网站数据分析视频/沈阳关键词seo排名
目录
1. 论文精读
1.1 什么是EDA
1.2 注意点
1.3 结论
2. 实验
2.1 说明
2.2 实验
3. 完整代码
参考
1. 论文精读
1.1 什么是EDA
EDA(Easy Data Augmentation):为NLP提供了一套简单的通用数据增强技术,即4个simple but powerful操作:
对于训练集中一个给定的句子,我们随机选择执行下面的操作之一:(SR)synonym replacement(同义词替换):随机选择句子中不是停用词的个词,对每个词都使用其同义词(随机选择)替换;
(RI)random insertion:随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。做次;
(RS)random swap:在句子中随机选择2个词,交换他们的位置。做次;(RD)random deletion:对句子中每个词以的概率移除
1.2 注意点
1.2.1 关于n的取值
长文本拥有的词比短文本更多,相应的其可进行更多的操作。n值的取值与文本长度有关,设置一个增强因子α(augmentation parameter),对于在SR、RI、RD操作,,而对于RD操作,。其中l表示句子长度,α一个句子中会发生change的比例。
1.2.2 一个文本产生几个增强?
1.2.1中n的意思是一个句子在选定某种方式增强时要进行的n次操作。而此时讨论的是一个句子要生成几个增强句子合适,假设用表示,论文中通过实验表明:对于smaller training sets,过拟合能可能发生,所以产生更多的增强句子将获得更大的性能提升,即更适合小数据集。并且基于实验,作者更加推荐使用的参数如下表所示: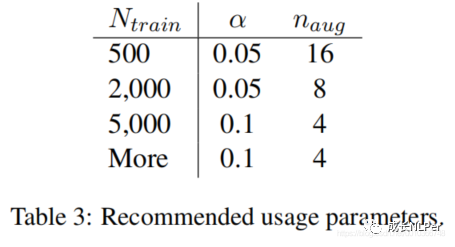
1.2.3 注意和限制
- (1)EDA的实现
非常简单! - (2)适合
小数据集!当数据充足时,性能提升可能很小,帮助不大; - (3)尽管对于小型数据集,性能提升似乎很明显,但使用
预训练的模型时,EDA可能无法带来实质性的改进; - (4)EDA是否可能降低性能?如果EDA改变了句子的意思,却还使用original label,就会带来错误;
- (5)EDA的理论支撑,他是如何提升性能的?
- The fifirst is that generating augmented data similar to original data introduces some degree of noise that helps prevent overfifitting.(生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合)
- The second is that using EDA can introduce new vocabulary through the synonym replacement and random insertion operations, allowing models to generalize to words in the test set that were not in the training set.(使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词)
- (6)随机插入时只考虑同义词,为了与上下文相关,并保证原句子的意思不被破坏;
- (7)随机交换、插入、删除,看上去不太直观,但其实相当于引入了一些噪声,这有助于避免过拟合。
1.3 结论
尽管有时提升很小,但是当在小型数据集上训练时,EDA却能带来显著的性能提升和减缓过拟合。
2. 实验
2.1 说明
- EDA代码使用了这里的实现:
https://github.com/zhanlaoban/eda_nlp_for_Chinese - EDA的实现里有用的synonyms的python包,需要提前安装,它主要用来获得一个词的同义词,其安装和使用示例如下:
>>> import synonyms
smart_open library not found; falling back to local-filesystem-only
[jieba] default dict file path ../data/vocab.txt
[jieba] load default dict ../data/vocab.txt ...
>> Synonyms load wordseg dict [/usr/local/lib/python3.6/dist-packages/synonyms/data/vocab.txt] ...
>> Synonyms on loading stopwords [/usr/local/lib/python3.6/dist-packages/synonyms/data/stopwords.txt] ...
[Synonyms] on loading vectors [/usr/local/lib/python3.6/dist-packages/synonyms/data/words.vector.gz] ...
[Synonyms] downloading data from https://static-public.chatopera.com/ml/synonyms/words.vector.gz to /usr/local/lib/python3.6/dist-packages/synonyms/data/words.vector.gz ...
this only happens if SYNONYMS_WORD2VEC_BIN_URL_ZH_CN is not present and Synonyms initialization for the first time.
It would take minutes that depends on network.
100% [......................................................................] 165919480 / 165919480
[Synonyms] downloaded.
>>> import synonyms
>>> synonyms.nearby('优秀')
(['优秀', '杰出', '优良', '优异', '顶尖', '卓越', '专业', '出类拔萃', '优等', '优秀青年'], [1.0, 0.8171804, 0.685466, 0.6666226, 0.6444203, 0.6397628, 0.62672746, 0.6115825])
>>>
第一次import 该包时,会下载一些词表、词向量等文件,会花费一点时间。
- 我的数据集介绍:是一个6分类,6分类具体含义这里就不说明了,6类数据均是网上爬取,各类别
数据极度不均衡,而且数据量非常少,训练集才340多条,适合使用eda做增强。原始数据样本的类别分布如下: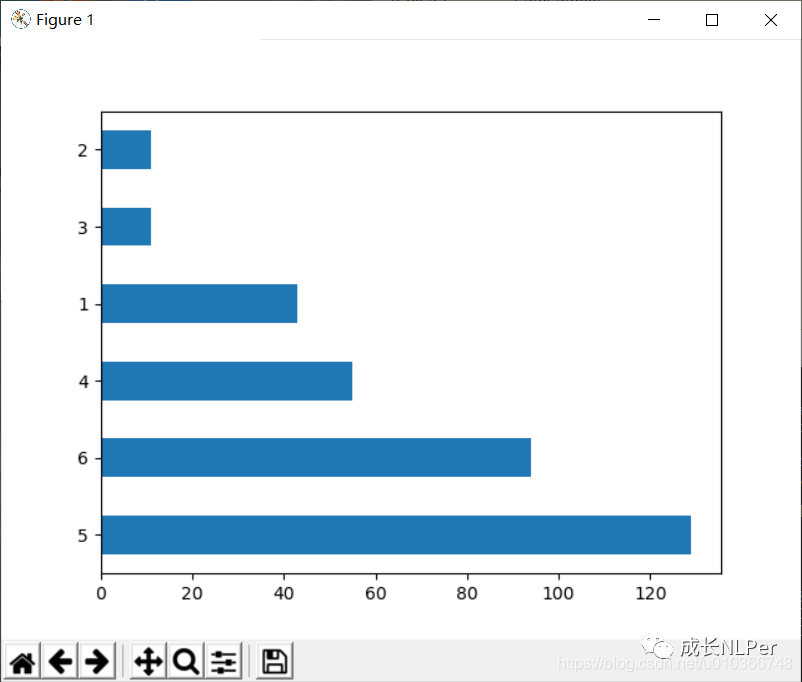
数据集有3列,使用pandas读取,label列是文本类别标记,clear_content是在最原始爬取的数据上做了清洗了,去除了非常用的标点以及其他特殊符号,content_seg是在clear_content上进一步做了分词。此次实验主要使用了label和content_seg列。
- 实验中会使用
fasttext在原始数据集和增强后的数据集上分别训练,最后给出结果对比。
2.2 实验
2.2.1 无增强
在训练集的结果: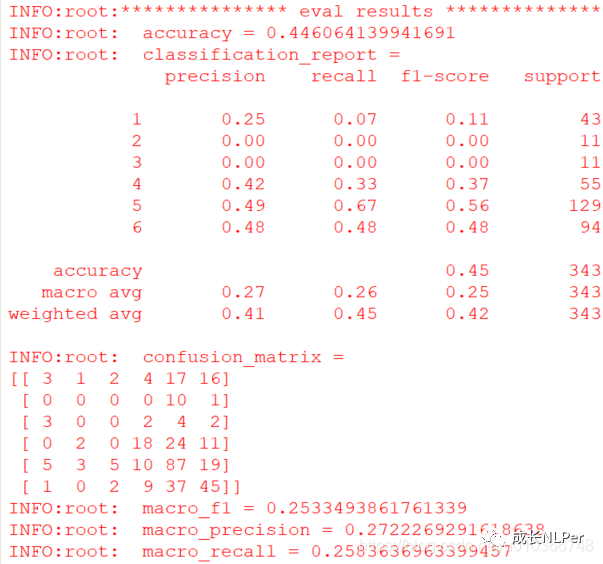 在测试集的结果:
在测试集的结果: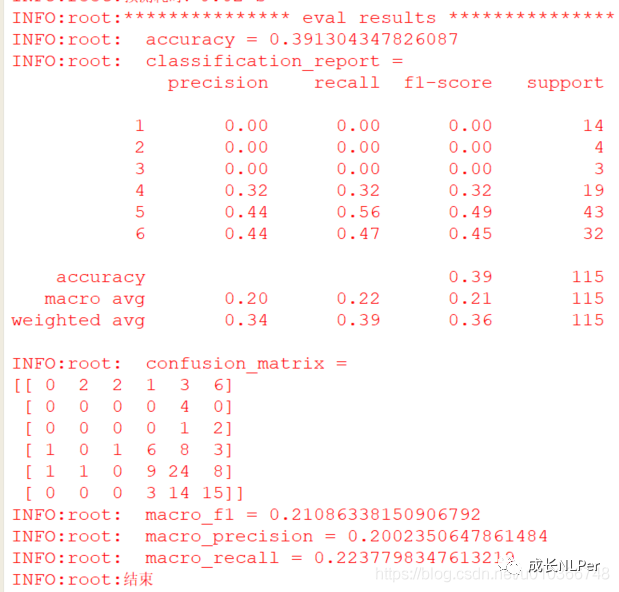 显然在数据量又小,样本量又极度不均衡的情况下,模型几乎学不到有用的东西,那么接下来就看看在进行了eda增强后的数据集上,模型是否有提升。
显然在数据量又小,样本量又极度不均衡的情况下,模型几乎学不到有用的东西,那么接下来就看看在进行了eda增强后的数据集上,模型是否有提升。
2.2.2 eda增强
先看看增强后的各类别数据分布: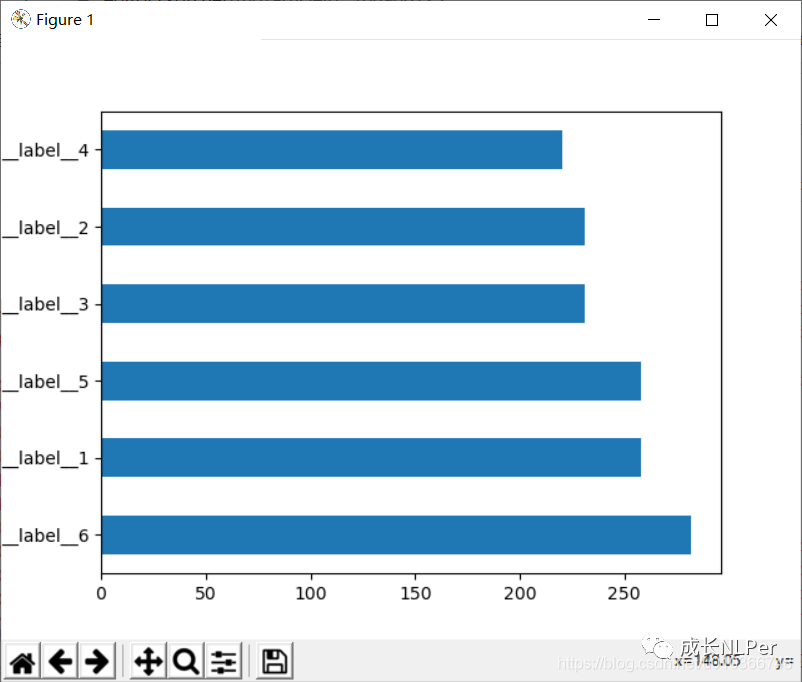 可以看到各类别数据量相差不大。
可以看到各类别数据量相差不大。
在训练集的结果: 在测试集的结果:
在测试集的结果: 从
从混下矩阵来看,进行增强后,分类性能有显著提升,f1值从原先的0.21提升到0.80,在增强后的数据上看,模型有些许的过拟合,但总体生来看,模型比无数据增强时,已经有了质的飞跃。
关于fasttext的模型参数的选择,我使用的是网格搜索+交叉验证,下一篇我会讲述是如何实现的。
3. 完整代码
完整代码请移步至: 我的github(https://github.com/qingyujean/eda-for-text-classification),求赞求星求鼓励~~~
最后:如果本文中出现任何错误,请您一定要帮忙指正,感激~
参考
[1] eda 论文(https://arxiv.org/abs/1901.11196)
[2] eda在中文语料的实现(github)(https://github.com/zhanlaoban/eda_nlp_for_Chinese)