网站开发 武汉/四川网站推广公司

处理数据就避不开对日期的处理,日期可以是数据,也可以是索引;每一条记录可能是一年、一个季度、一个月、一周甚至是每3天。
Pandas的date_range()功能极为强大,几乎可以满足你所有对日期的想法,基本的调用方法是这样的。

可以看到返回的是日期索引类型,里面是10个连续的datetime类型的日期型元素。注意freq='D'的参数,我会在后面展示它的强大。
如果你只想得到从2021-1-1开始10天的日期索引,还有比上面更简单的写法:

对,传入起始日期和periods=10,就可以得到包括起始日期在内的10个连续日期。
刚刚说的freq是频率参数,怎么看它的强大呢?
来来来,先来点小菜。

freq='M'取得的是12个月的日期序列,M代表了月。大家留意一下,生成的日期是当月的最后一天。
如果我想取每个月的第一天呢?

季度末

其实date_range()的确有季末参数,就是freq='Q'

date_range()起止参数包括其自身,当然,也可以像Python的range()一样,使用closed参数。

该参数缺省是None,你也可以用right试试。
工作日

两天

每周的第一天(周日)
由于西方习惯,取每周第一天是日期区间的每周日。

做了一个简单的表(好吧,是用pandas.read_html生成的,再用concat处理了一下),大家可以逐一试一试。
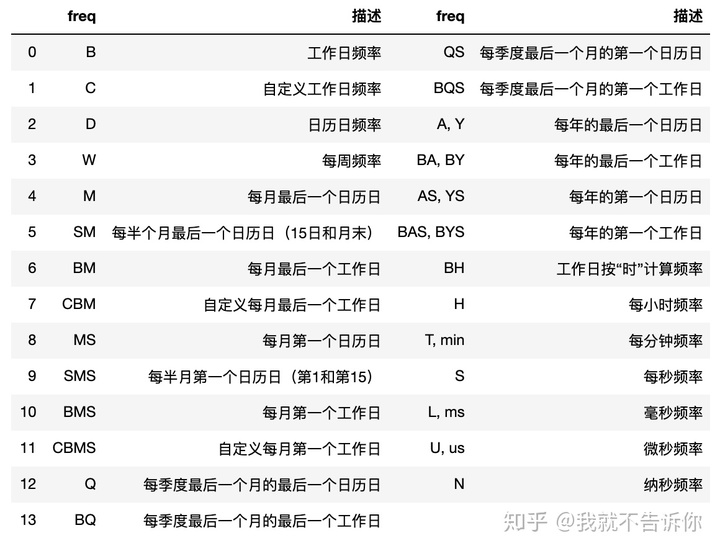
最后给大家一个实用操作,算是这节的实践课,课后可以尝试。
随机生成两个日期区间的随机日期
在处理海量数据前,我们要生成模拟数据对数据分析程序进行测试。生日是经常要做的,如果人工生成,或是胡乱输入那就太痛苦了。
我们用date_range()可以做一个简单的日期生成器。
# 随机日期生成器
start = '1963-01-01' # 起始日期
end = '2000-03-10' # 终止日期
n = 12 # 生成日期个数# 随机生成日期
x = np.random.randint(pd.to_datetime(start).value, pd.to_datetime(end).value,n)
random_dates = [pd.to_datetime((i/10**9)/(60*60)/24, unit='D').strftime('%Y-%m-%d') for i in x]我给出了代码,大家拷贝方便。
试一下效果

这个数据太单调,不立体,咱们再加上名字。
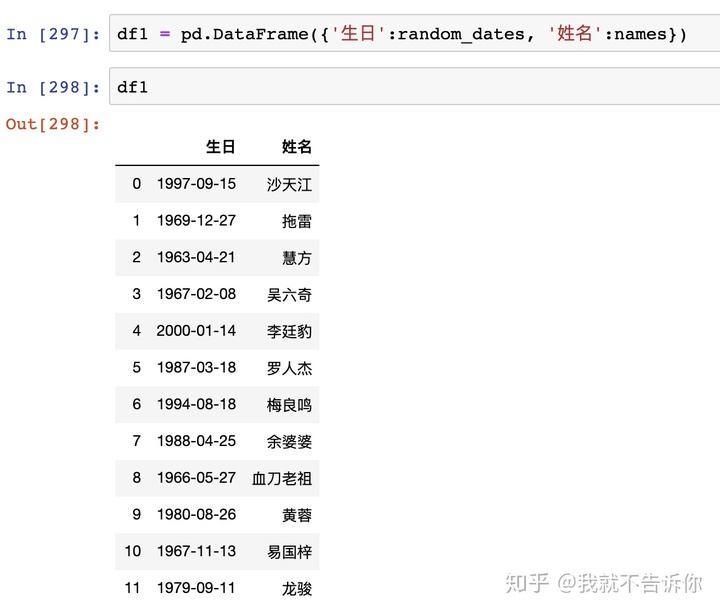
怎么样?看到黄蓉同学还是80后,你是不是感觉与有荣焉呢?
这节课就到这里。