义乌外贸网站开发/如何制作网页游戏
一、为什么用自增列作为主键
1.如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引。
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
如果也没有这样的唯一索引, 则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2.数据记录本身被存于主索引(一颗B+Tree)的叶子节点上,这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放
因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16), 则开辟一个新的页(节点)
3.如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前引节点的后续位置,当一页写满,就会自动开辟-个新的页
4.如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置
二、为什么使用数据索引能提高效率
■数据索引的存储是 有序的
■在有序的情况下, 通过索引查询一个数据是无需遍历索引记录的
■极端情况下,数据索引的查询效率为二分法查询效率,趋近于log2(N)
三、B+树索引和哈希索引的区别
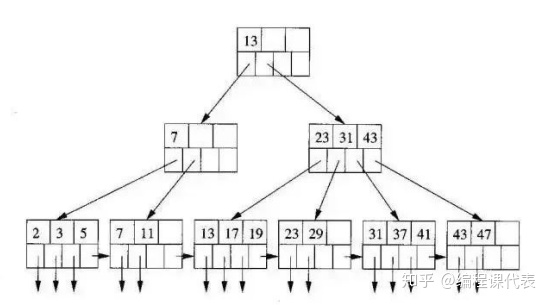
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接,是有序的,如下图:
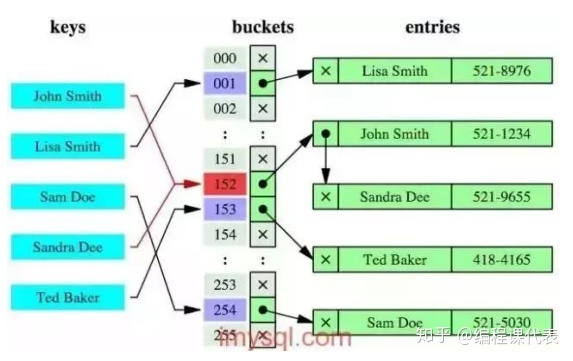
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的,如下图所示:
四、哈希索引的优势:
等值查询,哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
五、哈希索引不适用的场景:
■不支持 范围查询
■不支持索引完成排序
■不支持联合索引的最左前缀匹配规则
六、为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?
1. B+的磁盘读写代价更低。
B+的内部结点并没有指向关键字具体信息的指针,因此其内部结点相对B树更小
如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说I0读写次数也就降低了。
2. B+-tree的 询效率更加稳定。
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
七、MySQL联合索引
1、联合索引是两个或更多个列上的索引。
对于联合索引:Mysq从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。
2.利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。
八、什么情况下应不建或少建索引
1.表记录太少
2.经常插入、删除修改的表
3.数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
4.经常和主字段一块询但主字段索引值比较多的表字段
九、什么是表分区?
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
十、表分区与分表的区别
分表:指的是通过一定规则, 将一张表分解成多 张不同的表。比如将用户订单记录根据时间成多个表。
分表与分区的区别在于:分区从逻辑上来讲只有一张表 ,而分表则是将一张表分解成多张表。
十一、表分区有什么好处?
1、存储更多数据。分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。和单个磁盘或者文件系统相比,可以存储更多数据
2.优化E询。在where语句中包含分区条件时,可以只扫描一个或多 个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
3.分区表更容易维护。例如:想批量删除大量数据可以清除整个分区。
4.避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问, ext3问价你系统的inode锁竞争等。
十二、分区表的限制因素
1.一个表最多只能有1024个分区
2、MySQL5.1中, 分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中提供 了非整数表达式分区的支持。
3、如果分区字段中有主键或者唯一索引的列, 那么多有主键列和唯一索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
4、分区表中无法使用外键约束
5. MySQL的分区适用于一个表的所有数据和索引,不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表分区,也不能只对表的一部分数据分区。
十三、MySQL支持的分区类型有哪些?
RANGE分区:这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区
LIST分区:这种模式允许系统通过预定义的列表的值来对数据进行分割。按照List中的值分区,与RANGE的区别是, range分区的区间范围值是连续的。
HASH分区:这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
KEY分区:上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
十四、四种隔离级别
■Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
■Repeatable read (可重复读):可避免脏读、不可重复读的发生。
■Read committed (读已提交):可避免脏读的发生。
■Read uncommitted (读未提交):最低级别,任何情况都无法保证。
十五、在MVCC并发控制中,读操作可以分成两类:
快照读(snapshot read):读取的是记录的可见版本(有可能是历史版本),不用加锁(共享读锁s锁也不加,所以不会阻塞其他事务的写)
当前读(currentread):读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录
十六、行级锁定的优点:
1、当在许多线程中访问不同的行时只存在少量锁定冲突。
2、回滚时只有少量的更改
3、可以长时间锁定单一的行。