给网站做推广一般花多少钱/全球十大搜索引擎
- 注:实现本文Python代码需要的包:opencv、numpy、matplotlib、sklearn、os,Python版本为Python3.7
- 为了使每段代码效果更直观,本文将会以类似jupyter notebook的形式,在部分代码后展示运行结果。
人脸情绪识别在日常生活中有着极其广泛的用途,例如智慧课堂应用场景中识别学生的面部表情从而给予老师关于课程的反馈、家用监控系统中识别儿童的异常情绪等等。
本文中的情绪识别技术基于JAFFE数据集实现,可以监测识别开心、悲伤、愤怒、厌恶、害怕、惊讶、中性这7种情绪,应用目标则是通过家用监控设备采集到的视频,实现自闭症儿童异常负面情绪的监测。
首先调用需要的包:
import 一、 基于图像特征提取和传统机器学习算法的情绪识别
0.人脸位置的检测
在进行人脸情绪识别时,首要任务就是抓取到图片中的目标人脸区域,再对人脸进行特征提取。在特征提取前,我们采用opencv包中自带的人脸检测文件进行目标区域的检测。将opencv包安装路径的cascades文件夹置于项目目录下,即可调用其中现有的模型。(cascades文件夹也会在本文末尾的GitHub中给出)
下面的detect函数展示了如何调用人脸检测的xml文件。
import 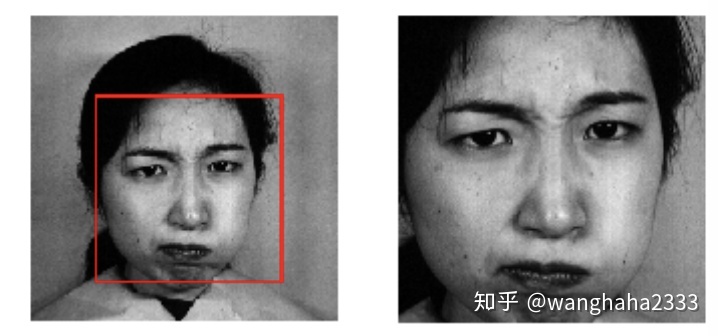
目标区域提取完毕,下面是重头戏——特征提取。
1.1 利用Gabor变换进行图像特征提取
数字图像处理中最常用的方法无疑是傅立叶变换,它将任意信号分解为许多不同频率正弦波的组合,可以实现信号在时域和频域的相互转换,但它最大的缺陷就是无法用于变化的非确定、非稳定信号。对于人脸图像这种非确定、非稳定信号,常用的一种特征提取方法是Gabor变换,它也被称为“窗口Fourier变换”。
Gabor变换的本质就是把信号划分成许多个小的间隔,再对每个小间隔进行傅立叶变换,从而兼顾信号在时域和频域的特性。对于二维情况下的图像,将小波变换与Gabor变换结合,得到的二维Gabor变换能够抓取图像中不同位置、不同频率、不同方向上的特征。换言之,二维Gabor变换在人脸图像中,可以较好地提取出人脸的眉毛、鼻子、嘴等面部关键区域的信息。
总而言之,Gabor滤波器是一种在图像处理领域极为优越的特征提取方法。
下面介绍Gabor变换的表达式。
二维Gabor变换的表达式如下所示:
其中各个参数的意义如下:
公式的后半部分用欧拉公式展开是一个正弦函数的形式,因此该公式实质上是一个高斯分布和一个正弦函数的乘积。
先从
如果
当椭圆率
话不多说,直接上代码,利用opencv包实现基于Gabor滤波器的特征提取。
首先是一个滤波器的图像展示:
#参数初始化
下面依次尝试增加ksize和
(注意,当
ksize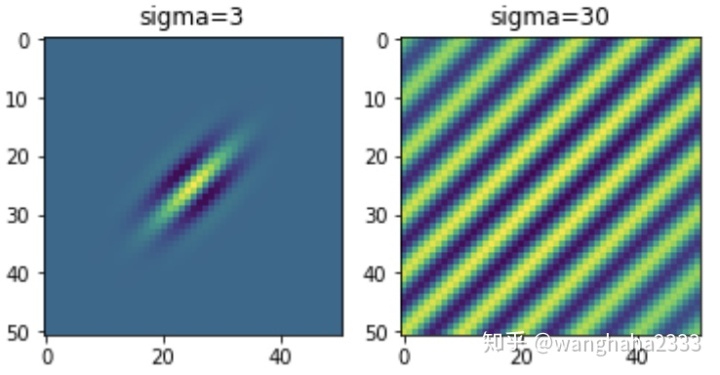
改变滤波器角度
ksize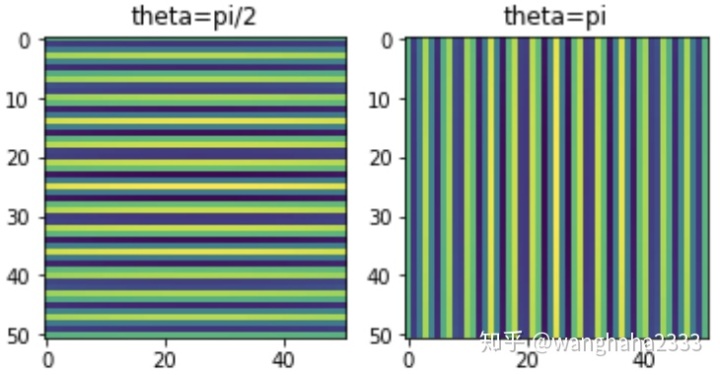
如果需要寻找图像垂直方向上的特征,则通过运用上图的垂直方向滤波器,可以阻止水平方向的所有特征。
改变波长的效果如下图:
ksize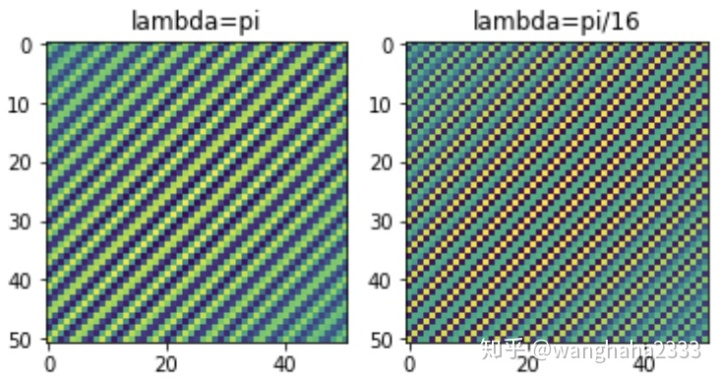
观察椭圆率
ksize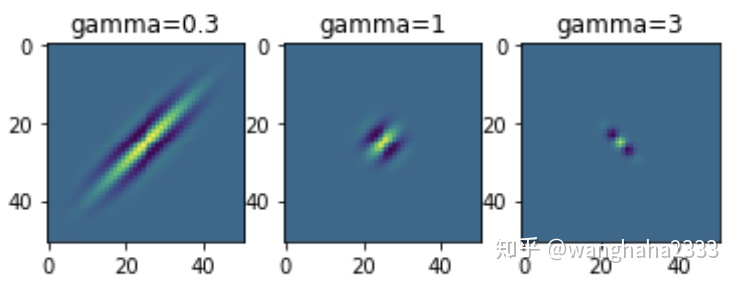
在人脸情绪识别的分类任务中,我们采用ksize=5的Gabor滤波器内核,在一张图片中的识别效果如下:
ksize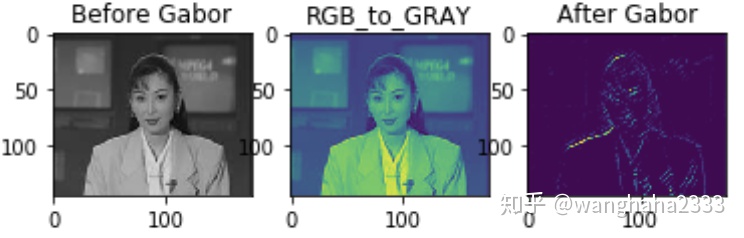
以下是本项目中采用的
sigma
上面图片与
img
经过Gabor滤波器,原图片生成了32张子图。将每张子图的大小变为100*100像素,再将每个像素点的像素值作为该子图的特征,从原图片中共得到
上述流程中提取的Gabor特征具有很好的识别性能,但它是非正交的,因此图像经过Gabor特征提取后,如果将每个像素点都作为特征,会导致特征维度较高和特征冗余。为此,采取下采样和PCA对上述特征向量进行降维。在下采样中,将图片的每个两两不相邻2*2区域像素值的最大值作为该区域的特征,可以将图像维度变为80000.
下面将基于JAFFE数据集的完整的Gabor特征提取代码应用于线性核函数的SVM分类器中:
(为实现人脸位置的捕捉,在代码所在目录仍然需要调用opencv安装路径中的cascade文件夹)
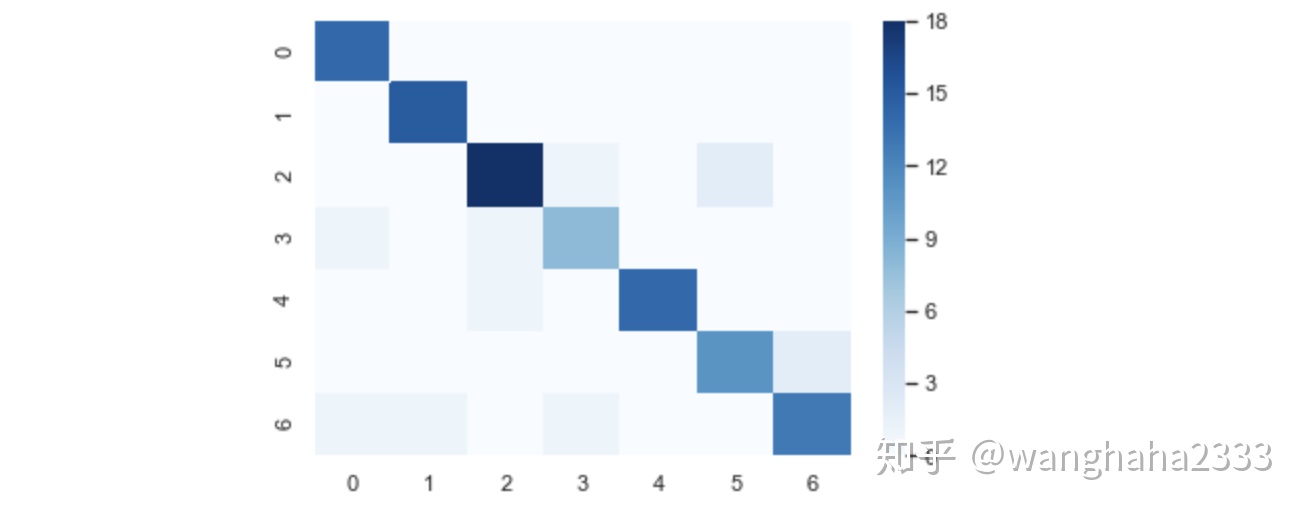
import 随机取70%的数据作为训练集,30%的数据作为测试集。这种特征提取方法最终在七种表情的分类上达到了85%的准确率,测试集分类的混淆矩阵也展示了较为良好的分类效果:
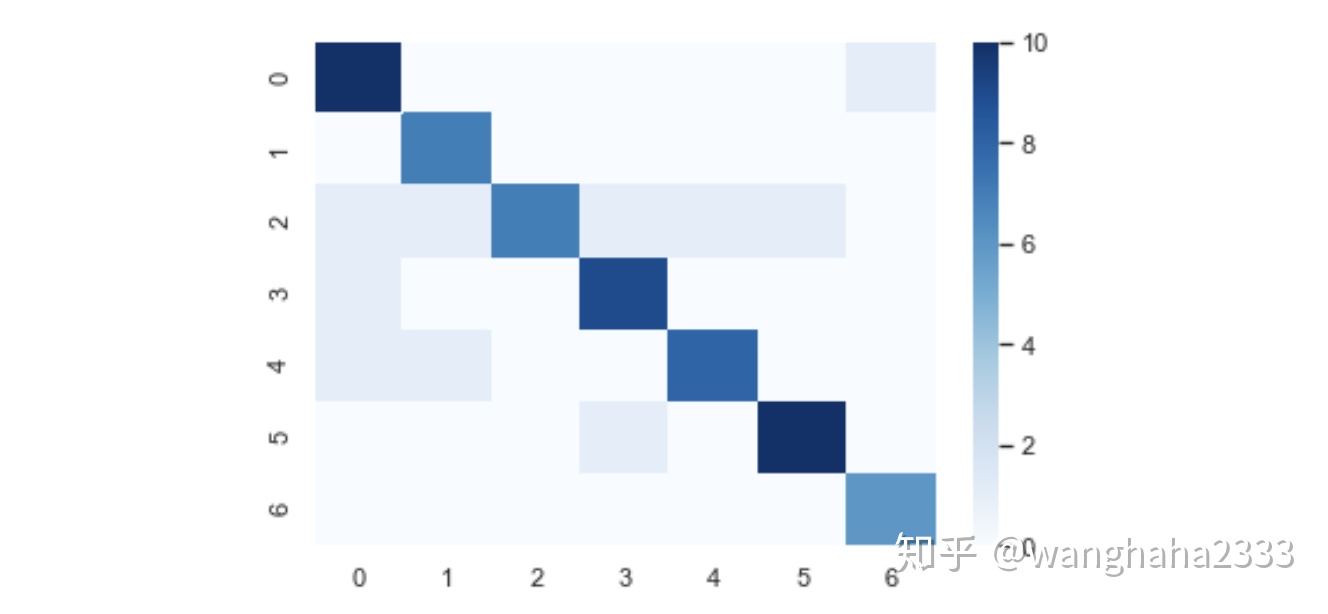
1.2 利用Gabor变换+HOG进行图像特征提取
在上述Gabor特征提取的过程中,我们直接以生成的子图中每个点的像素值作为整幅图像的特征值。为了进一步优化情绪识别的效果,考虑对每一个子图再做其他常见的图像特征提取。
HOG,又称作方向梯度直方图,相比其他常见的图像特征特征而言,HOG特征对图像几何和光学的形变都能保持很好的不变性,且它没有旋转和尺度不变性,因此计算量较小。
HOG特征提取主要分为以下几步:
(1)图像预处理
图像预处理分为图像灰度化和Gamma校正两步。
对于一个三维图像,HOG特征提取的过程中颜色信息的作用通常较小,因此将图像先转化为灰度图。
Gamma校正对输入图像进行颜色空间的标准化,将像素值转化为0-1之间的实数,从而调节图像的对比度,降低图像局部的阴影和光度变化对实验的影响,也可抑制噪声的干扰。
Gamma校正的公式(一般取
img
(2)计算每一个像素点的梯度值和方向
将图像中每一个像素点为中心的3*3像素方格与Sobel算子做卷积运算,得到某点(x,y)处梯度值和方向的计算公式如下:
其中
利用opencv可以写出上面几个公式:
height(3)每个cell的HOG特征的生成
将图像划分成许多cells(细胞单元),每10×10=100个像素作为一个cell,且相邻的cell之间没有重合部分。在每个cell中,将所有梯度方向放入划分的9个部分(如图,这9个部分由0-360度均分得到),作为直方图的横轴,且对于每个部分内的所有像素点,把它们的梯度值累加作为直方图的纵轴。这样生成的直方图对应着一个9维向量。
# HOG特征提取子函数--cell的梯度
(4)每2×2个cell合成大的可重叠的block
HOG特征提取前图像的大小归一化时,为了使图像能够被完全划分为10×10的cell(也就是划分后没有多余像素),预先将Gabor滤波后得到的子图归一化为100×100像素大小,从而这些图像可以被划分为10×10个10×10的cell。将左上角2×2方格的cell构成一个block,再将block每次向右、向下平移1个cell的步长,直到覆盖整张图像,如此生成了9×9个block。注意到相邻的block之间是有重叠的,这样通过更全面地分析各个相邻像素之间的共同特征,提高了算法的准确率。
hog_vector (5)生成特征向量
将一个block内所有的cell的特征向量合并为一个新的向量,再将每个block对应的特征向量归一化,得到该block的HOG特征。最后将每张图片中所有的block的特征向量合并为一个新的向量,得到图片的HOG特征向量。在本文中,特征向量的维度为$6×4×4×9=864$。其中$6×4$为block数量,4为每个block中cell的数量,9为每个cell的特征向量的维度,也就是将360度均分成的部分数。
每张训练集、测试集图片经过上述HOG特征提取的过程,都可以生成一个864维的特征向量用于训练和预测。上述HOG特征提取过程完整的代码如下:
cell_size 将上述代码用于Gabor特征提取产生的每一张子图,即可生成原图片的Gabor+HOG特征向量。Gabor+HOG特征提取的准确率要显著高于Gabor特征提取,准确率可以在jaffe数据集上达到89.4%。
1.3 人脸T型区域的特征提取
对于人脸的面部特征提取,另外一种方法是T型区域特征提取。T型区域,顾名思义,就是对人脸的眼部、眉毛、鼻子、嘴这几项特征较为显著的区域合并后产生的一个形状类似大写字母'T'的区域。在T型区域内的人脸部分更能反应整张人脸的特征,也能够降低数据的维度。但这种方法的缺陷也较为明显,它在应用场景中只能用于正脸的情形。
下面的代码将人脸的T型区域取出,并做HOG特征提取:
def 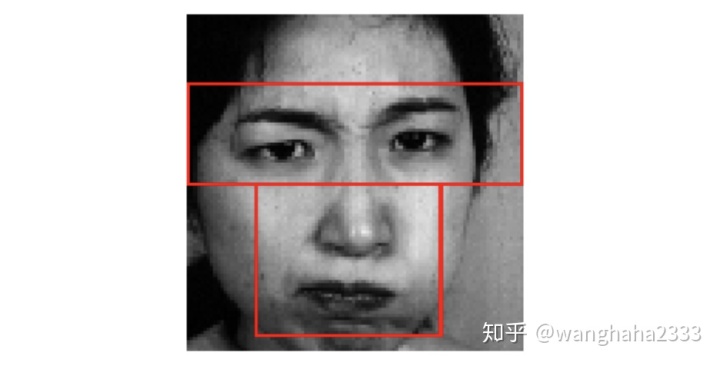
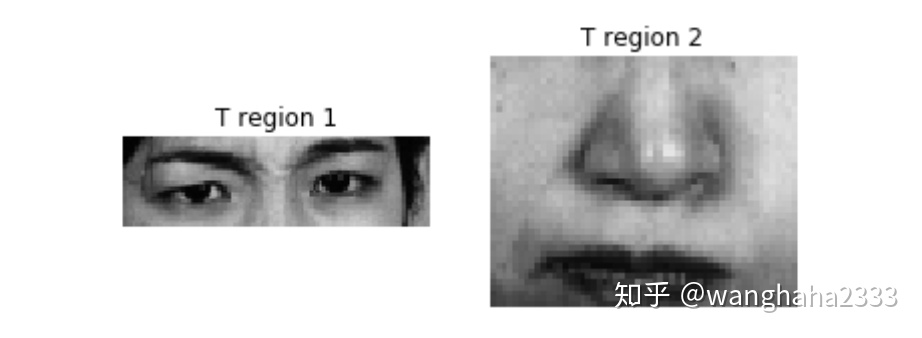
同理,也可以对T型区域单独做Gabor特征提取,结合1.1节中介绍的方法生成数据集。
2. 几种特征提取方法效果的对比
选用sklearn中提供的多种不同分类器进行测试,其中线性核函数SVM在多种特征提取方法产生的数据集上的识别准确率均为最高。不同特征提取的方法识别准确率测试如下:
考虑到实际应用场景中,部分需要检测的人脸未必为正脸,最终我们选用Gabor+HOG的特征提取方法。考察这种方法分类的精度、召回率和F1-Score:
结合上表,和上文Gabor+HOG的混淆矩阵进行分析可以看出,高兴和惊讶两种情绪的识别更准确,被误分为其他情绪的样本并不多;但是伤心表情较易被识别为中性表情,并且愤怒和厌恶的表情较易被混淆。究其原因,部分训练集的部分样本图片中伤心表情的特征并不明显,导致了易与中性混淆;愤怒和厌恶表情在某些样本上也表现出一定的相似性,导致了这两类之间的误分。考虑到在实际应用场景中,本项目的任务目标是从视频中监测自闭症儿童的负面情绪,因此为了提高分类准确率,我们在已有分类结果中将愤怒和厌恶合并为“厌烦”这一种情绪。
二、 基于深度学习的情绪识别
1.基于CNN的情绪识别
CNN的原理和优势大家都比较熟悉,这里就不再赘述了。
数据集选用JAFFE数据集[ https://zenodo.org/record/3451524#.X3xiNNozZPZ],先提取数据集图片的七种分类再保存其各自路径。
import 用cv2.imread()读取每一张图片,使用resize函数缩放图片成统一的(128*128)的图像,并append加入到img_data_list列表中,总共有213张图片,故所得列表大小为(213,128,128,3)。
2.基于ResNet的情绪识别
import 为图片数组写出一列类别标签,由于读取图片时是按照keys的分类顺序读的,故打标签也依据原分类各列表长度进行标记:
#先看一下每个类别有多少张图片
对标签进行独热编码,打乱数据集并分割训练集与测试集为0.85:0.15
#独热编码
CNN模型构建:此处自定义模型为两层卷积与池化层,一层全连接层。
第一层卷积层为32个(5*5)的卷积核,border_mode选择same,即自动补零padding,使得输出尺寸=输入尺寸/步幅。此处步幅选择默认为1。激活函数选用ReLu函数。池化层选择最大池化,池化核大小为(2,2)。
第二层卷积层为64个(5,5)的卷积核,其余同理。
第三层采用全连接层,现用flatten拉平再用Dense全连接层,num_classes设置为7,故使全连接层的输出数组为(N,7)的形式。
#定义CNN模型结构
输出模型结构如下:
model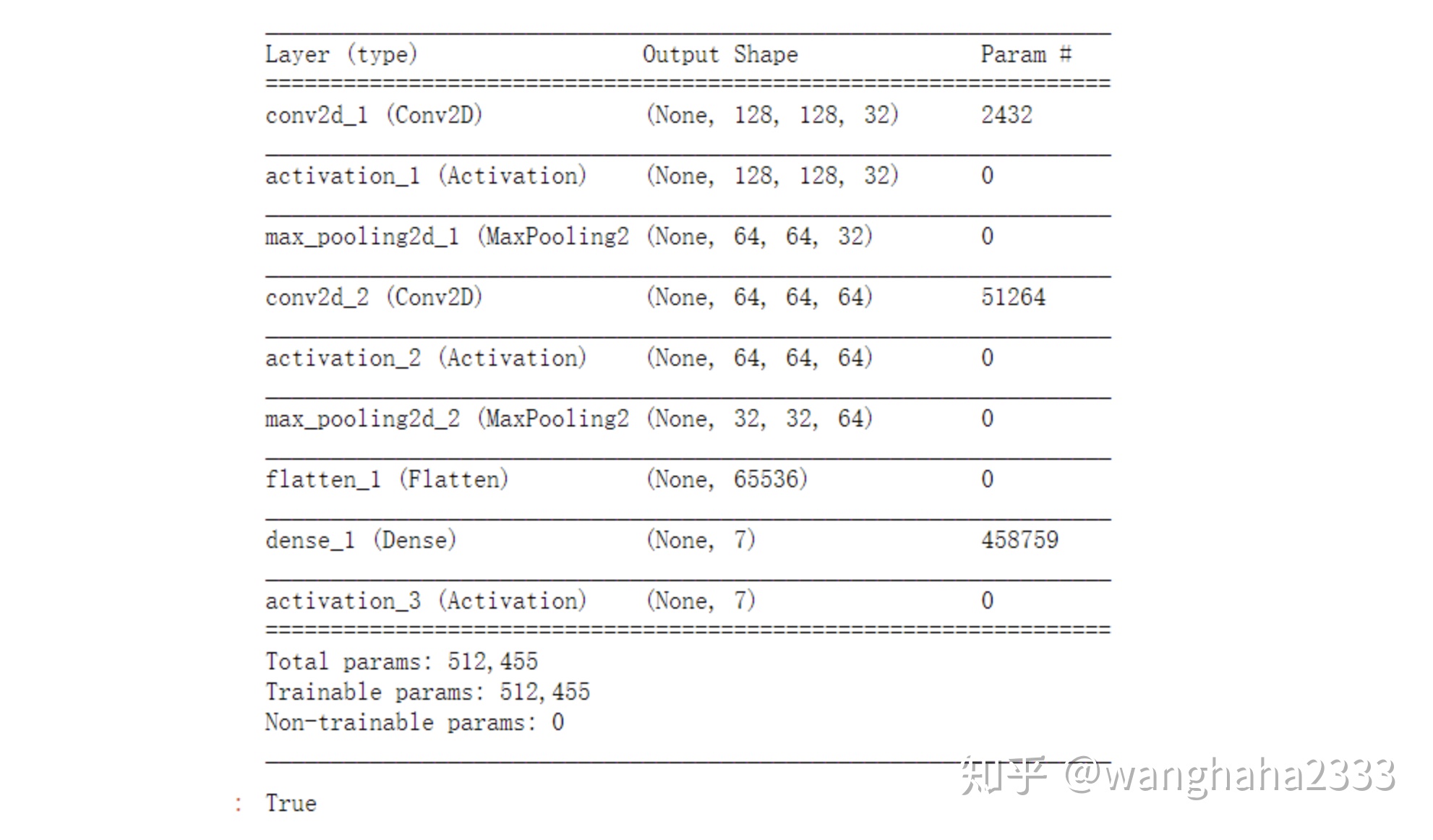
设置回调函数:
from 训练模型:
#训练

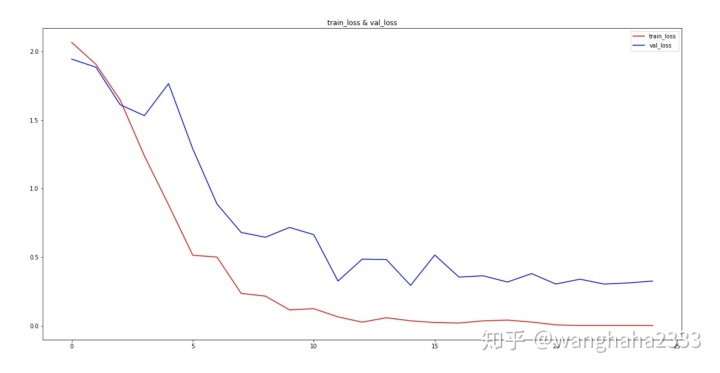
可视化训练过程中训练集与测试集的准确率与损失函数:
# visualizing losses and accuracy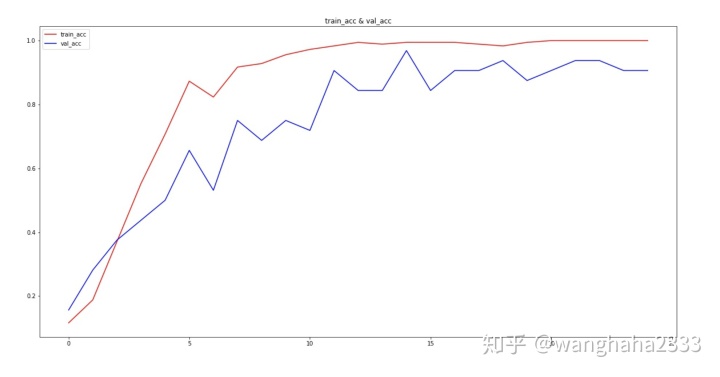
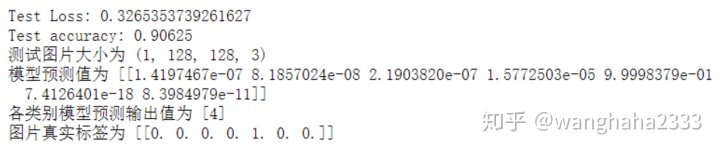
在测试集上抽样显示一张图片的真实值与模型的预测值
#用测试集评估模型
选取测试集前九张图片显示其预测值和真实图像:
res 
模型在测试集上的混淆矩阵如图所示:(标签值为列表keys =['FE', 'HA', 'NE', 'SA', 'SU', 'AN', 'DI']的元素索引,分别代表fear, happy, neutral, sad, surprise, angry, disgust)
import 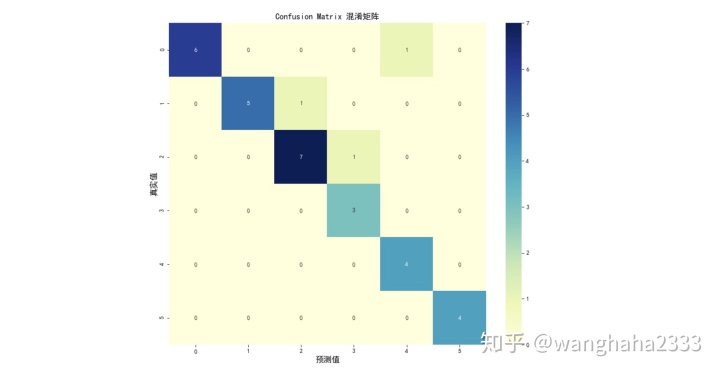
下面再使用现实生活中的图片来测试模型泛化效果。
先根据1.0,定义一个截取人脸的函数:
def 再输入一张图片进行测试:
testimg_data_list原图片为:

截取人脸后测试分类为:happy

2.基于残差神经网络ResNet的情绪识别
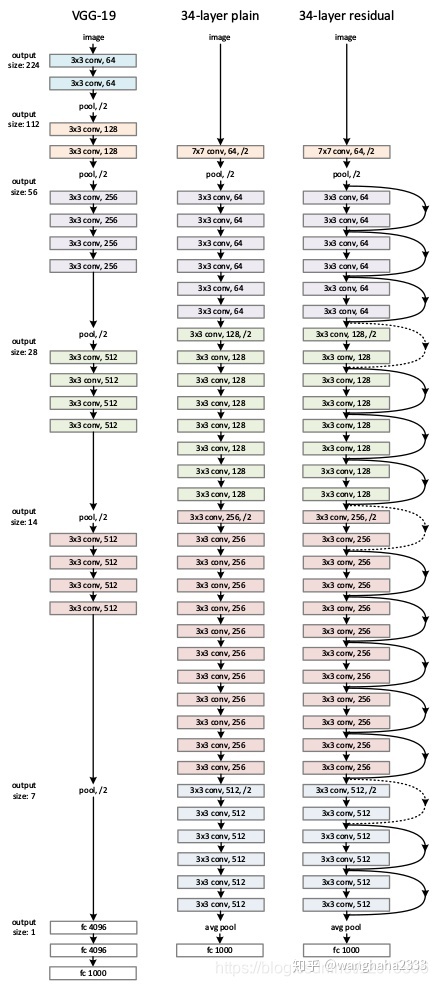
ResNet(Residual Neural Network)在传统卷积神经网络中加入残差学习(residual learning)的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,参数量比VGGNet低,既保证了精度,又控制了速度[https://blog.csdn.net/zzc15806/article/details/83540661]
VGG-19、无残差结构网络、ResNet-34的网络结构对比如下:
数据集选用Kaggle FER2013的人脸情绪识别竞赛数据集(该数据集中图片的质量较差,且存在大量侧脸表情),已经提前分好train set和test set,目录树如下:
导入包:
import 选择使用cpu还是gpu:
device 定义图片处理方式与数据增强方式:
#不做数据增强
分别读取训练集与测试集数据:
trainset 定义网络结构:
CLASSES 设定优化器和判断标准
criterion 定义训练函数:
def 训练模型并保存模型:
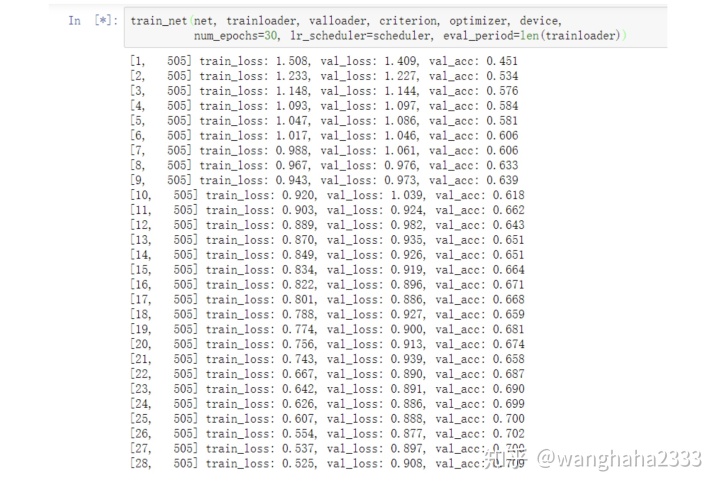
train_net训练到25轮时测试集准确率已经超过70%:
评估模型效果,显示模型结构:
net 


显示评估结果:
testset ResNet模型比CNN复杂许多,训练耗时为CNN的数倍。CNN在小数据集的情绪分类上表现很好,但大数据集上表现较差,不如ResNet。应根据数据集的大小选取合适的深度学习训练模型。