建立网站ftp是什么/百度网盘服务电话6988
一,参照完整性的多对多关系的表格创建
例如:老师和学生是多对多关系, 一个老师对应多个学生,一个学生被多个老师教。
多对多关系中 需要创建三个表 其中有一个是关系表。
首先创建学生表:
Create table students(id int,name varchar(100),grade varchar(100),primary key(id));
其次创建老师表:
Create table teachers(id int,name varchar(100)salary float(8,2),primary key(id)
);
最后创建师生:
`
Create table teacher_student(t_id int,s_id int,
CONSTRAINT teacher_id_fk FOREIGN KEY(t_id) REFERENCES teachers(id),
CONSTRAINT student_id_fk FOREIGN KEY(s_id) REFERENCES students(id)
);
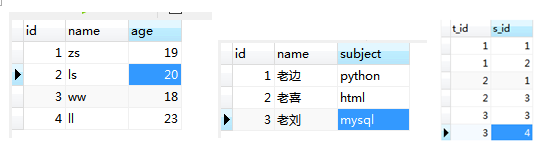
建成之后的表格如图。
即现在学生表和老师表中创建主键,然后在关系表中将俩个表的主键设为外键,并以主键为参照进行对应。
一对一关系比较简单,若用外键关联 则添加唯一约束,若用主键关联。则添加外键约束。
二,多表查询
使用单个select 语句从多个表格中取出相关的查询结果,多表连接通常是建立在有相互关系的父子表上;
1,交叉连接
第一个表格的所有行 乘以 第二个表格中的所有行,也就是笛卡尔积。
语法:
隐式语法(不使用关键字): select * from 表a,表b;
显式语法(使用关键字): select * from 表a CROSS JOIN 表b;
这种查询方式基本不会使用,因为其本身得到的结果集就是不正确的。
2,内连接
因为交叉连接获得的结果集是错误的。因此内连接是在交叉连接的基础上只列出连接表中与连接条件相匹配的数据行,匹配不上的记录不会被列出。内连接查询,可以有效的去除笛卡尔集现象。
语法:
隐式语法:
select * from 表A,表B where 条件;
使用别名:select * from A 别名1,B 别名2 where 别名1.xx=别名2.xx;
显式语法:
select * from 表A INNER JOIN 表B ON 条件;
使用别名:select * from A 别名1 inner join B 别名2 on 别名1.xx=别名2.xx;
内连接只列出所有购买过商品的用户的信息,不会列出没有购买商品用户。
3,外连接
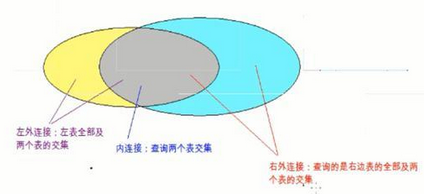
外链接是以一张表为基表,其他表信息进行拼接,如果有就拼接上,如果没有显示null; 外链接分为左外连接和右下连接。
左外连接: 以关键字左边的表格为基表进行拼接。
语法:select * from A left outer join B on条件
右外连接: 以关键字右边的表格为基表
语法:select * from A right out join B on 条件
左外连接就是左边的表的内容全部显示,然后匹配右边的表,如果右边的表匹配不到,则空。
右外连接就是右边的表的内容全部显示,然后匹配左边的表,如果左边的表匹配不到,则空。
总结:
内连接就是两个表的交集
左外连接就是左边表加两表交集
右外连接就是右边表加两表交集
4,子查询
某些情况下,当进行查询的时候,需要的条件是另外一个select语句的结果,这个时候就会用到子查询,为了给主查询(外部查询) 提供数据而首先执行的查询(内部查询)被叫做子查询; 子查询分为嵌套子查询和相关子查询。
子查询出现在where后是作为条件出现的
子查询出现在from之后是作为表存在的
例如:查询出id为1的老师教过的所有学生。
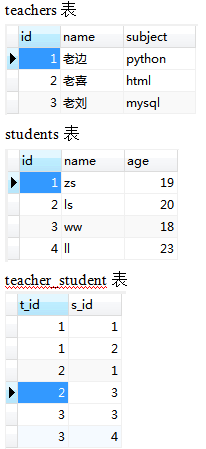
查询结果:
select s_id from teacher_student where t_id=1;
select * from students where id in(1,2);
嵌套子查询:
内部查询的执行独立于外部查询,内部查询仅执行一次,执行完毕后将结果作为外部查询的条件使用(嵌套子查询中的子查询语句可以拿出来单独运行。)
则上面的例子用嵌套子查询的结果为:select * from students where id in(select s_id from teacher_student where t_id=1);
相关子查询:
内部查询的执行依赖于外部查询的数据,外部查询每执行一次,内部查询也会执行一次。每一次都是外部查询先执行,取出外部查询表中的一个元组,将当前元组中的数据传递给内部查询,然后执行内部查询。根据内部查询执行的结果,判断当前元组是否满足外部查询中的where条件,若满足则当前元组是符合要求的记录,否则不符合要求。然后,外部查询继续取出下一个元组数据,执行上述的操作,直到全部元组均被处理完毕。
例如:
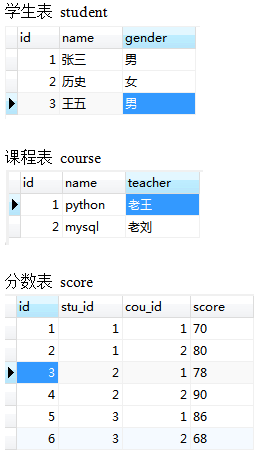
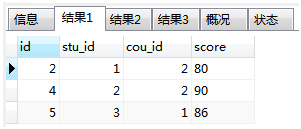
求:每一科考试成绩大于平均分的学生的分数。
查询结果:select * from score as a where a.score>(select avg(b.score) from score as b where a.cou_id=b.cou_id);
聚合函数
1.count() :求满足列条件的总的行数。
例如:统计数学成绩大于90的学生有多少个?
SELECT COUNT(*) FROM student WHERE math>90;
注意: 除了COUNT( * )以外,其他字段都会忽略NULL值;
2,sum()求和
例如:统计一个班级语文、英语、数学的成绩总和
SELECT SUM(chinese+english+math) FROM student;
3,avg(): 求平均数。
例如:求数学平均分
SELECT AVG(math) FROM student;
4,min() 和 max() 求最大值和最小值。
例如:求班级数学最高分和最低分
select max(math),min(math) from student;
5,group by分组
group by子句的真正作用在于与各种聚合函数配合使用。它用来对查询出来的数据进行分组。
分组的含义是:把该列具有相同值的多条记录当成一组记录处理,最后只输出一条记录。分组函数忽略空值。
例如:
1.对订单表中商品归类后,显示每一类商品的总价
SELECT product,SUM(price) FROM t_order GROUP BY product;
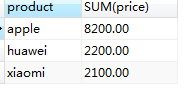
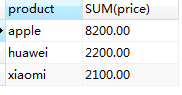
2.查询商品总价格大于3000的商品
SELECT product,SUM(price) FROM t_order GROUP BY product HAVING SUM(price)>100;
注意:
(1)、分组函数的重要规则
如果使用了分组函数,或者使用GROUP BY 的查询:出现在SELECT列表中的字段,要么出现在聚合函数里,要么出现在GROUP BY 子句中。
(上面的product出现在了group by中,price出现在了聚合函数中)
GROUP BY 子句的字段可以不出现在SELECT列表当中。
(2)、having where 的区别
①、where和having都是用来做条件限定的,
②、WHERE是在分组(group by)前进行条件过滤,
③、HAVING子句是在分组(group by)后进行条件过滤,
④、WHERE子句中不能使用聚合函数,HAVING子句可以使用聚合函数。
⑤、HAVING子句用来对分组后的结果再进行条件过滤。