济宁市任城区建设局网站/seo高级优化方法
视觉转换器(ViT)作为卷积神经网络(CNN)的有力替代方案,受到了广泛的关注。最近的研究表明,vit也容易受到cnn等对抗实例的攻击。为了构建健壮的vit,一种直观的方法是应用对抗性训练,因为它已被证明是实现健壮cnn的最有效方法之一。然而,对抗训练的一个主要限制是它的计算成本很高。ViTs采用的自注意机制是一种计算强度较大的操作,其费用随着输入补丁数量的增加而成倍增加,使得ViTs上的对抗性训练更加耗时。在这项工作中,我们首先全面研究了各种视觉转换器上的快速对抗训练,并说明了效率与鲁棒性之间的关系。然后,为了加快vit的对抗训练,我们提出了一种有效的注意力引导对抗训练机制。具体来说,在对抗性训练中,我们依靠自注意的特性,采用注意引导的掉落策略,主动去除每一层的某些补丁嵌入。精简的自我注意模块显著加速了vit的对抗性训练。只需65%的快速对抗性训练时间,我们就能在具有挑战性的ImageNet基准测试中达到最先进的结果。
Fast Adversarial Training on Vision Transformers
我们将Fast AT应用于广泛的ViT。我们从五个视觉变压器家族中选择了19种不同尺寸的型号结果表明,vit始终比cnn更健壮。这与同时进行的模型鲁棒性研究相一致。我们得出以下新颖的结论:
- 在同一transformer家族中,较大的变压器并不总是具有更好的鲁棒性
- 在不同的变压器家族中,为更好的自然性能而设计的注意机制并不一定会带来更好的鲁棒性。
- SOTA vit存在严重的效率问题,并且需要比SOTA cnn更多的训练时间
Computation Intensity of ViTs
对于每个矩阵,我们在右下角显示它的形状,在右上角显示它的索引,输入特征为:,它由维数为d的p个嵌入序列组成:
![]()
每个嵌入都与输入图像的一个特定的非重叠补丁有关,ViT由一组块组成,每个块由两种计算组成:Multihead Self-Attention layer (MSA) and the Multi-Layer Perceptron layer (MLP).
在MSA中,X首先通过层归一化进行归一化,然后转换成query、key、value矩阵(K,Q,V):

对于多头设计,将形状为pxd的K、Q、V矩阵划分为h个头,每个部分的形状为,以第一个头为例,
对
进行重加权
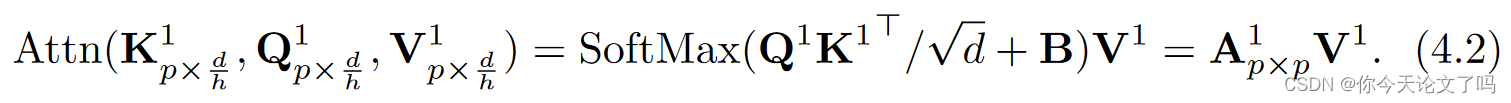
所有的列向量都是softmax标准化的,因此每个列向量的和都是1,然后将每个磁头的AV值进行拼接转换为MSA的输出:
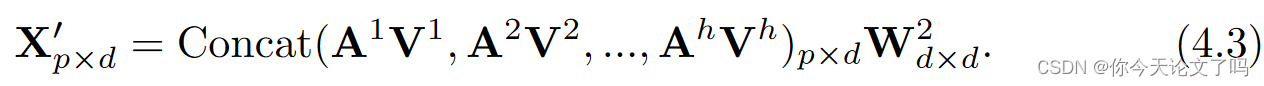
MLP接收MSA的输出X‘,并使用层归一化和GELU激活转换每个嵌入:
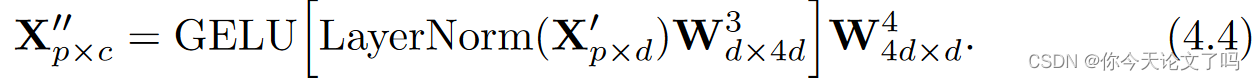
整个过程的复杂度为:
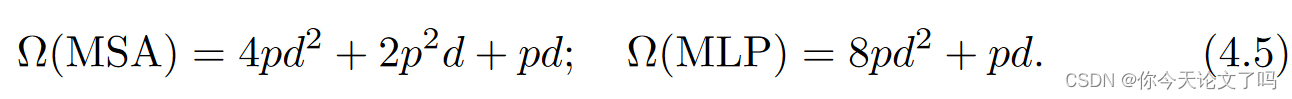
Dropping Patch: The Flexibility of Self-Attention
研究人员还研究了动态地丢弃ViT模型正向通道中的补丁或嵌入。结果表明,当丢弃一定数量的补丁时,前向推理可以显著加速。同时,模型的性能只会有轻微的下降。
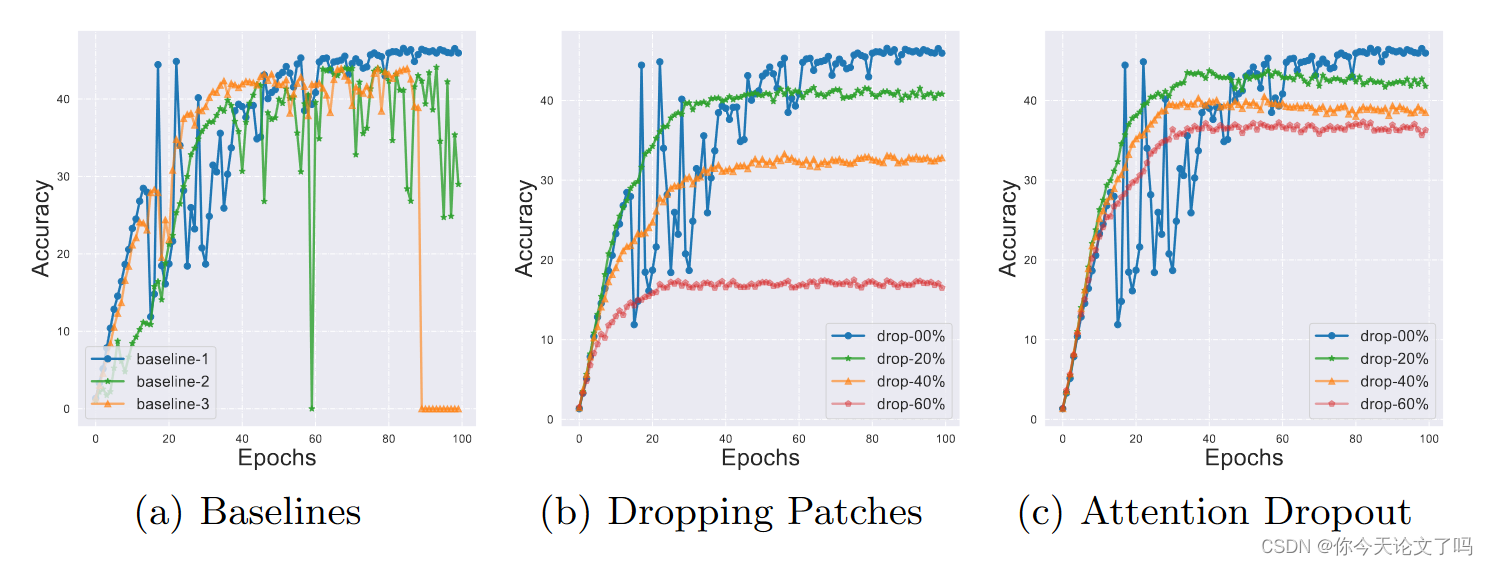
在这项工作中,我们探索了一种补丁掉落策略,以加速对抗性训练,因为它实现了出色的权衡。我们首先测试了随机丢弃一定数量输入补丁的方案,看看它如何影响Fast AT的训练质量。我们在图3(b)中报告了结果,其中我们绘制了针对不同下降比率的训练时期的稳健性。请注意,在测试阶段的推断过程中不会丢弃任何补丁。减少输入补丁的数量,可以加快ViT的正向推理。令人惊讶的是,从图中我们还观察到,下降操作也稳定了对抗训练,缓解了灾难性过拟合的现象。如图3(a)所示,我们重复三次Fast AT,没有任何掉落。训练过程可能非常不稳定,有时准确率会降至零。我们推测正是由于丢片操作带来的正则化效应使Fast AT稳定。为了进一步验证这一猜想,我们测试了DeiT[72]中配备了dropout操作的vit。退出模块应用于自我关注模块之后。如图3(c)所示,注意缺失模块与掉落补丁一样,也稳定了Fast AT。与删除补丁不同,删除模块不能节省计算量。然而,在两种情况下,当使用下降时,最终的鲁棒精度都会降低。随机补丁掉落策略造成了一个困境。也就是说,它带来了加速和性能下降
Attention-Guided Adversarial Training
对抗实例的质量取决于对抗攻击算法。攻击算法依赖于准确估计输入像素相对于损失函数的梯度。因此,实现我们目标的一个主要见解是删除几乎不会妨碍梯度估计的补丁。注意力的大小可以揭示嵌入的显著程度。
将按行求和,并生成索引向量a,其列是加权平均参数,和恒为1 ,列表示生成的嵌入接收到每个输出嵌入的信息的多少,行揭示了每个输入嵌入对输出嵌入的影响程度,这个值因嵌入不同而不同,因此,我们选择基于它们在a中的大小来选择top-k嵌入,等式(4.3)可以写成:
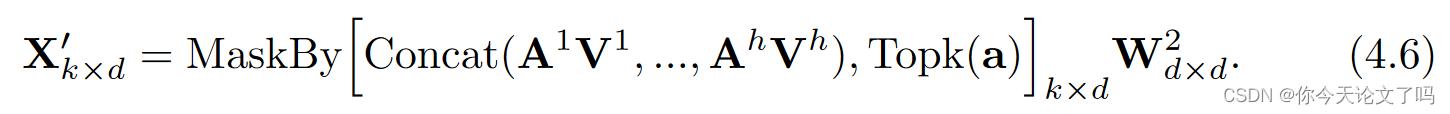
我们在AV的加权平均计算之后去掉了嵌入,使得嵌入的量级保持稳定。嵌入的数量将从p减少到k。为了充分利用每一层的注意力信息,我们提出了一种分层的指数下降方案。也就是说,在每一层中,我们都会掉落固定比例的补丁。因此,该方案将在更深的层上放置更多的嵌入,在更深的层中嵌入始终是更冗余的。我们将掉落率设置为0.9。在一个12层的ViT-Base模型上,最后一层将只处理31%的嵌入数量,并节省整个模型40%以上的FLOPs。算法1中显示了我们的注意力引导对抗训练的详细实现。我们的AGAT只是修改了训练过程。在测试过程中,我们使用原始模型进行预测。当涉及前馈过程时,类标签将不会被删除
