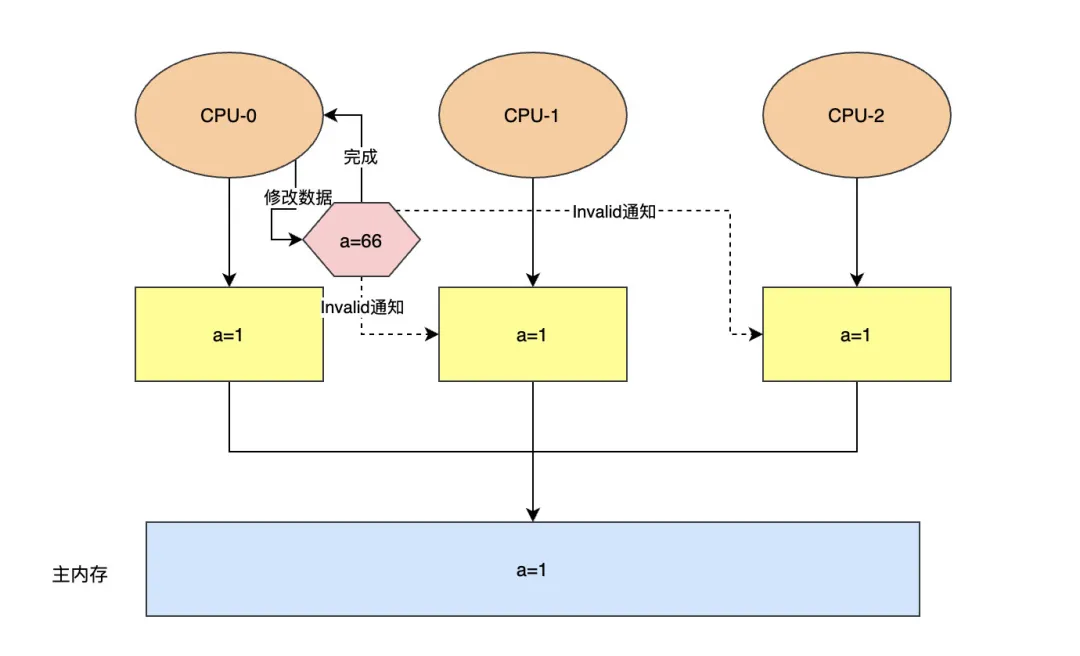
store bufferes
第二步,当CPU-0收到其他所有CPU对Invalid通知的相应之后,再把Store Bufferes中的共享变量同步到缓存和主内存中。
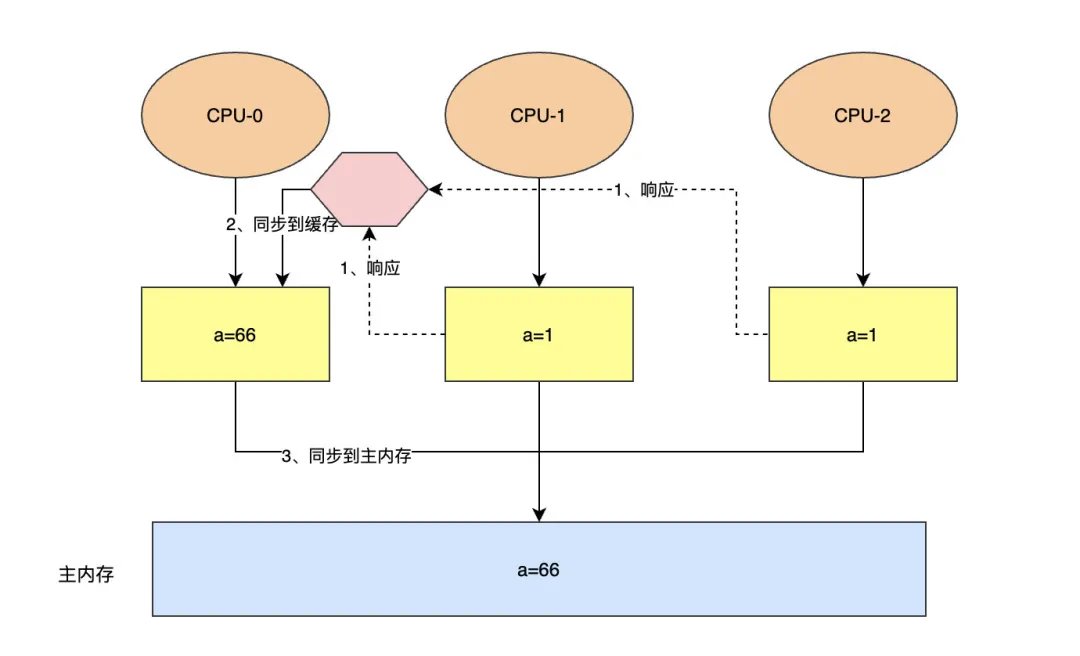
store Bufferes
Store Forward(存储转发)
Store Bufferes的引入提升了CPU的利用效率,但又带来了新的问题。在上述第一步中,Store Bufferes中的数据还未同步到CPU-0自己的缓存中,如果此时CPU-0需要读取该变量a,缓存中的数据并不是最新的,所以CPU需要先读取Store Bufferes中是否有值。如果有则直接读取,如果没有再到自己缓存中读取,这就是所谓的”Store Forward“。
失效队列
CPU将数据写入Store Bufferes的同时还会发消息给其他CPU,由于Store Bufferes空间较小,且其他CPU可能正在处理其他事情,没办法及时回复,这个消息就会陷入等待。
为了避免接收消息的CPU无法及时处理Invalid失效数据的消息,造成CPU指令等待,就在接收CPU中添加了一个异步消息队列。消息发送方将数据失效消息发送到这个队列中,接收CPU返回已接收,发送方CPU就可以继续执行后续操作了。而接收方CPU再慢慢处理”失效队列“中的消息。
内存屏障
CPU经过上述的一系列优化,既保证了效率又确保了缓存的一致性,大多数情况下也是可以接受CPU基于Store Bufferes和失效队列异步处理的短暂延迟的。
但在多线程的极端情况下,还是会产生缓存数据不一致的情况的。比如上述实例中,CPU-0修改数据,发消息给其他CPU,其他CPU消息队列接收成功并返回。这时CPU-1正忙着处理其他业务,没来得及处理消息队列,而CPU-1处理的业务中恰好又用到了变量a,此时就会造成读取到的a值为旧值。
这种因为CPU缓存优化导致后面的指令无法感知到前面指令的执行结果,看起来就像指令之间的执行顺序错乱了一样,对于这种现象我们俗称“CPU乱序执行”。
乱序执行是导致多线程下程序Bug的原因,解决方案很简单:禁用CPU缓存优化。但大多数情况下的数据并不存在共享问题,直接禁用会导致整体性能下降,得不偿失。于是就提供了针对多线程共享场景的解决机制:内存屏障机制。
使用内存屏障后,写入数据时会保证所有指令都执行完毕,这样就能保证修改过的数据能够即时暴露给其他CPU。而读取数据时,能够保证所有“失效队列”消息都消费完毕。然后,CPU根据Invalid消息判断自己缓存状态,正确读写数据。
CPU层面的内存屏障
CPU层面提供了三类内存屏障:
- 写屏障(Store Memory Barrier):告诉处理器在写屏障之前将所有存储在存储缓存(store bufferes)中的数据同步到主内存。也就是说当看到Store Barrier指令,就必须把该指令之前所有写入指令执行完毕才能继续往下执行。
- 读屏障(Load Memory Barrier):处理器在读屏障之后的读操作,都在读屏障之后执行。也就是说在Load屏障指令之后就能够保证后面的读取数据指令一定能够读取到最新的数据。
- 全屏障(Full Memory Barrier):兼具写屏障和读屏障的功能。确保屏障前的内存读写操作的结果提交到内存之后,再执行屏障后的读写操作。
下面通过一段伪代码来进行说明: