专业群建设 网站/小广告网站
文章目录
- 1 Stacking原理
- 第一步:生成预测结果
- 第二步:整合预测结果
- 2 使用Python实现Stacking
- 第一步:生成预测结果
- 第二步:整合预测结果
- 借助sklearn实现stacking
- 3 各领域内的一些实际应用
在机器学习领域,算法的选择和参数的调整一直是让人头痛的难题。虽然有很多算法可以使用,但没有一种算法是万能的。随着技术的不断发展,出现了一些新的技术可以在算法选择和调整参数方面提供一些帮助。其中最流行的技术之一是Stacking。
Stacking是一种用于增强机器学习模型性能的技术。该技术通过结合不同算法的预测结果来生成最终的预测结果。这种方法能够帮助解决许多机器学习问题,特别是当单一算法不足以解决问题时。
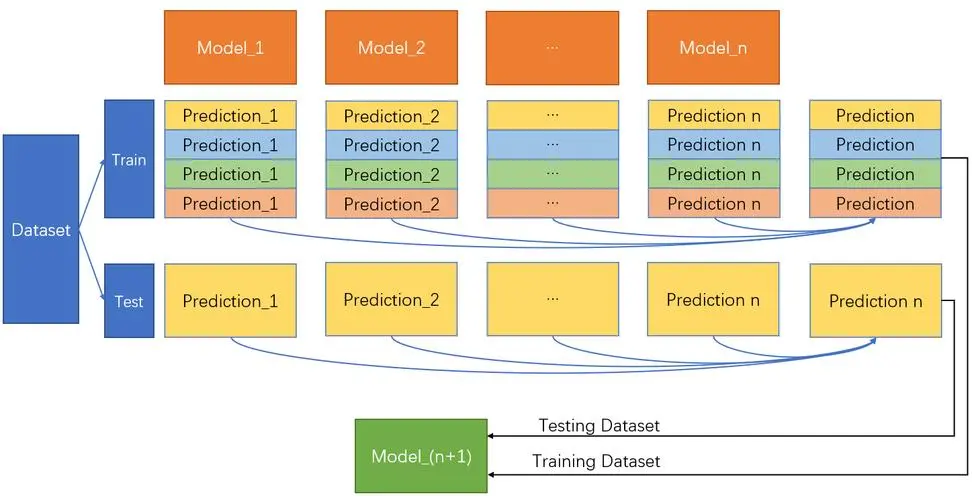
1 Stacking原理
在介绍如何使用代码实现Stacking之前,我们需要先了解一下Stacking的原理。
Stacking通常由两个步骤组成:第一步是使用多个基础模型来生成预测结果,第二步是使用另一个模型来整合这些预测结果,并生成最终的预测结果。
第一步:生成预测结果
在第一步中,我们使用多个基础模型来生成预测结果。对于每个基础模型,我们将训练数据拆分成两部分:一部分用于训练模型,另一部分用于生成预测结果。我们可以使用不同的模型,如线性回归、决策树、随机森林、支持向量机、神经网络等。每个模型生成一个预测结果。
第二步:整合预测结果
在第二步中,我们使用另一个模型来整合这些预测结果,并生成最终的预测结果。我们可以使用线性回归、逻辑回归、决策树、随机森林、支持向量机、神经网络等算法来完成这一步。
需要注意的是,第二步中的模型必须使用第一步中的预测结果作为输入。这样可以保证整个Stacking过程的连贯性。
2 使用Python实现Stacking
现在我们已经了解了Stacking的原理,接下来我们将介绍如何使用Python实现Stacking。
我们将使用一个简单的例子来说明如何使用Python实现Stacking。假设我们有一个数据集,其中包含5个特征和1个目标变量。我们将使用随机森林、支持向量机和神经网络作为基础模型,并使用线性回归作为元模型来整合预测结果
第一步:生成预测结果
我们首先需要将数据集拆分成训练集和测试集。训练集用于训练基础模型,测试集用于生成预测结果。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_splitdata = load_boston()
X, y = data.data, data.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来,我们定义3个基础模型:随机森林、支持向量机和神经网络,并训练它们。
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressorrf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)svm = SVR()
svm.fit(X_train, y_train)nn = MLPRegressor(hidden_layer_sizes=(100, 50), activation='relu', solver='adam', random_state=42)
nn.fit(X_train, y_train)
对于每个基础模型,我们使用测试集生成预测结果。
rf_pred = rf.predict(X_test)
svm_pred = svm.predict(X_test)
nn_pred = nn.predict(X_test)
第二步:整合预测结果
在第二步中,我们使用线性回归作为元模型来整合预测结果。需要注意的是,元模型必须使用第一步中的预测结果作为输入。
from sklearn.linear_model import LinearRegressionX_pred = np.column_stack((rf_pred, svm_pred, nn_pred))
meta_model = LinearRegression()
meta_model.fit(X_pred, y_test)
现在我们已经训练好了Stacking模型。我们可以使用训练好的模型来生成预测结果。
rf_pred_train = rf.predict(X_train)
svm_pred_train = svm.predict(X_train)
nn_pred_train = nn.predict(X_train)X_pred_train = np.column_stack((rf_pred_train, svm_pred_train, nn_pred_train))
y_pred_train = meta_model.predict(X_pred_train)X_pred_test = np.column_stack((rf_pred, svm_pred, nn_pred))
y_pred_test = meta_model.predict(X_pred_test)
现在我们已经生成了训练集和测试集的预测结果。我们可以使用这些预测结果来评估Stacking模型的性能。
from sklearn.metrics import mean_squared_errorprint('Training MSE:', mean_squared_error(y_train, y_pred_train))
print('Test MSE:', mean_squared_error(y_test, y_pred_test))
借助sklearn实现stacking
目前新版的sklearn中已经内置了StackingClassifier方法,大家可以直接调包使用。
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split# 生成一个分类数据集
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=0, random_state=42)# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义基本估计器
estimators = [('dt', DecisionTreeClassifier()), ('knn', KNeighborsClassifier()), ('svc', SVC())]# 定义元估计器
clf = RandomForestClassifier(n_estimators=10, random_state=42)# 定义Stacking分类器
stacking_clf = StackingClassifier(estimators=estimators, final_estimator=clf)# 训练Stacking分类器
stacking_clf.fit(X_train, y_train)# 评估Stacking分类器性能
score = stacking_clf.score(X_test, y_test)
print("Stacking分类器准确率:", score)
3 各领域内的一些实际应用
Stacking已经被广泛应用于各种领域,如金融、医疗、推荐系统等。在这些领域,Stacking已经成为了一个强有力的工具,能够提高预测准确性和稳定性。
例如,在金融领域中,Stacking已经被广泛应用于股票价格预测。股票价格预测是一个非常复杂的问题,需要考虑很多因素,如经济指标、政策变化、公司业绩等。利用Stacking,我们可以将多个基学习器的预测结果组合起来,以提高预测准确性和泛化能力。
在医疗领域中,Stacking已经被用于疾病预测和诊断。例如,使用Stacking算法可以将多个医学测试的结果组合起来,以提高疾病预测的准确性。此外,Stacking还可以帮助医生诊断疾病,比如通过将多个医学图像的结果组合起来,以帮助医生做出更准确的诊断。
在推荐系统中,Stacking已经被用于预测用户的兴趣和行为。推荐系统的主要目标是将用户与他们可能感兴趣的物品联系起来。利用Stacking,我们可以将多个基学习器的预测结果组合起来,以提高推荐的准确性和个性化。