所有网站域名都有/seo百度关键词优化软件
如何通过剪枝使模型更小,含代码示例及详细解释。
作者:Derrick Mwiti编译:McGL
在上一篇文章“神经网络剪枝2019”(点击文末阅读原文可以打开知乎原文)中,我们回顾了一些关于修剪神经网络的优秀文献。我们了解到,剪枝是一种模型优化技术,包括去掉权重张量中不必要的值。这使模型更小且精度和基线模型非常接近。
在本文中,我们将通过一个示例来应用剪枝,并查看对最终模型大小和预测误差的影响。
导入常见的模块
我们的第一步是导入模块:
os及zipfile可以帮助我们评估模型的大小tensorflow_model_optimization用于模型剪枝load_model加载保存的模型当然还有
tensorflow和keras
最后,初始化 TensorBoard,这样我们就能将模型可视化:
import osimport zipfileimport tensorflow as tfimport tensorflow_model_optimization as tfmotfrom tensorflow.keras.models import load_modelfrom tensorflow import keras%load_ext tensorboard
数据集生成
对于这个实验,我们使用 scikit-learn 生成一个回归数据集。然后,我们将数据集划分为一个训练和测试集:
from sklearn.datasets import make_friedman1X, y = make_friedman1(n_samples=10000, n_features=10, random_state=0)from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
没有剪枝的模型
我们将创建一个简单的神经网络来预测目标变量 y,然后我们检查均方差。之后,我们将它与全局剪枝后的模型比较,然后与只剪稠密层的模型比较。
def setup_model(): model = keras.Sequential([ keras.layers.Dense(units = 128, activation='relu',input_shape=(X_train.shape[1],)), keras.layers.Dense(units=1, activation='relu')]) return model
接下来,设置一个callback,30个epochs后,一旦模型性能停止提升,我们就停止训练。
early_stop = keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=30)
让我们打印一个模型的摘要,这样我们就可以将它与修剪好的模型摘要进行比较。
model = setup_model()model.summary()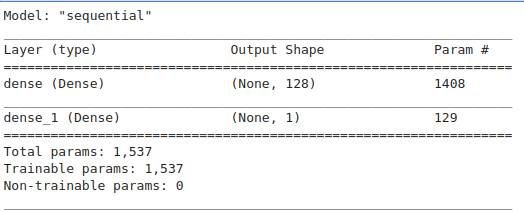
让我们编译这个模型并对其进行训练。
model.compile(optimizer=’adam’, loss=tf.keras.losses.mean_squared_error, metrics=[‘mae’, ‘mse’])model.fit(X_train,y_train,epochs=300,validation_split=0.2,callbacks=early_stop,verbose=0)
由于这是一个回归问题,我们会监控平均绝对误差和均方差。
下面是绘制成图像的模型,输入为10,因为我们生成的数据集有10个特征。
tf.keras.utils.plot_model( model, to_file=”model.png”, show_shapes=True, show_layer_names=True, rankdir=”TB”, expand_nested=True, dpi=96,)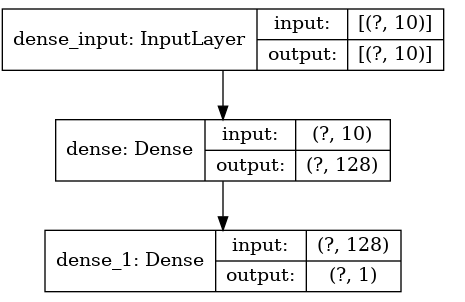
现在让我们来看看均方差。我们可以进入下一节,看看当我们修剪整个模型时这个均方差是如何改变的。
from sklearn.metrics import mean_squared_errorpredictions = model.predict(X_test)print(‘Without Pruning MSE %.4f’ % mean_squared_error(y_test,predictions.reshape(3300,)))Without Pruning MSE 0.0201
用恒稀疏度修剪策略(ConstantSparsity Pruning Schedule)剪枝整个模型
让我们比较上面的 MSE 和剪枝整个模型后得到的 MSE。第一步是定义剪枝参数。权重剪枝是基于数量级(magnitude-based)的。这意味着一些权重在训练过程中被转换为零。模型变得稀疏,因此更容易压缩。稀疏模型也使推断更快,因为零可以跳过。
预定的参数是剪枝策略、块大小和池块类型。
在这种情况下,我们设定了50%的稀疏度, 这意味着50% 的权重将被归零
block_size— 块矩阵权重张量稀疏模式的维度(高度、重量)block_pooling_type— 用来池化块权重的函数,必须是AVG或MAX
from tensorflow_model_optimization.sparsity.keras import ConstantSparsitypruning_params = { 'pruning_schedule': ConstantSparsity(0.5, 0), 'block_size': (1, 1), 'block_pooling_type': 'AVG'}现在我们可以通过应用剪枝参数来修剪整个模型。
from tensorflow_model_optimization.sparsity.keras import prune_low_magnitudemodel_to_prune = prune_low_magnitude( keras.Sequential([ tf.keras.layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],)), tf.keras.layers.Dense(1, activation='relu') ]), **pruning_params)
让我们检查模型摘要。将其与未修剪模型的摘要进行比较。从下面的图片我们可以看到整个模型已经被剪枝了——我们很快就会看到在修剪一个稠密层之后得到的摘要中的差异。
model_to_prune.summary()
我们必须先编译这个模型,然后才能使它适合于训练和测试集。
model_to_prune.compile(optimizer=’adam’, loss=tf.keras.losses.mean_squared_error, metrics=[‘mae’, ‘mse’])
由于我们应用了剪枝,除了早期停止callback之外,我们还必须定义两个剪枝callbacks。我们选定记录模型的文件夹,然后用回调函数创建一个列表。
tfmot.sparsity.keras.UpdatePruningStep() 使用优化器步骤更新剪枝wrappers。不设定的话会报错。
tfmot.sparsity.keras.PruningSummaries() 向 Tensorboard 添加剪枝摘要。
log_dir = ‘.models’callbacks = [ tfmot.sparsity.keras.UpdatePruningStep(), # Log sparsity and other metrics in Tensorboard. tfmot.sparsity.keras.PruningSummaries(log_dir=log_dir), keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=10)]
有了这种方式,我们现在可以fit模型的训练集了。
model_to_prune.fit(X_train,y_train,epochs=100,validation_split=0.2,callbacks=callbacks,verbose=0)
在检查这个模型的均方差时,我们注意到它略高于未剪枝模型。
prune_predictions = model_to_prune.predict(X_test)print(‘Whole Model Pruned MSE %.4f’ % mean_squared_error(y_test,prune_predictions.reshape(3300,)))Whole Model Pruned MSE 0.1830
用多项式衰减剪枝策略(PolynomialDecay Pruning Schedule)只剪稠密层
现在我们实现相同的模型ー但是这一次,我们只剪稠密层。请注意,在剪枝调度中使用了 PolynomialDecay函数。
from tensorflow_model_optimization.sparsity.keras import PolynomialDecaylayer_pruning_params = { 'pruning_schedule': PolynomialDecay(initial_sparsity=0.2, final_sparsity=0.8, begin_step=1000, end_step=2000), 'block_size': (2, 3), 'block_pooling_type': 'MAX'}model_layer_prunning = keras.Sequential([ prune_low_magnitude(tf.keras.layers.Dense(128, activation='relu',input_shape=(X_train.shape[1],)), **layer_pruning_params), tf.keras.layers.Dense(1, activation='relu')])
从总结中我们可以看到,只有第一层稠密层会被修剪。
model_layer_prunning.summary()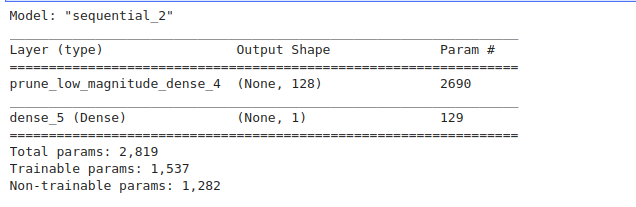
然后我们编译并fit模型。
model_layer_prunning.compile(optimizer=’adam’, loss=tf.keras.losses.mean_squared_error, metrics=[‘mae’, ‘mse’])model_layer_prunning.fit(X_train,y_train,epochs=300,validation_split=0.1,callbacks=callbacks,verbose=0)
现在,让我们检查一下均方差。
layer_prune_predictions = model_layer_prunning.predict(X_test)print(‘Layer Prunned MSE %.4f’ % mean_squared_error(y_test,layer_prune_predictions.reshape(3300,)))Layer Prunned MSE 0.1388
由于我们使用了不同的剪枝参数,所以不能将这里获得的 MSE 与前一个进行比较。如果你想比较它们,那么请确保剪枝参数是相似的。经过测试,对于这个特定的情况,layer_pruning_params比pruning_params 的误差要小。比较从不同剪枝参数得到的 MSE 是有意义的,这样你可以保证模型性能不会更差。
比较模型大小
现在让我们比较有剪枝和没有剪枝的模型的大小。我们开始训练并保存模型的权重以便以后使用。
def train_save_weights(): model = setup_model() model.compile(optimizer='adam', loss=tf.keras.losses.mean_squared_error, metrics=['mae', 'mse']) model.fit(X_train,y_train,epochs=300,validation_split=0.2,callbacks=callbacks,verbose=0) model.save_weights('.models/friedman_model_weights.h5')train_save_weights()
我们将建立基准模型并加载保存的权重。然后修剪整个模型。我们编译,拟合模型,并在 Tensorboard上可视化结果。
base_model = setup_model()base_model.load_weights('.models/friedman_model_weights.h5') # optional but recommended for model accuracymodel_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(base_model)model_for_pruning.compile( loss=tf.keras.losses.mean_squared_error, optimizer='adam', metrics=['mae', 'mse'])model_for_pruning.fit( X_train, y_train, callbacks=callbacks, epochs=300, validation_split = 0.2, verbose=0)%tensorboard --logdir={log_dir}
下面是 TensorBoard 剪枝摘要的一个快照。
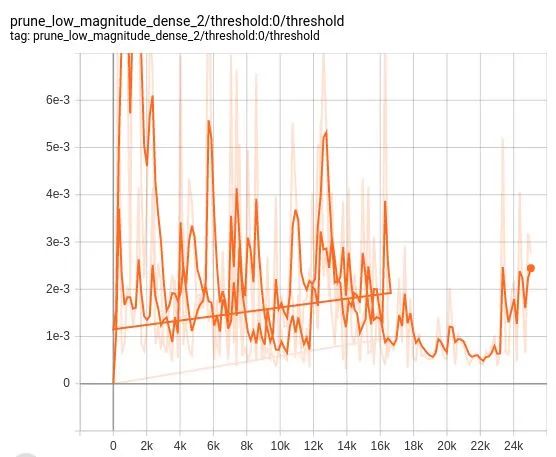
其他剪枝摘要也可以在 Tensorboard 上查看。
现在让我们定义一个函数来计算模型的大小。
def get_gzipped_model_size(model,mode_name,zip_name): # Returns size of gzipped model, in bytes. model.save(mode_name, include_optimizer=False) with zipfile.ZipFile(zip_name, 'w', compression=zipfile.ZIP_DEFLATED) as f: f.write(mode_name) return os.path.getsize(zip_name)
现在我们定义导出模型,然后计算大小。
对于修剪过的模型,使用tfmot.sparsity.keras.strip_pruning() 结合稀疏权重恢复原始模型。请注意已剪和未剪模型在尺寸上的差异。
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)print("Size of gzipped pruned model without stripping: %.2f bytes" % (get_gzipped_model_size(model_for_pruning,'.models/model_for_pruning.h5','.models/model_for_pruning.zip')))print("Size of gzipped pruned model with stripping: %.2f bytes" % (get_gzipped_model_size(model_for_export,'.models/model_for_export.h5','.models/model_for_export.zip')))Size of gzipped pruned model without stripping: 6101.00 bytesSize of gzipped pruned model with stripping: 5140.00 bytes
通过运行这两个模型的预测,我们发现它们有相同的均方差。
model_for_prunning_predictions = model_for_pruning.predict(X_test)print('Model for Prunning Error %.4f' % mean_squared_error(y_test,model_for_prunning_predictions.reshape(3300,)))model_for_export_predictions = model_for_export.predict(X_test)print('Model for Export Error %.4f' % mean_squared_error(y_test,model_for_export_predictions.reshape(3300,)))Model for Prunning Error 0.0264Model for Export Error 0.0264
最后的想法
你可以继续测试不同的剪枝策略如何影响模型的大小。显然,这里的观察结果并不是通用的。你必须尝试不同的剪枝参数,并了解根据你的问题它们如何影响模型大小、预测误差和/或准确率。
为了进一步优化模型,你还可以量化它。如果你想了解更多,请查看下面的代码库和资源。
Resources:
Pruning in Keras example | TensorFlow Model Optimization
https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras
Pruning comprehensive guide | TensorFlow Model Optimization
https://www.tensorflow.org/model_optimization/guide/pruning/comprehensive_guide
mwitiderrick/Pruning-in-TensorFlow
mwitiderrick/Pruning-in-TensorFlowmwitiderrick/Pruning-in-TensorFlow
8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision
https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd
原文:https://heartbeat.fritz.ai/model-pruning-in-tensorflow-e4e8f5646f6f