网站seo排名优化工具/微信小程序开发公司
本节我将讲述什么是目录遍历以及如何进行目录遍历攻击和如何绕过攻击中的一些障碍。并且会总结出如何防范目录遍历攻击。
什么是目录遍历?
目录遍历(也称文件路径遍历)是一种允许攻击者读取应用服务上任意文件的安全漏洞。这包括应用代码、数据、凭证以及操作系统的敏感文件。在有些情况下,攻击者还可能对服务器里的文件进行任意写入,更改应用数据甚至完全控制服务器。
通过目录遍历读取任意文件
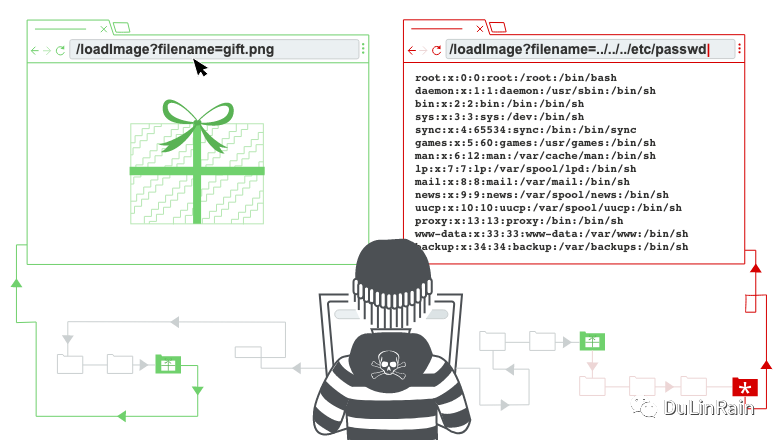
假设有下面这么一个购物网站,里面会展示一张商品图片。这张图片是通过像下面这种方式加载的:
可以看出这实际上是一个接口,该接口接受一个filename的参数,返回对应的文件内容。图片文件本身存储在磁盘下的/var/www/images/目录。为了返回这张图片,服务端将用户提供的文件名和基准目录进行拼接,然后调用文件API进行文件读取。就上面这个case而言,最终会从如下路径读取文件:
/var/www/images/218.png
假设该服务也没对目录遍历攻击做任何防范,那么攻击者可以通过请求下面这个URL来访问服务器文件系统中的任意文件:
https://insecure-website.com/loadImage?filename=../../../etc/passwd
上面这个请求会导致服务器访问下面这个目录下的文件:
/var/www/images/../../../etc/passwd
../ 是一个有效的目录序列,表示当前目录的上一级目录。那么三个../ 会导致从上面的/var/www/images/目录切换到系统根目录下。所以最终实际读取的文件目录会是:
/etc/passwd
在Linux系统里,这是一个标准的目录,包含该服务器的用户信息。
在Windows系统里,../ 和..\ 都是有效的。所以在Windows里一个等效的攻击可能是:
https://insecure-website.com/loadImage?filename=..\..\..\windows\win.ini
目录遍历漏洞利用时的常见障碍
很多服务在将文件名拼接成文件访问路径的过程中会做一些防止目录遍历攻击的工作,但是通常比较容易被绕过。
去除或阻止目录遍历序列
如果应用程序采取的手段是将文件名中的目录遍历序列(../ 和 ..\ )删除或者遇到目录遍历序列就阻止读取文件,那这种可以通过其它手段绕过。
你可能可以直接用绝对路径而不是通过遍历来访问到文件根目录,如
filename=/etc/passwd。你可能可以使用嵌套遍历序列如
....//或....\/来达到同样的效果。因为如果内层的遍历序列被去除后得到的还是个遍历序列。你可能可以使用非标准的编码如
..%c0%af或..%252f来绕过。
限制目录前缀
有的应用可能会通过限制文件文件目录前缀的方式来防范,如限制用户提供的文件路径必须是/var/www/images。但是这样也可以通过在后面拼接遍历序列来完成攻击:
filename=/var/www/images/../../../etc/passwd
限制文件后缀
如果应用限制文件必须是某种扩展名的,如.png。那么可能可以通过使用一个null字节来在文件后缀前终止。例如:
filename=../../../etc/passwd%00.png
如何防范目录遍历攻击
最有效果防范目录遍历的方式就是避免把外部输入提供给文件API,许多做这个事情的API都可以通过其他的形式完成同样的功能需求。
如果这么做(即把外部输入提供给文件API)是不可避免的话,需要同时做2层防护来阻止攻击:
应用在处理用户输入前先对其进行验证,这个验证需要和一个白名单列表做比对。如果这个做不到,那至少需要验证用户输入的是纯字母数字(避免被编码和遍历序列绕过)。
在验证完输入后,应用程序需要将其和基准目录拼接,然后使用文件API对齐规范化。并且要再次验证规范化后的路径是符合预期的基准路径的要求。
下面是Java的一段例子:
File file = new File(BASE_DIRECTORY, userInput);
if (file.getCanonicalPath().startsWith(BASE_DIRECTORY)) {
// process file
}
如果是JS的话,可以先用path.resolve进行规范化,然后再判断是否符合基准目录要求:
var path = require("path")
if (path.resolve(BASE_DIRECTORY, userInput).startsWith(BASE_DIRECTORY)) {
// process file
}
参考
https://portswigger.net/web-security/file-path-traversal