网站建设分析从哪几个方面/电商培训机构排名前十

1.分布分析
分布分析研究数据的分布特征和分布类型,分定量数据、定性数据区分基本统计量。是比较常用的数据分析方法,也可以比较快的找到数据规律。对数据有清晰的结构认识。
数据的 分布 ( distribution ),描述了各个值出现的频繁程度。
表示分布最常用的方法是 直方图 ( histogram ),这种图用于展示各个值出现的频数或概率。频数 指的是数据集中一个值出现的次数。概率 就是频数除以样本数量n。频数除以n即可把频数转换成概率,这称为 归一化 ( normalization )。归一化之后的直方图称为 PMF ( Probability Mass Function ,概率质量函数),这个函数是值到其概率的映射。
2.术语
• 区间 ( bin )
将相近数值进行分组的范围。
• 条件概率 ( conditional probability )
某些条件成立的情况下计算出的概率。
• 分布 ( distribution )
对样本中的各个值及其频数或概率的总结。
• 频数 ( frequency )
样本中某个值的出现次数。
• 直方图 ( histogram )
从值到频数的映射,或者表示这种映射关系的图形。
• 归一化 ( normalization )
将频数除以样本数量得到概率的过程。
• 异常值 ( outlier )
远离集中趋势的值。
• 概率 ( probability )
频数除以样本数量即得到概率。
• 概率质量函数 ( Probability Mass Function , PMF )
以函数的形式表示分布,该函数将值映射到概率。
• 相对风险 ( relative risk )
两个概率的比值,通常用于衡量两个分布的差异。
• 分散 ( spread )
样本或总体的特征,直观来说就是数据的变动有多大。
• 修剪 ( trim )
删除数据集中的异常值。
3.案例详解
使用某地二手房数据做分布分析,字段包括‘房屋编码’,‘小区’,‘朝向’,‘房屋单价’,‘参考首付’,‘参考总价’,‘经度’,‘维度’。本节做入门章节,数据不足,暂时不做详细完整的分析解释。只求分布分析的相关内容,包括极差 、频率分布情况 、分组组距及组数等。
import 
#求极差 '参考首付'、'参考总价'
# 创建函数求极差
def d_range(df,*cols):krange = []for col in cols:crange = df[col].max() - df[col].min()krange.append(crange)return(krange)# 求出数据对应列的极差
key1 = '参考首付'
key2 = '参考总价'
dr = d_range(data,key1,key2)
print('%s极差为 %f n%s极差为 %f' % (key1, dr[0], key2, dr[1]))参考首付极差为 52.500000
参考总价极差为 175.000000
针对同一指标,极差越大,数据越不稳定
#参考总价的直方图
data[key2].plot(kind = 'hist',bins = 10,histtype = 'step',color = 'b')
plt.grid(linestyle = '-.')
# 简单查看数据分布,确定分布组数 → 一般8-16即可
# 这里以10组为参考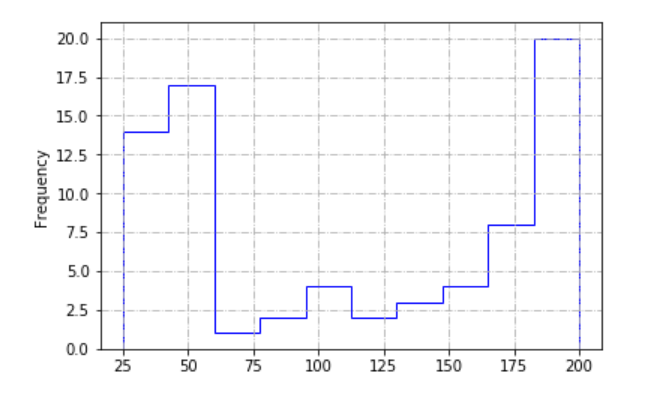
# 频率分布情况 - 定量字段
# 参考总价 求出分组区间
# pd.cut(x, bins, right):按照组数对x分组,且返回一个和x同样长度的分组dataframe,right → 是否右边包含,默认True
# 给源数据data添加“分组区间”列
gcut = pd.cut(data[key2],10,right= False)
gcut_count = gcut.value_counts(sort = False)
data['%s分组区间'%key2] = gcut.values
data.head()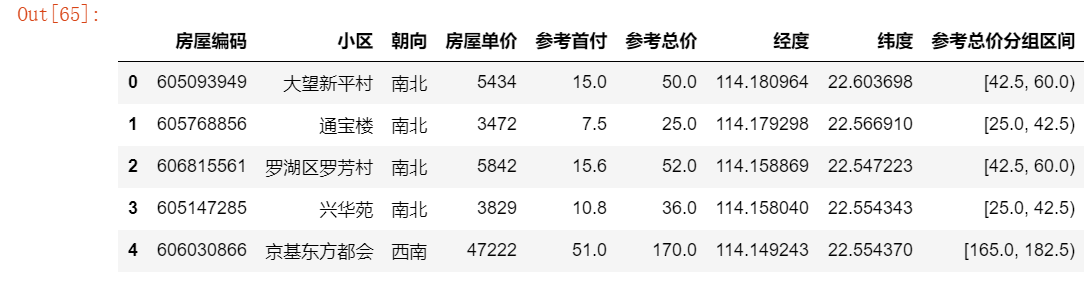
#区间出现频率
r = pd.DataFrame(gcut_count)
r.rename(columns = {gcut_count.name:'频数'},inplace = True)
r['频率'] = r['频数']/r['频数'].sum()
r['累计频率'] = r['频率'].cumsum()
r['频率%'] = r['频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示频率
r['累计频率%'] = r['累计频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示累计频率
r.style.bar(subset=['频率','累计频率'], color='green',width=100)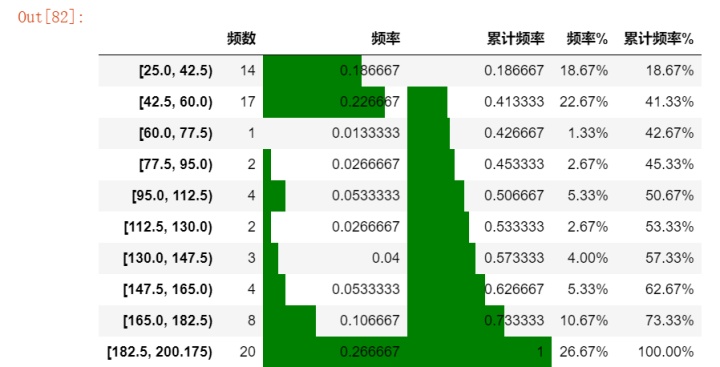
# 频率分布情况 - 定量字段
# ④ 绘制频率直方图r['频率'].plot(kind = 'bar',width = 0.8,figsize = (15,2),rot = 0,color = 'k',grid = True,alpha = 0.5)# 绘制直方图x = len(r)
y = r['频率']
m = r['频数']
for i,j,k in zip(range(x),y,m):plt.text(i-0.1,j+0.01,'%i' % k, color = 'k')
# 添加频数标签
# 频率分布情况 - 定性字段
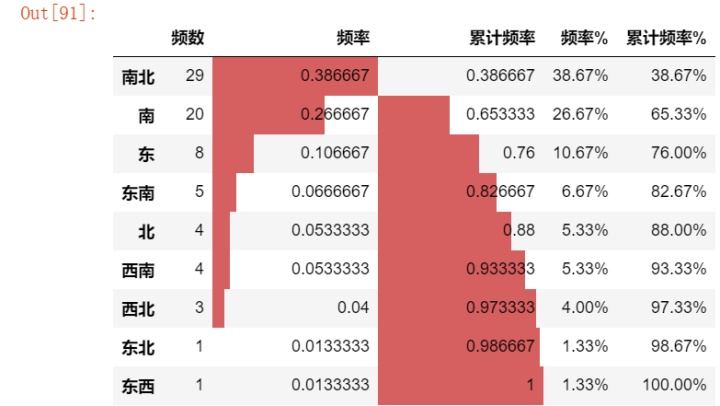
# ① 通过计数统计判断不同类别的频率cx_g = data['朝向'].value_counts(sort=True)
print(cx_g)
# 统计频率r_cx = pd.DataFrame(cx_g)
r_cx.rename(columns ={cx_g.name:'频数'}, inplace = True) # 修改频数字段名
r_cx['频率'] = r_cx / r_cx['频数'].sum() # 计算频率
r_cx['累计频率'] = r_cx['频率'].cumsum() # 计算累计频率
r_cx['频率%'] = r_cx['频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示频率
r_cx['累计频率%'] = r_cx['累计频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示累计频率
r_cx.style.bar(subset=['频率','累计频率'], color='#d65f5f',width=100)
# 可视化显示