滨海新区网站建设/济宁百度推广电话
JAVA获取视频(TS类型)
在爬取视频的时候有的时候会碰到m3u8格式的视频,这种类型的视频是通过一个个片段进行播放。

1.这种视频(https://ifeng.com-v-ifeng.com/20180716/21960_f0f836f8/index.m3u8)直接去访问的时候会显示如下图所示文件。

2.所获得的内容中有“1000k/hls/index.m3u8”这样一行,发现这个正好是视频中第一个请求的地址,根据这个地址再访问(https://ifeng.com-v-ifeng.com/20180716/21960_f0f836f8/1000k/hls/index.m3u8),便可获得每个片段的地址,我们可以通过访问这些片段进行下载,最后合成视频。
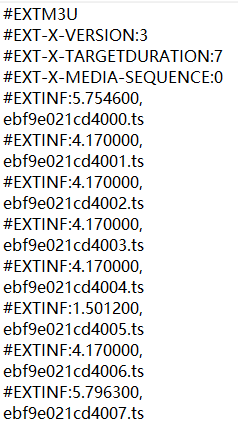
具体代码如下
package Test.Write;import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;/*** * 获取视频(MP4类型)* @author Zzh**/
public class CatchVideo2 {/** 视频名称*/private static String videoName;/** 视频前缀*/private static String videoPathPrefix;/** 设置日期格式*/private static SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");/*** 主程序* @param args*/public static void main(String[] args) {System.out.println(df.format(new Date()) + ":开始准备下载。");// 地址集List<String> downLoadUrls = new ArrayList<String>();// 视频的主页面String htmlmain = getHtml("http://www.yhdm.tv/show/1014.html");// 获取每集页面的地址List<String> urls = parseHtmlMain(htmlmain);String mainurl = "http://www.yhdm.tv";for (String url : urls) {// 每集真正播放地址String html = getHtml(mainurl + url);String downLoadUrl = parseHtml(html);downLoadUrls.add(downLoadUrl);}httpDownload(downLoadUrls);}/*** 获取网页html代码* @param 网址*/private static String getHtml(String path){System.out.println(df.format(new Date()) + ":获取" + path + "页面代码。");// 保存整个html文档的数据StringBuffer html = new StringBuffer();try {// 发起一个url网址的请求URL url = new URL(path);URLConnection connection = url.openConnection();// 获取网页的数据流InputStream input = connection.getInputStream(); InputStreamReader reader = new InputStreamReader(input, "UTF-8"); BufferedReader bufferedReader = new BufferedReader(reader); // 解析并且获取InputStream中具体的数据,并且输出到控制台String line = "";while((line = bufferedReader.readLine()) != null){// 将所有读到的每行信息line追加到(拼接到)html对象上html.append(line); }} catch (MalformedURLException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return html.toString();}/*** 获取集数* @param HTML内容* @return 视频地址*/private static List<String> parseHtmlMain(String html) {System.out.println(df.format(new Date()) + ":获取集数。");Document document = Jsoup.parse(html);// 获取id为main0的元素Element main = document.getElementById("main0");Elements urlLinks = main.getElementsByTag("a");List<String> urls = new ArrayList<String>();// 每集地址添加for (Element urlLink : urlLinks) {String name = urlLink.html();if (name.contains("CM") || name.contains("PV")) {continue;}urlLink.attr("href");urls.add(urlLink.attr("href"));}Elements videoNameH1= document.getElementsByTag("h1");// 视频名videoName = videoNameH1.get(0).text().replace(":", "").replace("/", "").replace("\\", "").replace("*", "").replace("?", "").replace("|", "").replace("<", "").replace(">", "");return urls;}/*** 解析HTML* @param HTML内容* @return 视频地址*/private static String parseHtml(String html) {Document document = Jsoup.parse(html);Element dplayer = document.getElementById("play_1");String videoUrl = dplayer.attr("onclick");videoUrl = videoUrl.replace("changeplay('", "");videoUrl = videoUrl.replace("$mp4');", "");return videoUrl;}/*** 下载视频* @param 视频地址集*/public static boolean httpDownload(List<String> httpUrls) {// 设置路径String saveFile = "D:\\视频\\" + videoName;String saveFileVideo = "D:\\视频\\" + videoName +"\\" + videoName;System.out.println(df.format(new Date()) + ":地址集获取完毕准备开始下载。");int i = 0;for (String httpUrl : httpUrls) {// 合成用MAPHashMap<Integer, String> keyFileMap = new HashMap<Integer, String>();// 下载索引文件String indexStr = getIndexFile(httpUrl);// 解析索引文件List<String> videoUrlsList = analysisIndex(indexStr);i++;int j = 0;for (String videoUrl : videoUrlsList) {try {j++;int byteRead;URL url;// 创建文件File file = new File(saveFile);if(!file.exists()){file.getParentFile().mkdir();file.mkdirs();}File fileVideo = new File(saveFileVideo);if(!fileVideo.exists()){fileVideo.getParentFile().mkdir();fileVideo.mkdirs();}try {url = new URL(videoPathPrefix + videoUrl);} catch (MalformedURLException e1) {e1.printStackTrace();continue;}try {// 写入文件String st_saveFilename = "";st_saveFilename= saveFile + "\\" + videoName + i + "_" + j + ".mp4";File file_saveFilename = new File(st_saveFilename);if(!file_saveFilename.exists()){// 获取链接URLConnection conn = url.openConnection();HttpURLConnection httpURLConnection = (HttpURLConnection)conn;httpURLConnection.setInstanceFollowRedirects(false);// 输入流InputStream inStream = httpURLConnection.getInputStream();FileOutputStream fs = new FileOutputStream(st_saveFilename);byte[] buffer = new byte[1024];while ((byteRead = inStream.read(buffer)) != -1) {fs.write(buffer, 0, byteRead);}inStream.close();fs.close();System.out.println(videoName + "第" + i + "集" + j + "片段下载好了");} else {System.out.println(videoName + "第" + i + "集" + j + "片段已存在");}keyFileMap.put(j - 1, st_saveFilename);} catch (FileNotFoundException e) {System.out.println(videoName + "第" + i + "集" + j + "片段不存在");} } catch (IOException e) {e.printStackTrace();System.out.println(videoName + "第" + i + "集" + j + "片段超时");} }// 合成视频片段composeFile(saveFileVideo + "\\" + videoName + i + ".mp4", keyFileMap);System.out.println(df.format(new Date()) + ":" + videoName + i + "集完成");}return true;}/*** 下载索引* @param content*/public static String getIndexFile(String urlpath){try{URL url = new URL(urlpath);//下在资源BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));String content = "" ;String line;String indexUrl = "";int i = 0;while ((line = in.readLine()) != null) {i++;content += line + "\n";if (i==2) {indexUrl = content;}}// 转换为获取到的索引文件地址urlpath = urlpath.replace("index.m3u8", "") + content.replace(indexUrl,"");// 获取视频链接目录videoPathPrefix= urlpath.replace("index.m3u8", "").replace("\n", "");// 获取索引URL url2 = new URL(urlpath);URLConnection conn2 = url2.openConnection();HttpURLConnection httpURLConnection2 = (HttpURLConnection)conn2;httpURLConnection2.setInstanceFollowRedirects(false);try {// 输入流BufferedReader in2 = new BufferedReader(new InputStreamReader(httpURLConnection2.getInputStream(), "UTF-8"));String content2 = "" ;String line2;while ((line2 = in2.readLine()) != null) {content2 += line2 + "\n";}in2.close();return content2;} catch (FileNotFoundException e) {System.out.println(videoName + "链接错误");} return content;}catch (Exception e){e.printStackTrace();}return null;}/*** 解析索引* @param content*/public static List<String> analysisIndex(String content){Pattern pattern = Pattern.compile(".*ts");Matcher ma = pattern.matcher(content);List<String> list = new ArrayList<String>();while(ma.find()){String s = ma.group();list.add(s);}return list;}/*** 视频片段合成* @param fileOutPath* @param keyFileMap*/public static void composeFile(String fileOutPath, HashMap<Integer,String> keyFileMap){try {FileOutputStream fileOutputStream = new FileOutputStream(new File(fileOutPath));byte[] bytes = new byte[1024];int length = 0;for(int i=0;i<keyFileMap.size();i++){String nodePath = keyFileMap.get(i);File file = new File(nodePath);if(!file.exists())continue;FileInputStream fis = new FileInputStream(file);while ((length = fis.read(bytes)) != -1) {fileOutputStream.write(bytes, 0, length);}}}catch (Exception e){System.out.println("视频合成失败");}}
}