vb2010做网站/抖音seo公司
商家操作日志的使命就是记录卖家对商品、订单等业务的操作。以便于后续分析。我们在做技术选型的时候确定了kafka+storm+elasticsearch,当前的架构如下:
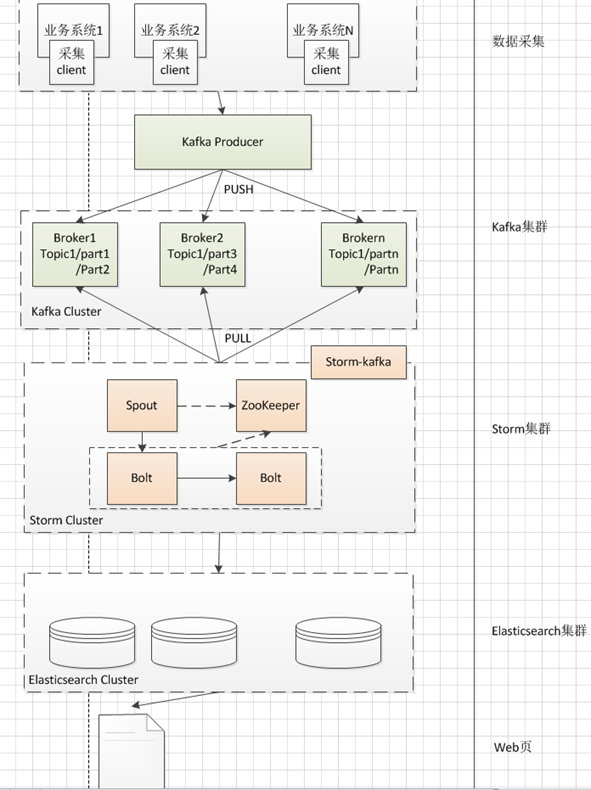
我们现在面临这样的问题,数据全部落到了ES上面,ES数据全部加载到内存里面之后,当前2个月的数量达到数十T之多。这个量对资源的需求非常大,而且我们的要求是同时要打开三个月的数据,因此远远达不到我们的要求。
![]()
我们以往是这样做的,每天一个索引,2个月之前的索引全部关掉。只保持一个月的索引打开。如果想查询以前的数据,就要先关掉当前的1个月,再打开要查看的那个月的索引。

ES集群,32个分片,32个副本(“1”-代表每个分片一个副本)
- "settings": {
- "index": {
- "number_of_shards": "32",
- "creation_date": "1475193606337",
- "number_of_replicas": "1",
- "version": {
- "created": "1070699"
- },
- "uuid": "JdEgO48dTTCWMAmMZ3oCXg"
- }
- },
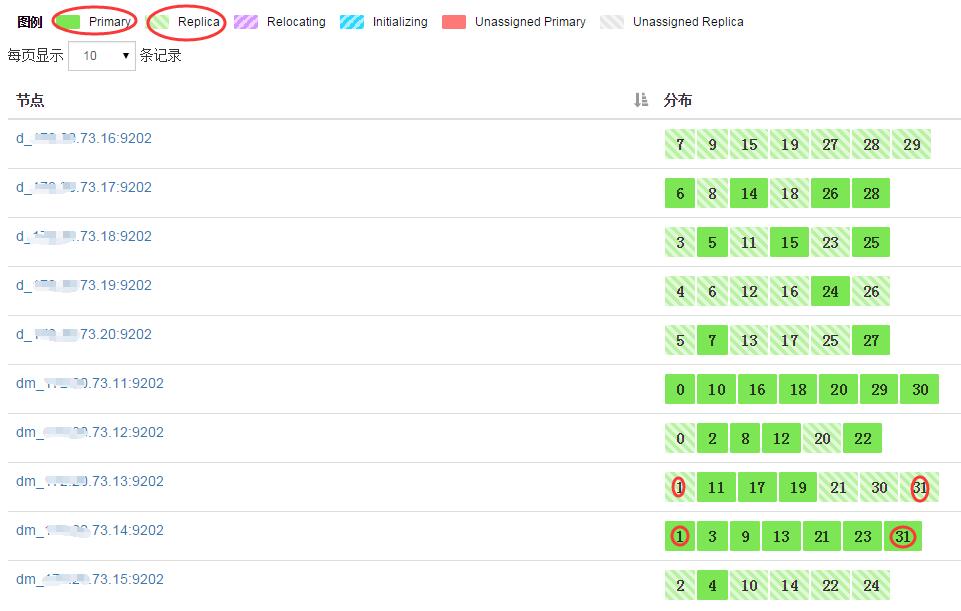
在这里再说明下,集群Index TPS,Search TPS与副本数的关系
集群写入文档TPS与副本数正相关,查询TPS与副本数无关。
举例:
1分钟向集群写入1000个文档:
当索引有0个副本:集群写入文档次数为1000,Index TPS为1000/60.
当索引有1个副本:集群写入文档次数为2000,Index TPS为2000/60.
当索引有2个副本:集群写入文档次数为3000,Index TPS为3000/60.
1分钟查询1000次:
当索引有0个副本:search TPS为 1000/60.
当索引有1个副本:search TPS为 1000/60.
当索引有2个副本:search TPS为 1000/60.
我们必须要调整我们的架构及存储方式。ES只用于热数据的分析,利用ES的检索特性。3个月以前的数据全部放入HBASE,利用HBASE的这种存储,对历史数据查询,只从HBASE里面查。更新后的存储处理方案下面这样
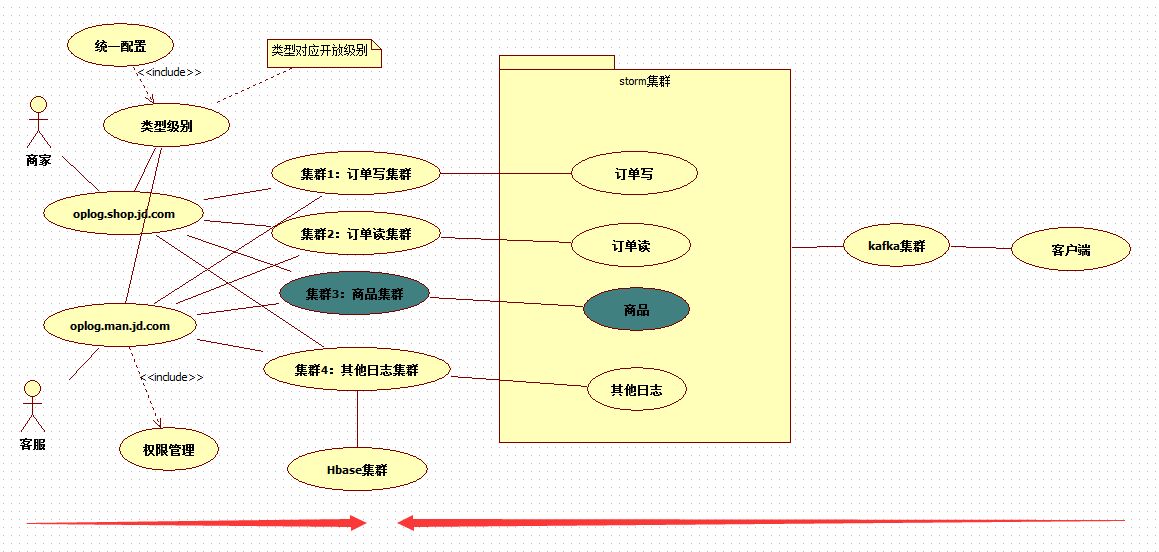
将日志分集群存储,日志量大的与日志量小的,互不影响。将来申请资源单独针对相应的日志集群来申请。这次调整从业务类别来拆分,继续保留了原来的kafka+storm+elasticsearch技术方案,因为日志处理在这个技术选型下是没有任何问题的,我们所要调整的是落地的细节上的问题。比如我们这次的存储方案调整。