域名建设网站/淘宝怎么推广自己的产品

上一篇内容讲到的fs文件系统模块是官方提供的内置模块,本篇path路径模块也是Node.js官方提供的内置模块,也是核心模块,用来处理路径,path模块用来满足用户对路径的处理需求。在上一篇内容就涉及到路径拼接的问题,来一个简单的例子:
// 相对路径
fs.readFile('./read.txt'...)
// 完整路径
fs.readFile('C:\Users\Administrator\Desktop\Node\fs模块/read.txt'...)
// __dirname 处理
fs.readFile(__dirname + '/read.txt'...)引入path模块
const path = require('path');在path路径模块内容中对路径拼接的方法,虽然可以通过 "+" 来进行拼接,但在path路径模块中有对应的路径拼接方法;
path.join() —— 路径拼接
路径拼接,path.join([...paths]),...paths <string> 一个路径片段序列;返回值是<string>
// join.js文件
const path = require('path');
const rs_1 = path.join('/Node','/path');
console.log(rs_1);
const rs_2 = path.join('/Node','/path','..','/join');
console.log(rs_2);

// join.js文件
const path = require('path');
const rs_1 = path.join(__dirname , '/Node' ,'/path');
console.log(rs_1);
const rs_2 = path.join(__dirname , '/Node/read.txt' );
console.log(rs_2);

fs.readFile() 和 path.join()
通过path.join()拼接路径,使用fs.readFile()读取;
// read.txt
path路径内容// read_join.js
const fs = require('fs');
const path = require('path');
fs.readFile(path.join(__dirname,'/read.txt'),'utf8',function(err,dataStr){console.log(path.join(__dirname,'/read.txt'));if(err){return console.log("读取失败!")}console.log("读取成功:",dataStr);
})
通过使用path.join()路径拼接的使用,在之后的进行路径的拼接过程都要使用path.join()方法来处理路径的拼接,不再使用 "+" 进行拼接;
path.basename 获取路径中的文件名称
path.basename(path[,ext]),ext是文件拓展名(后缀),使用path.basename可以获取path的最后一部分,一般都是文件名称;
// basename.js文件
const path = require('path');
const pName = '/Node/path/index.html';
const rs = path.basename(pName);
console.log(rs);
// 修改basename.js文件
const rs = path.basename(pName,'.html'); // 移除拓展名
console.log(rs);
path.extname() 获取路径中的文件拓展名
获取路径中的文件拓展名可以通过path.extname(path)来获取,如下:
// extname.js文件
const path = require('path');
const pName = '/Node/path/index.html';
const rs = path.extname(pName);
console.log(rs);
path.parse() 和 path.format()
path.parse() 可以获取一个路径对象,而path.format() 可以将路径对象转为一个路径;
// parse_format.js
const path = require('path');
const rs = path.parse(__dirname);
console.log(rs);
const obj = {root: 'C:\\',dir: 'C:\\Users\\Administrator\\Desktop\\node\\Node',base: 'path模块',ext: '',name: 'path模块'};
const re_s = path.format(obj);
console.log(re_s);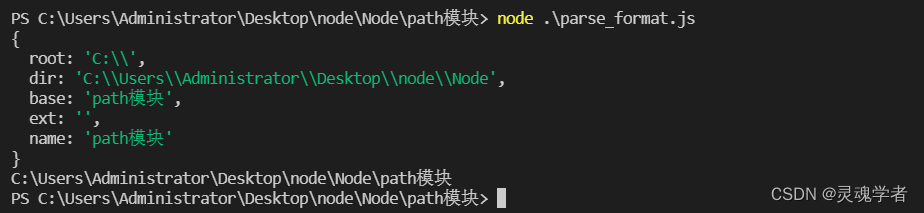
path.isAbsolute() 是否为绝对路径
通过path.isAbsolute(path)来判断一个路径是否为绝对路径;若path的路径长度为0,则返回false值;
// isAbsolute.js文件
const path = require('path');
const rs = path.isAbsolute(__dirname);
console.log(rs);![]()
path.resolve()
path.resolve([...path]),将[...path]解析为绝对路径,可以是完整路径或路径片段;路径处理的序列是从右往左的处理解析的,直到能构造成一个完成绝对路径;
const path = require('path');
const rs_1 = path.resolve('/sd','/s'); // C:\s
const rs_2 = path.resolve('/sd','s'); // C:\sd\s
const rs_3 = path.resolve('sd','/s'); // C:\s
const rs_4 = path.resolve('/sd','/s','/d'); // C:\d
const rs_5 = path.resolve('sd','/s','/d'); // C:\d
const rs_6 = path.resolve('sd','s','/d'); // C:\d
const rs_7 = path.resolve('sd','/s','d'); // C:\s\d
const rs_8 = path.resolve('/sd','s','d'); // C:\sd\s\d引入url模块
url模块也是Node.js中的核心模块内容,在一些GET请求当中会见到在请求url当中会携带一些属性和值,在应用过程中会涉及到需要从完整的url请求的路径中提出各个属性以及值的各种问题,通过Node.js中url模块就能够来解决这类问题!
// 引入url模块
const url = require('url');url.parse() —— 对象
url.parse(urlString[,parseQueryString,slashesDenoteHost]),使用该方法可以将一个字符串形式的url(urlString) 转为对象形式的url,parseQueryString为true时将使用查询模块分析字符串,slashesDenoteHost为false时 '//Node/node' 会解析为 '{pathname:'//Node/node'}',设为true时则解析为:{ host:'/Node' ,pathname:'/node' };
const url = require('url');
const net = 'http://localhost:8080/api/picture?page=1&id=1001';
console.log(url.parse(net,false,false));
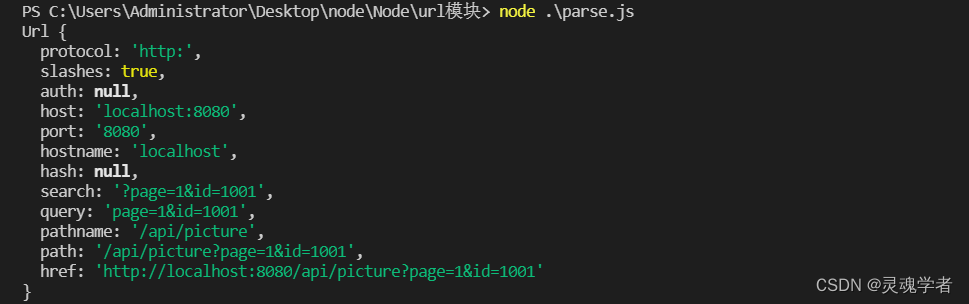
url.format() —— 字符串
url.format()与url.parse()相反,可以将一个url对象进行转为url字符串;
const url = require('url');
const netObj = {protocol: 'http:',slashes: true,auth: null,host: 'localhost:8080',port: '8080',hostname: 'localhost',hash: null,search: '?page=1&id=1001',query: 'page=1&id=1001',pathname: '/api/picture',path: '/api/picture?page=1&id=1001',href: 'http://localhost:8080/api/picture?page=1&id=1001'
}
console.log(url.format(netObj));![]()
url.resolve(from,to)
from 表示源地址,to 表示需要添加或替换;
const url = require('url');
const u_1 = url.resolve('/Node/node','url');
console.log(u_1);
const u_2 = url.resolve('/Node/node','/url');
console.log(u_2);
以上内容记录的就是在Node.js中path模块和url模块需要掌握的内容!感谢大家的支持!
