百度推广交了钱不给做网站/产品线上营销方案
单向链表:
在前几讲中,我们对动态数组进行了讲解,在讲解链表之前我觉得还是需要清楚的知道动态数组和链表之间的区别和联系,为之后对链表的操作打好基础。
首先,动态数组是在堆区开发的一个连续可拓展的内存区域,链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。至于链表内部的组成结构我们后面再进行讲解。所以这里有必要先对这两者之间进行优点和缺点的比较。
动态数组的优点:
- 无需为线性表中的逻辑关系增加额外的空间。
- 可以快速的获取表中合法位置的元素。
动态数组的缺点:
- 插入和删除操作需要移动大量元素。
单向链表的优点:
- 无需一次性定制链表的容量
- 插入和删除操作无需移动数据元素
单向链表的缺点:
- 数据元素必须保存后继元素的位置信息
- 获取指定数据的元素操作需要顺序访问之前的元素
我们从上面论述中得知,动态数组最大的缺点是插入和删除时需要移动大量的元素,这显然很耗费时间,所以此时链表的作用就体现出来了。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
为了让大家更好的了解节点的构成,特意画了一张图供大家观看:

上述图为单个节点的结构组成,众所周知,链表可以由很多个节点组成,但是我们需要知道每个链表都会有一个头节点,用于指向第一个数据元素的指针以及链表自身的一些信息。有头节点,那自然而然就会有尾节点,只不过其中的指针域指向的是NULL,即为空,表示没有可以指向的下一节点。
链表初始化:
先上代码:
struct LinkNode
{void* data;struct LinkNode* next;
}struct LList
{struct LinkNode pHeader;int m_Size;
}typedef void * LinkList;LinkList init_LinkList()
{struct LList * mylist = malloc(sizeof(struct LList));if(mylist == NULL){return;}mylist->pHeader.data = -1;mylist->pHeader.next = NULL;mylist->m_Size = 0;return mylist;}
我们还是按照老样子,逐句分析:
为了让大家更好的了解链表的构成,特意画了一张图供大家观看:
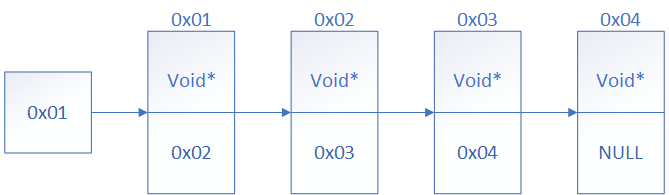
由上图可知:
- 该链表的头节点指针域是
0x01,即指向了第一个节点。 - 每个节点的数据域我们从图中可以看到数据类型都是
void *类型,这其实与我们当时设计动态数组时的原理一样,由于我们现在是在设计算法,所以我们是不知道用户最终传入该算法的入口参数数据类型是什么类型的,可能是int,char,float等等,所以我们这时候为了适应各种数据类型,使用了万能指针void *。 - 该链表的尾节点指针域是
NULL,代表空。
链表的初始化分为两个部分,一个部分是对单个节点的初始化,另一个部分是对整个链表的初始化。
对单个节点的初始化:
代码如下:
struct LinkNode
{void* data;struct LinkNode* next;
}
首先我们创建了一个结构体,结构体名字显而易见LinkNode为单个节点。
两个成员变量:我们都知道单个节点是由两部分组成的,一个是数据域(数据类型为void *),另一个是指针域(指向下一个节点)。
对整个链表的初始化:
代码如下:
struct LList
{struct LinkNode pHeader;int m_size;
}
首先我们创建了一个结构体,结构体名字显而易见LList为整个链表。
两个成员变量:我们都知道链表中缺一不可的一个组成部分是头节点,用于指向第一个节点,我们这里调用的是pHeader。并且我们在对其初始化时,需要得整个链表的长度,即该链表中有多少个节点供我们进行访问。
typedef void * LinkList;
比如在前几讲中所讲的动态数组中提到过,举个例子,我们修改动态数组的容量,可以通过arr->m_Capacity来成功访问arr数组中的成员变量,并且我们作为用户可以随意更改,意味着我们是该用户变量的维护者,但是从另一个角度来看,这其实是不合理的,我们可以进行非法操作,比如arr->m_Capacity = -1,这是不合理的,所以我们不能让用户拿到结构体中的数据,只需要使得用户拿到的数据类型没办法得知结构体里的真实的数据类型,即void * 类型,但是我们为了软件的美观,需要使用typedef将void *重定义为LinkList。此时用户就没办法修改真实结构体中的成员变量,我们最终只需要在功能函数中将void * LinkList指向LList即可。
LinkList init_LinkList()
{struct LList * mylist = malloc(sizeof(struct LList));if(mylist == NULL){return;}mylist->pHeader.data = -1;mylist->pHeader.next = NULL;mylist->m_Size = 0;return mylist;}
首先我们需要创建一个指针用于指向该链表,同时需要和动态数组中一样,在堆区中申请内存空间。同理,为了算法的严谨性,需要对申请完的内存空间进行校验,如果校验成功,则会继续运行,如果没有校验成功,则会提前退出该函数。然后申请完内存空间后,成功能够通过mylist 访问LList中的成员变量,需要对其成员变量进行初始化配置。并且最终返回该指针变量mylist。
链表插入:
先上代码:
void insert_LinkList(LinkList list, int pos,void * data)
{if(list == NULL){return;}if(data == NULL){return;}struct LList * mylist = list;if(pos<0||pos>mylist->m_Size){pos = mylist->m_Size;}struct LinkNode * pCurrent = &mylist->pHeader;for(int i=0;i<pos;i++){pCurrent = pCurrent->next;}struct LinkNode *newNode = malloc(sizeof(struct LinkNode));newNode->data = data;newNode->next = NULL;newNode->next = pCurrent->next;pCurrent->next = newNode;mylist->m_Size++;}
我们还是按照老样子,逐句分析:
void insert_LinkList(LinkList list, int pos,void * data)
首先先对该函数的入口参数进行讲解:
LinkList list:被插入链表。int pos:插入当前链表的位置。void * data:新节点的数据域的值。
if(list == NULL)
{return;
}
if(data == NULL)
{return;
}
同理,为了算法的严谨性,需要对函数的入口参数进行校验,如果校验成功,则会继续运行,如果没有校验成功,则会提前退出该函数。
struct LList * mylist = list;
if(pos<0||pos>mylist->m_Size)
{pos = mylist->m_Size;
}
众所周知,当直接使用list->m_Size是无法通过list访问LList的成员变量的,因为声明list的类型为LinkList ,即void * 。所以我们需要重新创建一个指针mylist 可以访问LList 的成员。
那我们有没有考虑过一种情况,即如果插入链表中的位置小于0或者大于该链表的节点长度值,即mylist->m_Size。因为我们都知道链表中的节点是从0开始计数的,即最后一个节点的位置为mylist->m_Size - 1。当符合上述判断条件,我们一般会和动态数组同样的处理方式,即自动将该插入位置后移到最后一个节点位置后一位,即mylist->m_Size。
struct LinkNode * pCurrent = &mylist->pHeader;for(int i=0;i<pos;i++)
{pCurrent = pCurrent->next;
}
为了让大家更好的了解,特意画了一张图供大家观看:

那此时我们想要往该链表插入一个新节点时,我们可以这样想,比如我们想要插入的位置为2,那么由于链表具有指向性,我们需要找到待插入位置的前驱节点位置。那么我们需要找到位置为1的节点。我们一般会使用for循环来对链表进行遍历操作。众所周知,链表都是从0开始进行计数的,即我们需要创建一个指针用来指向该链表的头节点。然后此时使用for循环,从上述代码可以看出,for循环会进行两次,即pos会从0,1。即pCurrent 正好指向的就是位置为1的节点,即成功找到了待插入位置的前驱节点位置。
struct LinkNode *newNode = malloc(sizeof(struct LinkNode));newNode->data = data;
newNode->next = NULL;newNode->next = pCurrent->next;
pCurrent->next = newNode;
在找到了待插入位置的前驱节点位置的情况下,我们就可以开始进行插入新节点操作了。但是首先我们需要创建一个指针用于指向新节点。同时通过该函数的入口参数data对newNode->data进行赋值,并且这里是初始化操作,所以我们暂时先将指针域指向NULL,后面会重新进行赋值。
我们可以想一想,如果我们插入的位置为2,则原链表中的位置为2的节点要变成3,其余的以此类推。同时由于链表是具有指向性,所以我们需要将指针域重新进行指向。即新节点的指针域指向原位置为2(现位置为3)的节点,同时位置为1的节点指针域指向新节点。
mylist->m_Size++;
在添加完新节点后,要对该链表的长度进行更新。
链表遍历:
先上代码:
void foreach_LinkList(LinkList list,void (*myPrint)(void *))
{if(list == NULL){return;}struct LList *mylist = list;struct LinkNode *pCurrent = mylist->pHeader.next;for(int i = 0;i<mylist->m_Size;i++){myPrint(pCurrent->data);pCurrent = pCurrent->next;}
}
我们还是按照老样子,逐句分析:
if(list == NULL)
{return;
}
同理,为了算法的严谨性,需要对函数的入口参数进行校验,如果校验成功,则会继续运行,如果没有校验成功,则会提前退出该函数。
struct LList *mylist = list;
struct LinkNode *pCurrent = mylist->pHeader.next;
我们需要创建一个指针mylist 能够成功访问LList 中的成员变量。同时我们需要通过一个指针pCurrent 指向该链表的头节点。
for(int i = 0;i<mylist->m_Size;i++)
{myPrint(pCurrent->data);pCurrent = pCurrent->next;
}
进行遍历实则是在为了测试过程中可以用来校验该算法是否正确和合理。所以一般我们进行遍历时,会将链表中数据域中的数据挨个打印。
结束语
如果觉得这篇文章还不错的话,记得点赞 ,支持下!!!