淮北网站开发公司/东莞seo优化排名推广

本文是我读《Person Re-identification: Past, Present and Future》论文的笔记和理解,因为之前尝试直接读别人的论文解读,但是读了很久仍然觉得不甚理解。索性拿来原论文通读(只读了 image-based 的部分),这才稍微有了点感觉。
*** 下列内容如果有错误的地方,欢迎各位朋友批评指正,与我交流。***
1、Introduction
person detection, person tracking, and person retrieval
the most challenging problem in re-ID is how to correctly match two images of the same person 匹配同一个人的不同图片
发展历史:
Multi-camera tracking
Multi-camera tracking with explicit “re-identification
The independence of re-ID (image-based)
Video-based re-ID
Deep learning for re-ID(2014 Krizhevsky 引起风潮):采用 siamese model(因为数据集里面一般同一个人(同一ID)只有两张图片),同时把人体部位分区,增加一个损失函数。不足:在小数据集上表现不稳定。
End-to-end image-based re-ID:detector(hand-cropped 或者自动检测器) + retrieval 共同考虑,可以提高准确率
Re-ID 和 classification 和 retrieval 的对比:

关键:
Training 阶段:学习 discriminative distance metrics
Retrieval 阶段:通过 高效的索引结构+哈希技巧 来助攻 re-ID in a large gallery
2、Image-based Person Re-ID
2.1 hand-crafted ReID
query 的id由下述公式决定:
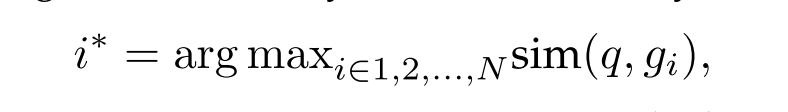
关键:
Pedestrian description and distance metrics.
一、Pedestrain description
Low level 的特征:
color最常用,texture 用得少一些,基本都是各种在 color 和 texture 上做文章,详见各种论文。基本套路有这些:
聚合方式不同、流程前后步骤差异、增强鲁棒性、其他领域(比如 NLP)的方法运用到图像上来
Mid-level 特征:
attribute-based features(鲁棒性更强)
基本套路:用低级特征去训练出中级特征、无监督学习、借助外部数据进行属性学习。ps:有相应的数据集可以进行属性学习
二、distance metrics
有一个综述可以参考:
L. Yang and R. Jin, “Distance metric learning: A comprehensive survey,” Michigan State Universiy, vol. 2, p. 78, 2006.
在各种各样的 metric learning 的方法中,基本归结为
有监督和无监督、全局和局部的,现在 ReID 基本都是有监督的全局的

Global metric learning的核心思想其实就是,让同一类的向量距离尽量贴近,不同类的尽量远离。

基于马氏距离:
基于马氏距离的 KISSME,讲判断一对向量是否相似的问题转化为似然比率测试(likelihood ratio test),Difference space 被假定是一个平均值为0的高斯分布。PCA用来辅助消除维度关联。
基于nearest neighbor:
large margin nearest neighbor Learning (LMNN) method which sets up a perimeter for the target neighbors (matched pairs) and punishes those invading the perimeter (imposters). (有监督的局部粒度学习),辅助以information-theoretic metric learning (ITML) 避免过拟合。
其他思路:
a. relax the positivity constraint which provides a sufficient approximation for the matrix M with a much lower computational cost. 简单来说,就是用计算复杂度更低的公式来代替半正定矩阵M
b. 在马氏距离的基础上增加其他的相似度的度量,like adding a bilinear similarity
c. global distance metric 结合 local adaptive threshold rule
d. 保留半正定约束,对正、负样本进行加权
e. 考虑图像对之间的差异和共性,并表明不相似对的协方差矩阵可以从相似对的协方差矩阵中推断出来,这使得学习过程可以扩展到大数据集。
在学习Pedestrian description and distance metrics 和之外,还有一些其他的关注点:
Discriminative subspace learning:
比如:regularized PCCA and kernel LFDA,殊途同归,基本都是降维(以不同的方式,在不同阶段)
SVM 和 boosting:
各种拿SVM做文章,比如:
把一系列weak RankSVMs 顺序组装成 strong ranker;
用AdaBoost algorithm选择和组合不同的features 去产生相似度的衡量
2.2 deeply-learned system
自从2012年Krizhevsky赢了ILSVRC的比赛以后,以CNN为基础的深度学习模型也流行起来了,这股风也刮到了ReID。CNN based的最主流的两个模型是第一个,classification and object detection model,第二个,siamese model using image pairs or triplets as input。限制深度学习ReID的一大瓶颈主要就是训练数据的缺少。因为现今的数据集对于每个ID一般提供两张图片,所以siamese model比较流行。
基本套路都是,在plain cnn 的基础上:
a. 加某些层(patch matching layer处理不同的horizontal stripes的卷积输出);
b. 通过计算交叉输入邻域差异特征(将来自一个输入图像的特征与另一个图像的相邻位置中的特征进行比较)来改善siamese model;
c. 不同于a(用product计算同一纬度的patch similarity),使用subtraction
d. 使用更小的filter来加深网络(很老套的做法)
e. 活用LSTM
f. testing的时候,在每个conv层后加一个gate捕捉一些effective subtle pattern(效果好,但是费时)
g. 跟 f 相似,有人提出引入注意力模型的机制,以focus在输入图像对的一些局部特征上,但是此方法也受限于计算效率
h. 使用triplet loss(输入为3张图片,而不是2张)
i. Attributes triplet loss有监督的学习结合外源数据集的属性学习
Siamese model的弊端:不能充分利用annotation。
A drawback of the siamese model is that it does not make
full use of re-ID annotations. In fact, the siamese model only needs to consider pairwise (or triplet) labels. Telling whether an image pair is similar (belong to the same identity) or not is a weak label in re-ID.
尝试嵌入classification/identification model也许能解决这个问题,因为 classification model 能够充分利用reid的label。但是,identification loss 对于每个ID需要更多的训练实例以求达到模型收敛。
顺带,解释一下identification和verification的差别:
Identification:1-n
Verification:1-1
以上谈论的都是end-to-end的网络,还有把底层特征作为输入的。(end-to-end是把整张图片作为输入)
比如:
a. 对于每张图片而言,a single Fisher Vector嵌入了SIFT和color histograms这样的底层描述符然后才作为输入,混合网络在此输入的基础上建立全联接层,用LDA作为目标函数,产生低类内方差和高类间方差的embedding。Fisher Vector的解释参考:https://blog.csdn.net/ikerpeng/article/details/41644197
b. 通过底层描述符来限制FC feature
3、ReID算法评估标准
现在基本都用mAP。因为mAP体现了高召回率,同一算法的rank-1 accuracy可能不相上下,但是recall ability更能见高下。在大数据集上(比如CUHK03 and Market-1501),深度学习算法更有优势;在小数据集上(比如VIPeR),hand-crafted则更有优势。鉴于目前的低mAP和数据集相对较小,未来image-based re-ID的进步空间还是非常大的!
video-based re-id 暂不谈论。