惠州网站建设推广/现在百度怎么优化排名
一、数据加载和处理教程
在解决机器学习问题时, 我们需要付出很多努力来准备数据, 为了使代码更具可读性, PyTorch提供了许多工具来使数据加载变得简单易行。在本教程中, 我们将要学习如何对 一个重要的数据集进行加载、预处理数据增强。
为了运行这个教程,请确认下列包已安装:
scikit-image :用来读取图片和图像变换
pandas: 更方便地解析csv文件
from __future__ import print_function,divisionimport osimport torchimport pandas as pdfrom skimage import io,transformimport numpy as npimport matplotlib.pyplot as pltfrom torch.utils.data import Dataset,DataLoaderfrom torchvision import transforms,utils# 忽略警告import warningswarnings.filterwarnings('ignore')#开启交换模式plt.ion()我们将要处理的数据是人脸姿态。这就是对人脸的表示如下:

每张人脸图像上, 总共有68个不同的标注点被标记出来。
提示
打开http://t.cn/EaOQdfy 下载数据集, 这些图像在目录 'faces/'下. 这个数据集实际上是从imagenet数据集中选取标记为人脸的一些图片, 使用'dlib’s pose estimation 方法生成的.
### 下载图片数据 import osimport os.pathimport errnourl ='https://download.pytorch.org/tutorial/faces.zip'filename='faces.zip' def download(root): ''' 下载数据人脸图像和标注点的压缩包。 使用zipfile包解压。 ''' root = os.path.expanduser(root) import zipfile #下载图片压缩包到指定路径 download_url(url,root,filename) print("数据下载完毕!") #获得当前路径 cwd = os.getcwd() path = os.path.join(root, filename) tar = zipfile.ZipFile(path, "r") #解压文件 tar.extractall(root) tar.close() #切换到当前工作路径 os.chdir(cwd) def download_url(url, root, filename): from six.moves import urllib root = os.path.expanduser(root) fpath = os.path.join(root, filename) try: os.makedirs(root) except OSError as e: if e.errno == errno.EEXIST: pass else: raise # downloads file if os.path.isfile(fpath) : print('使用已下载文件: ' + fpath) else: try: print('下载 ' + url + ' 到 ' + fpath) urllib.request.urlretrieve(url, fpath) except: if url[:5] == 'https': url = url.replace('https:', 'http:') print('下载失败。尝试将https -> http' ' 下载 ' + url + ' 到 ' + fpath) urllib.request.urlretrieve(url, fpath) download('./')
数据集中的csv文件记录着标注信息, 像下面这样:
image_name,part_0_x,part_0_y,part_1_x,part_1_y,part_2_x, ... ,part_67_x,part_67_y
0805personali01.jpg,27,83,27,98, ... 84,134
1084239450_e76e00b7e7.jpg,70,236,71,257, ... ,128,312
让我们快速地读取CSV文件, 以(N,2)的数组形式获得标记点, 其中N表示标记点的个数.
1. 读取标记点CSV文件,使用pandas的read_csv方法。
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')2. 观察数据的结构,可以使用head\info等方法,head()默认返回前5行,info()显示数据名称和数量。
landmarks_frame.info()
landmarks_frame.head()
由上表可知,每行表示一张图片和标记点的X、Y坐标,共有68个标记点。
2. 已第4张图片为例。首先获得图片名称,其次获取所有标记点信息,首先转换成行向量(1×136),最后向量转换成N行2列的浮点型矩阵。
n = 3img_name = landmarks_frame.iloc[n, 0]landmarks = landmarks_frame.iloc[n, 1:].as_matrix()landmarks = landmarks.astype('float').reshape(-1, 2)print('Image name: {}'.format(img_name))print('Landmarks shape: {}'.format(landmarks.shape))print('First 4 Landmarks: {}'.format(landmarks[:4]))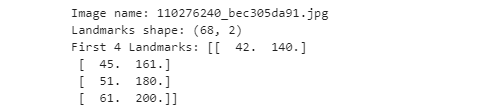
我们写一个函数来显示一张图片和它的标记点, 然后用这个函数来显示一个样本。
def show_landmarks(image, landmarks): """显示带标记点的图片""" plt.imshow(image) plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r') plt.pause(0.001) # 暂停一下, 使plots更新plt.figure()show_landmarks(io.imread(os.path.join('faces/', img_name)), landmarks)plt.show()
二、Dataset 类
orch.utils.data.Dataset 是一个表示数据集的抽象类。你自定义dataset类需继承Dataset并重写下列方法:
__ len __ 使用len(dataset)可以返回数据集的大小。
__ getitem __ 支持索引, 以便于使用 dataset[i] 可以 获取第i个样本。
让我们为landmars 数据集构建一个dataset类。我们将在__ init __ 中读取csv文件,在__ getitem __ 中读取图像。这可以高效利用内存,因为所有图像不会立即存储在内存中,而是根据需要读取。
我们的数据集样本将是一个dict {'image':image,'landmarks':landmarks}。我们的数据集将采用可选的参数变换,以便可以对样本应用任何所需的处理。我们将在下一节中看到变换的有用性。
class FaceLandmarksDataset(Dataset): ''' Face Landmarks Dataset ''' def __init__(self,csv_file,root_dir,transform=None): """ Args: csv_file (string): Path to the csv file with annotations. root_dir (string): Directory with all the images. transform (callable, optional): Optional transform to be applied on a sample. """ self.landmarks_frame = pd.read_csv(csv_file) self.root_dir = root_dir self.transform = transform def __len__(self): return len(self.landmarks_frame) def __getitem__(self,idx): #获得指定索引图片的路径 img_name = os.path.join(self.root_dir, self.landmarks_frame.iloc[idx,0]) #读取图片数据 image = io.imread(img_name) #将标注点数据转换成矩阵(行向量) landmarks = self.landmarks_frame.iloc[idx,1:].as_matrix() #将矩阵转换成N行2列的矩阵。 landmarks = landmarks.astype('float').reshape(-1,2) sample = {'image':image,'landmarks':landmarks} if self.transform: sample = self.transform(sample) return sample我们实例化这个数据集并迭代数据样本。我们将打印前4个样本并显示它们的标注点。
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv', root_dir='faces/')fig = plt.figure()for i in range(len(face_dataset)): sample = face_dataset[i] print(i, sample['image'].shape, sample['landmarks'].shape) ax = plt.subplot(1, 4, i + 1) plt.tight_layout() ax.set_title('Sample #{}'.format(i)) ax.axis('off') show_landmarks(**sample) if i == 3: plt.show() break
三、Transforms
我们从上面可以发现一个问题是样本的尺寸(指宽和高)不相同。大部分的神经网络都期望一个固定尺寸的图像。所以,我们需要写一些预处理的代码。
让我们写三个 transform:
Rescale: 缩放图像
RandomCrop: 从图像中随机裁剪。这是数据增加。
ToTensor: 将numpy形式的图像数据转换成torch形式的图像数据(我们需要交换轴)。
我们将它们编写为可调用类而不是简单函数,这样每次调用时都不需要传递 transform 的参数。所以,我们只需要实现 __ call __ 方法,同时如果需要,也可实现 __ init __ 方法。我们可以像这样使用 transform:
tsfm = Transform(params)
transform_sample = tsfm(sample)
请注意以下这些 transforms 必须如何应用于图像和landmarks。
class Rescale(object): ''' 将样本图像缩放至给定尺寸。 Args: output_size(tuple or int):期望的输出尺寸。如果是tuple, 则输出与output_size匹配。如果是int,则较小的图像边缘 与output_size匹配,保持纵横比相同。 ''' def __init__(self,output_size): assert isinstance(output_size,(int,tuple)) self.output_size = output_size def __call__(self,sample): image ,landmarks = sample['image'],sample['landmarks'] h , w = image.shape[:2] if isinstance(self.output_size, int): if h > w: # new_h/new_w = h/w ,new_w = output_size new_h , new_w = self.output_size * h / w , self.output_size else: # 与上面的相反 new_h , new_w = self.output_size, self.output_size * w / h else: # 直接以给定的数据为新的w、h new_h , new_w = self.output_size new_h , new_w = int(new_h) , int(new_w) #使用skimage包中tansform类的resize方法缩放图像。 img = transform.resize(image,(new_h,new_w)) # 将landmarks的位置按照图像的缩放比较,就行缩放。 landmarks = landmarks * [new_w / w, new_h / h] return {'image': img, 'landmarks': landmarks} import numpy as npclass RandomCrop(object): ''' 随机修剪样本图像。 Args: output_size(tuple or int):期望的输出尺寸。如果为int, 则进行方形裁剪。 ''' def __init__(self,output_size): assert isinstance(output_size, (int, tuple)) if isinstance(output_size, int): self.output_size = (output_size, output_size) else: assert len(output_size) == 2 self.output_size = output_size def __call__(self,sample): image, landmarks = sample['image'], sample['landmarks'] #获得图像的尺寸。 h, w = image.shape[:2] new_h, new_w = self.output_size top = np.random.randint(0, h - new_h) left = np.random.randint(0, w - new_w) image = image[top: top + new_h, left: left + new_w] landmarks = landmarks - [left, top] return {'image': image, 'landmarks': landmarks} class ToTensor(object): """Convert ndarrays in sample to Tensors.""" def __call__(self, sample): image, landmarks = sample['image'], sample['landmarks'] # 交换颜色的轴 # numpy image: H x W x C #轴对应编号:0,1,2 # torch image: C X H X W #轴对应编号:2,0,1 ''' transpose()的操作对象是矩阵。 我们用一个例子来说明这个函数: [[[0 1] [2 3]] [[4 5] [6 7]]] 这是一个shape为(2,2,2)的矩阵,现在对它进行transpose操作。 首先我们对矩阵的维度进行编号,上述矩阵有三个维度,则编号分别为0,1,2,而transpose函数的参数输 入就是基于这个编号的,如果我们调用transpose(0,1,2),那么矩阵将不发生变化,如果我们不输入参 数,直接调用transpose(),其效果就是将矩阵进行转置,起作用等价与transpose(2,1,0)。 在举个例子,对上面那个矩阵调用transpose(0,2,1) 下面为结果 [[[0 2] [1 3]] [[4 6] [5 7]]] 其实就是矩阵中每个元素按照一样的规则进行位置变换。 ''' image = image.transpose((2, 0, 1)) return {'image': torch.from_numpy(image), 'landmarks': torch.from_numpy(landmarks)}Compose transforms
现在,我们已经在样本上使用了 transforms。让我们看看,我们想将图像的短边缩短至256在随机从图像中裁剪一个224的方形。我们想组成Rescale 和RandomCrop的联合transforms。torchvision.transforms.Compose是一个允许我们做这些的简单可调用类。
scale = Rescale(256)crop = RandomCrop(100)composed = transforms.Compose([Rescale(256), RandomCrop(102)])# Apply each of the above transforms on sample.fig = plt.figure()sample = face_dataset[65]for i, tsfrm in enumerate([scale, crop, composed]): transformed_sample = tsfrm(sample) ax = plt.subplot(1, 3, i + 1) plt.tight_layout() ax.set_title(type(tsfrm).__name__) show_landmarks(**transformed_sample)plt.show()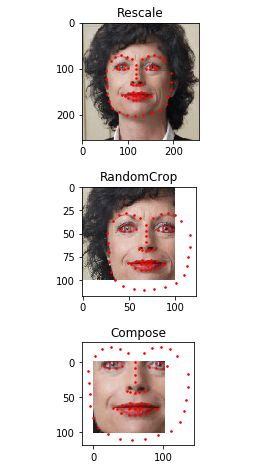
四、迭代数据
Iterating through the dataset
让我们把这些组合在一起创建一个包含组合转换器(composed transforms)的数据集(dataset)。
总而言之, 每次取样数据集时:
即时从文件中读取图像
变换应用于读取的图像
由于其中一个变换是随机的,因此在采样时会增加数据
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv', root_dir='faces/', transform =transforms.Compose([ Rescale(256), RandomCrop(204), ToTensor(), ]))for i in range(len(transformed_dataset)): sample = transformed_dataset[i] print(i,sample['image'].size(),sample['landmarks'].size()) if i == 3: break
然而,我们使用简单的for循环来迭代数据将会就丢失很多特性。事实上,我们错过了:
批处理数据
打乱(洗牌)数据
使用multiprocessing作业,并行加载数据。
torch.utils.data.DataLoader 是提供了所有特性的迭代器。下面使用的参数应该是清楚的。感兴趣的一个参数是collate_fn。您可以使用collate_fn指定需要批量处理样品的准确程度。但是,对于大多数用例,默认整理应该可以正常工作。
#定义数据加载器,数据需要打乱,每次取4个样本。#num_workers,我暂时无法理解。dataloader = DataLoader(transformed_dataset,batch_size=4, shuffle=True,num_workers=4)# 帮助类,展示一个批次的数据。def show_landmarks_batch(sample_batched): ''' 显示一个批次的图像。 ''' images_batch , landmarks_batch = \ sample_batched['image'],sample_batched['landmarks'] batch_size = len(sample_batched) im_size = images_batch.size(2) grid = utils.make_grid(images_batch) plt.imshow(grid.numpy().transpose((1,2,0))) for i in range(batch_size): plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size, landmarks_batch[i, :, 1].numpy(), s=10, marker='.', c='r') plt.title('Batch from dataloader') for i_batch,sample_batched in enumerate(dataloader): print(i_batch, sample_batched['image'].size(), sample_batched['landmarks'].size()) # observe 4th batch and stop. if i_batch == 3: plt.figure() show_landmarks_batch(sample_batched) plt.axis('off') plt.ioff() plt.show() break
后记:torchvision
在这个教程中, 我们学习了如何写和使用数据集, 图像变换和dataloder. torchvision 提供了常用的数据集和图像变换, 或许你甚至不必写自定义的类和变换. 在torchvision中一个最经常用的数据集是ImageFolder. 它要求数据按下面的形式存放:
/root/hymenoptera_data/ants/xxx.png
/root/hymenoptera_data/ants/xxy.jpeg
/root/hymenoptera_data/ants/xxz.png
.
.
.
/root/hymenoptera_data/bees/123.jpg
/root/hymenoptera_data/bees/nsdf3.png
/root/hymenoptera_data/bees/asd932_.png
‘ants’, ‘bees’ 等是图像的类标. 同样, PIL.Image 中出现的一般的图像变换像 RandomHorizontalFlip, Scale 也是可以使用的. 你可以像下面这样用这些函数来写dataloader:
import torchfrom torchvision import transforms, datasetsdata_transform = transforms.Compose([ transforms.RandomSizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])hymenoptera_dataset = datasets.ImageFolder(root='./root/hymenoptera_data/train', transform=data_transform)dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset, batch_size=4, shuffle=True, num_workers=4)α2" role="presentation" style=" line-height: 0; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; vertical-align: 0.513em; padding-right: 0.071em; display: block; white-space: pre; font-family: MJXc-TeX-main-R, MJXc-TeX-main-Rw; padding-top: 0.39em; padding-bottom: 0.335em; box-sizing: content-box !important; ">
⭐总结
α2" role="presentation" style=" line-height: 0; overflow-wrap: normal; word-spacing: normal; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border-width: 0px; border-style: initial; border-color: initial; vertical-align: 0.513em; padding-right: 0.071em; display: block; white-space: pre; font-family: MJXc-TeX-main-R, MJXc-TeX-main-Rw; padding-top: 0.39em; padding-bottom: 0.335em; box-sizing: content-box !important; ">
自定义dataset。首先需要继承torch.utils.data.Dataset 类;其次要实现__ len __ (使用len(dataset)可以返回数据集的大小)和__ getitem __ (支持索引, 以便于使用 dataset[i] 可以 获取第i个样本)方法。
自定义transform。首先要要继承object类;其次实现__ call __ 方法,需要时可实现 __ init __ 方法。

如果你也有想分享的干货,可以登录天池实验室(notebook),包括赛题的理解、数据分析及可视化、算法模型的分析以及一些核心的思路等内容。
小天会根据你分享内容的数量以及程度,给予丰富的神秘天池大礼以及粮票奖励。分享成功后你也可以通过下方钉钉群?主动联系我们的社区运营同学(钉钉号:yiwen1991)

天池宝贝们有任何问题,可在戳“留言”评论或加入钉钉群留言,小天会认真倾听每一个你的建议!![]()

点击下方图片即可阅读

如何使用sklearn优雅地进行数据挖掘?

为何推荐sklearn做单机特征工程?【下】

学会【超参数与模型验证】,大不了我请你吃辣条~

迁移学习教程(Transfer Learning tutorial)

